Writing a simple Compiler on my own - Abstract Syntax Tree Structure [C][Flex][Bison]
[Custom Thumbnail]
All the Code of the series can be found at the Github repository: https://github.com/drifter1/compiler
Introduction
Hello it's a me again @drifter1! Today we continue with my Compiler Series, a series where we implement a complete compiler for a simple C-like language by using the C-tools Flex and Bison. In this article we will get into how we implement an Abstract Syntax Tree (AST) as a Structure used in the Compiler.The topics that we will cover today are:
- Node, operator and value types
- The various AST node structures
- Some of the Node Management Functions (to get into the idea)
- Integrating the new code with the rest of the Compiler
Requirements:
Actually you need to read and understand all the topics that I covered in the series as a whole, as these articles will give you access to knowledge about:- What Compiler Design is (mainly the steps)
- For which exact Language the Compiler is build for (Tokens and Grammar)
- How to use Flex and Bison
- How to implement a lexer and parser for the language using those tools
- What the Symbol Table is and how we implement it
- How we combine Flex and Bison together
- How we can pass information from the Lexer to the Parser
- How we define operator priorities, precedencies and associativity
- What Semantic Analysis is (Attributes, SDT etc.)
- How we do the so called "Scope Resolution"
- How we declare types and check the type inter-compatibility for different cases, including function parameters
- How we check function calls later on using a "Revisit queue", as function declarations mostly happen after functions get used (in our Language)
- Intermediate Code Representations, including AST's
Difficulty:
Talking about the series in general this series can be rated:- Intermediate to Advanced
- Medium
Actual Tutorial Content
New code and header files
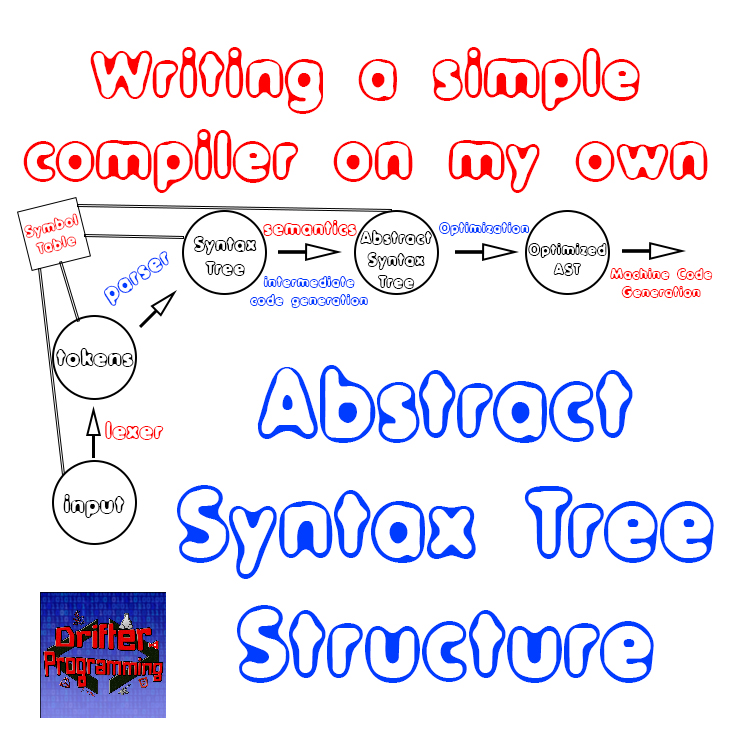
From this article on we expand our compiler to include a new structure, which is the Abstract Syntax Tree. Knowing that this structure is very important and that it's management functions will take up a lot of space, it's wise to make new code and header files, which have to do with anything related to that structure. That's why we now create a new header file "ast.h" and a new code file "ast.c".What these files have to contain
In these files we will have to define and implement a lot of things. Those have to do with the actual tree structure, and also with things that we use to define node types, operator types and value types. We will not make a different node for each case of "similar" expressions and statements, but will combine them and separate them with the help of other structures. By that I mean that we will have to define some values (with define or enums) that will help us distinguish node and operator types from each other, so that we can store this information with ease. In the same way, we also have to define a structure (union) for different types of values. Any constant, for example, might be stored in the same "constant node" structure, but will of course have a different type of value, depending on the constant that it is (int, char, double etc.).So, after this somewhat extensive introduction, let's now get started!
Node, Operator and Value Types
The language for which we implement the compiler for allows only some specific types of statements and expressions. In previous articles we described which exact grammar and syntax this language follows by also implementing this syntax in form of a Bison parser. This means that we know which exact nodes are created when parsing the language in form of the simple "parse tree". As we said last time, this parse tree is complex and large and contains lots information, which children-nodes can easily give to their parent-nodes, making those children useless! That's why we create the more condensed form, which is also far more simple to use, by which I refer to the AST. By also knowing the operators and datatypes that our language has, we can set up and define structures and values for these types...Node Types
So, how many nodes does our language need? Well, first of all it might be a good idea to define a simple or basic node with no special use, just so that all the others can be "type-casted" to this node-type.After that we need:
- One or more nodes to store a declaration
- A node to store a constant value
- Some nodes to store an if statement
- Nodes for storing for, while and assignment statements
- A node to store simple statements like continue, break and "main's"return
- A node to store the increment/decrement statement
- A node to store a function call statement
- Nodes for storing arithmetic, boolean, relational and equality expressions
- One or more nodes for storing function declarations
- A node for storing the more complex function return statement
- etc.
typedef enum Node_Type {
BASIC_NODE, // no special usage (for roots only)
// declarations
DECL_NODE, // declaration
CONST_NODE, // constant
// statements
IF_NODE, // if statement
ELSIF_NODE, // else if branch
FOR_NODE, // for statement
WHILE_NODE, // while statement
ASSIGN_NODE, // assigment
SIMPLE_NODE, // continue, break and "main" return statements
INCR_NODE, // increment statement (non-expression one)
FUNC_CALL, // function call
// expressions
ARITHM_NODE, // arithmetic expression
BOOL_NODE, // boolean expression
REL_NODE, // relational expression
EQU_NODE, // equality expression
// functions
FUNC_DECL, // function declaration
RETURN_NODE, // return statement of functions
}Node_Type;An enum is similar to the millions of defines that we used till now, but much easier to edit, cause we will not have to change the defined values of many node types whenever we add or remove some rule (something that I did until now). Also, note that we defined it using "typedef", which similar to structs and unions now allows us to declare an entry by simply using the keyword "Node_Type". Being an integer in the range 0...N we could of course also simply define an integer and use the different names we gave to the entries of the enum. Yes, there will be some overlapping, but we will use the values 0...N knowing which exact "thing" we are referring to, and so node, operator and data types will not "care" about the same value being used in other parts of the compiler.
Operator Types
In the same way, let's also ask ourselves, "which operators do we have?" Well, pretty simple question. Knowing our language we know that there is a number of operators, which can also be grouped and separated into some categories. That way we have arithmetic, boolean, relational and equality operators. As operators of the same category will have similar "behavior" we will later on define a structure for each of them. Using the same concept that we used in node types, we can therefore define an enum for each of these types of operators. You might remember that we grouped many of those operators depending on the category already. The greatest example might be the Relational and Equality operators, which are all being represented by the same exact token. Another example is the ADDOP token, which represents both the addition and subtraction operation! Also, the increment and decrement operations are both represented by the token INCR.The operators of each category are:
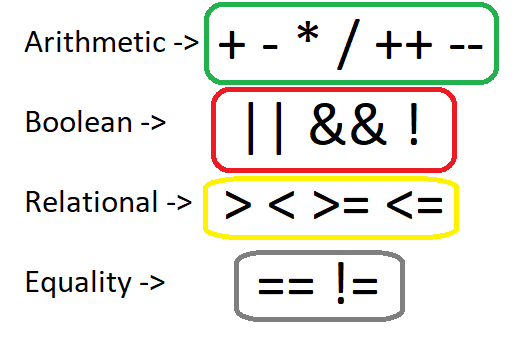
As enums these operators types can be defined as following:
typedef enum Arithm_op{
ADD, // + operator
SUB, // - operator
MUL, // * operator
DIV , // / operator
INC, // ++ operator
DEC, // -- operator
}Arithm_op;
typedef enum Bool_op{
OR, // || operator
AND, // && operator
NOT // ! operator
}Bool_op;
typedef enum Rel_op{
GREATER, // > operator
LESS, // < operator
GREATER_EQUAL, // >= operator
LESS_EQUAL // <= operator
}Rel_op;
typedef enum Equ_op{
EQUAL, // == operator
NOT_EQUAL // != operator
}Equ_op;Value Types
Mostly for storing the value of a constant node, it might be useful to create an union (to save storage) of the different values that can occur. Knowing that we have integer, real, character and string constants, we will create an union of the name "Value" with an entry for each of these types. That way we end up with:typedef union Value{
int ival;
double fval;
char cval;
char *sval;
}Value;Pretty simple right? This union will be used for even more later on, by maybe even replacing the 4 separate values that we had in the YYSTYPE union of the Bison parser. We will get back to this structure later on!
AST Node Structures
So, all this stuff that we covered until now was quite interesting, but surely not the main topic of today's article! The main topic is how exactly this tree structure called AST will be implemented. Being a tree structure and knowing that we have many different types of nodes that we discussed previously, the basic structure looks as following:
So, first of all, all the nodes have to contain a Node Type, so that we know which entries it consists of. Depending on the type of node that we are talking about, a node will have additional attributes and information stored in it and might even include more children node pointers or none of them (constant for example).
As a structure the basic node is being defined in code as:
typedef struct AST_Node{
enum Node_Type type;
struct AST_Node *left;
struct AST_Node *right;
}AST_Node;This is the type of structure that we will mainly use, by type-casting the others that are more specific to it. After all, pointers can point to anything (word-play), as they simply store a memory location/address.
So, what follows now? A lot of typing! We have to define a structure for every single node type that we talked about previously. Each of these types also needs a specific way of "creation" that we will leave for next time! Including lots of comments for each of them, I guess that I don't have to explain much about the code. These actual attributes might change later on, if we find difficulties when using them. We could also create new nodes or even remove some that I thought about now if they prove to be completely useless or unusable.
The structures for the remaining types, categorized somewhat, are:
/* Declarations */
typedef struct AST_Node_Decl{
enum Node_Type type; // node type
// data type
int data_type;
// symbol table entries of the variables
list_t** names;
}AST_Node_Decl;
typedef struct AST_Node_Const{
enum Node_Type type; // node type
// data type
int const_type;
// constant value
Value val;
}AST_Node_Const;
/* Statements */
typedef struct AST_Node_If{
enum Node_Type type; // node type
// condition
struct AST_Node *condition;
// if branch
struct AST_Node *if_branch;
// else if branches
struct AST_Node **elsif_branches;
// else branch
struct AST_Node *else_branch;
}AST_Node_If;
typedef struct AST_Node_Elsif{
enum Node_Type type; // node type
// condition
struct AST_Node *condition;
// branch
struct AST_Node *elsif_branch;
}AST_Node_Elsif;
typedef struct AST_Node_For{
enum Node_Type type; // node type
// initialization
struct AST_Node *initialize;
// condition
struct AST_Node *condition;
// incrementation
struct AST_Node *increment;
// branch
struct AST_Node *for_branch;
}AST_Node_For;
typedef struct AST_Node_While{
enum Node_Type type; // node type
// condition
struct AST_Node *condition;
// branch
struct AST_Node *while_branch;
}AST_Node_While;
typedef struct AST_Node_Assign{
enum Node_Type type; // node type
// symbol table entry
list_t *entry;
// assignment value
struct AST_Node *assign_val;
}AST_Node_Assign;
typedef struct AST_Node_Simple{
enum Node_Type type; // node type
// continue, break or "main" return
int statement_type;
}AST_Node_Simple;
typedef struct AST_Node_Incr{
enum Node_Type type; // node type
// identifier
list_t *entry;
// increment or decrement
int incr_type; // 0: increment, 1: decrement
// post- or prefix
int pf_type; // 0: postfix, 1: prefix
}AST_Node_Incr;
typedef struct AST_Node_Func_Call{
enum Node_Type type; // node type
// function identifier
list_t *entry;
// call parameters
AST_Node **params;
}AST_Node_Func_Call;
/* Expressions */
typedef struct AST_Node_Arithm{
enum Node_Type type; // node type
// operator
enum Arithm_op op;
struct AST_Node *left; // left child
struct AST_Node *right; // right child
}AST_Node_Arithm;
typedef struct AST_Node_Bool{
enum Node_Type type; // node type
// operator
enum Bool_op op;
struct AST_Node *left; // left child
struct AST_Node *right; // right child
}AST_Node_Bool;
typedef struct AST_Node_Rel{
enum Node_Type type; // node type
// operator
enum Rel_op op;
struct AST_Node *left; // left child
struct AST_Node *right; // right child
}AST_Node_Rel;
typedef struct AST_Node_Equ{
enum Node_Type type; // node type
// operator
enum Equ_op op;
struct AST_Node *left; // left child
struct AST_Node *right; // right child
}AST_Node_Equ;
/* Functions */
typedef struct AST_Node_Func_Decl{
enum Node_Type type; // node type
// return type
int ret_type;
// symbol table entry
list_t *entry;
}AST_Node_Func_Decl;
typedef struct AST_Node_Return{
enum Node_Type type; // node type
// return type
int ret_type;
// return value
struct AST_Node *ret_val;
}AST_Node_Return;Still alive? Haha, I guess there are lots of them! It might be a lot of work to do, but having one single AST Node structure that contains the information of all the nodes that we can have, would just be horrible! It would use up a lot of space, similar to what we are currently doing with symbol table entries. Later on we will try to optimize the Symbol Table too, by creating a different structure for each different symbol table item, as we can have a simple variable, pointers, arrays, function call and functions.
Some AST Management Functions
Before leaving I would first like to show some simple "create" functions. Creating a basic node is very easy, we just have to give the node type, left and right child as parameters, do a correct memory allocation, set these entries and return a AST_Node structure pointer. The function for that looks as following:AST_Node *new_ast_node(Node_Type type, AST_Node *left, AST_Node *right){
// allocate memory
AST_Node *v = malloc (sizeof (AST_Node));
// set entries
v->type = type;
v->left = left;
v->right = right;
// return the result
return v;
}In the same way we can also create functions for the declaration and constant nodes. Both of them don't need a type parameter, as we can set it directly via the function. A declaration node needs the data type and symbol table entries in form of an dynamic array. The constant node needs the constant type (data type actually) and value in form of the Value structure. In the end we will return a type-casted pointer to the AST_Node structure!
So, the code for those cases is:
AST_Node *new_ast_decl_node(int data_type, list_t **names){
// allocate memory
AST_Node_Decl *v = malloc (sizeof (AST_Node_Decl));
// set entries
v->type = DECL_NODE;
v->data_type = data_type;
v->names = names;
// return type-casted result
return (struct AST_Node *) v;
}
AST_Node *new_ast_const_node(int const_type, Value val){
// allocate memory
AST_Node_Const *v = malloc (sizeof (AST_Node_Const));
// set entries
v->type = CONST_NODE;
v->const_type = const_type;
v->val = val;
// return type-casted result
return (struct AST_Node *) v;
}The remaining functions for creating and some others which are also quite important will be discussed next time...
Integration with the Compiler
To integrate all this code with the rest of the compiler we have to include the code file "ast.c" in the parser and the header file "ast.h" in both the parser and the lexer. I guess it's also worth mentioning that other headers are not being included in the AST code and headers as they gave multiple declaration errors, while compiling the compiler. Also, including the AST structure, the YYSTYPE union of the parser will now looks as following:/* YYSTYPE union */
%union{
// simple values (will remove them later on)
char char_val;
int int_val;
double double_val;
char* str_val;
// structures
list_t* symtab_item;
AST_Node* node;
}You should go to GitHub to understand the changes in the Code structure!
RESOURCES
References:
The following helped me through today's procedure:- https://efxa.org/2014/05/25/how-to-create-an-abstract-syntax-tree-while-parsing-an-input-stream/
- http://www.cse.iitb.ac.in/grc/intdocs/gcc-implementation-details.html#toc_Top
Images:
All of the images are custom-made!Previous parts of the series
- Introduction -> What is a compiler, what you have to know and what you will learn
- A simple C Language -> Simplified C, comparison with C, tokens, basic structure
- Lexical Analysis using Flex -> Theory, Regular Expressions, Flex, Lexer
- Symbol Table (basic structure) ->Why Symbol Tables, Basic Implementation
- Using Symbol Table in the Lexer -> Flex and Symbol Table combination
- Syntax Analysis Theory -> Syntax Analysis, grammar types and parsing
- Bison basics -> Bison tutorial actually
- Creating a grammar for our Language -> Grammar and first Parser
- Combine Flex and Bison -> lexer and parser combined
- Passing information from Lexer to Parser -> Bug Fix, yylval variable, YYSTYPE union, Setting up the Parser, Passing information "directly" and through the symbol table (special case) with examples.
- Finishing Off The Grammar/Parser (part 1) -> Adding the missing grammar rules, small fixes
- Finishing Off The Grammar/Parser (part 2) -> Operator priorities, precedencies and associativity, complete example file (for testing), grammar rule visualization, finish off grammar/parser
- Semantic Analysis Theory -> What is Semantic Analysis about, CSG and CSL, Attribute Grammars, Syntax Directed Translations (SDT)
- Semantics Examples -> Visualization of Semantics for different rules/cases, needed attributes, what we have to implement from now on
- Scope Resolution using the Symbol Table -> What we have now, scope resolution, integration, compiler output
- Type Declaration and Checking -> Type declaration and type checking code, "simple" code integration
- Function Semantics (part 1) -> Code for parameter definitions, function declarations and parameter compatibility checking
- Function Semantics (part 2) -> Revisit queue concept, basic implementation, inserting undeclared identifiers
- Abstract Syntax Tree Principle -> Intermediate code generation and representations, how to design an AST
Final words | Next up on the project
And this is actually it for today's post! I hope that I explained everything as much as I needed to, meaning that you learned something out of it.Next up on this series are:
- Semantic analysis (using semantic, and so action rules in Bison)
- Intermediate Code generation (Abstract Syntax Tree Management)
- Machine Code generation (MIPS Assembly)
So, see ya next time!
GitHub Account:
https://github.com/drifter1
Keep on drifting! ;)
Thank you for your contribution @drifter1.
As always an excellent tutorial, theoretically very well explained and of high quality.
Thanks for your good work on developing this great tutorial.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
Thank you for your review, @portugalcoin! Keep up the good work!
Compilers are usually things I just use, without spending too much thought on how it actually works. This is a very nice write-up on how some of the internal stuff is looking and how you could structure and create your own one. Looking forward to the next one :D
Well, then I welcome you to this series!
It's a quite complicated topic, but I try to make things as understandable as they can get. Whenever there is the need I make purely theoretical articles to explain a topic in-depth. But, the most stuff is simply understanding how it should work and trying to implement it step by step :P Being a programmer you get to understand all the data structures and their usefulness much more!
Have fun :)
Hey, @drifter1!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Hello! Your post has been resteemed and upvoted by @ilovecoding because we love coding! Keep up good work! Consider upvoting this comment to support the @ilovecoding and increase your future rewards! ^_^ Steem On!

Reply !stop to disable the comment. Thanks!
Hi @drifter1!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server