Writing a simple Compiler on my own - Using Symbol Table in the Lexer
/Guide%20to%20the%20Galaxy%206_%20Design_files/symboltable.gif)
Hello it's a me again Drifter Programming! Today we continue with my compiler series, after a loooooong pause, because I don't had so much time for complicated coding :P
In my previous post I covered Symbol Tables, talking about how they are useful and also implementing the basic structure.
Today's topic are Symbol tables again, but this time we will get more in depth into the functions and combine it with the Lexer!
So, let's get started!
Quick Recap
In this series so far we covered the steps that a compiler follows to compile and also implemented the first part, which is the lexical analysis with the C-tool Flex!
The second part, that will come after this post, is the Syntax Analysis that I will implement using another C-tool called Bison, that is a Syntax/Semantic Analyst. Bison and the lexer of Flex are able to communicate, but the information is only there for a limited time (temporary) and so we use a Symbol Table (a hashtable data-structure), where we store important information about the identifiers!
Symbol Table changes
Last time we only covered the theory and didn't implement the whole Symbol Table, but only covered the header file "symtab.h".
First of all, I made some changes in this file. I added a global variable called cur_scope, which will store the current scope, so that when we know in which scope we are. This will help us when inserting an identifier to the Symbol Table, cause now we can also set the scope.
Also, the function hide_scope is now hiding the current scope and there is also another function incr_scope() that will increment the scope, so that we go to the next scope! This means that the function hide() doesn't exist anymore.
Lastly, I had a mistake in lookup_scope(), cause I didn't include a parameter for the scope! I now fixed it, by adding a parameter int scope.
So, the code now looks like this:
/* maximum size of hash table */#define SIZE 211
/* maximum size of tokens-identifiers */#define MAXTOKENLEN 40
/* token types */#define UNDEF 0#define INT_TYPE 1#define REAL_TYPE 2#define STR_TYPE 3#define LOGIC_TYPE 4#define ARRAY_TYPE 5#define FUNCTION_TYPE 6
/* how parameter is passed */#define BY_VALUE 1#define BY_REFER 2
/* current scope */int cur_scope = 0;
/* parameter struct */typedef struct Param{ int par_type; char param_name[MAXTOKENLEN]; // to store value int ival; double fval; char *st_sval; int passing; // value or reference}Param;
/* a linked list of references (lineno's) for each variable */typedef struct RefList{ int lineno; struct RefList *next; int type;}RefList;
// struct that represents a list nodetypedef struct list_t{ char st_name[MAXTOKENLEN]; int st_size; int scope; RefList *lines; // to store value and sometimes more information int st_ival; double st_fval; char *st_sval; // type int st_type; // for arrays (info type) and functions (return type) int inf_type; // array stuff int *i_vals; double *f_vals; char **s_vals; int array_size; // function parameters Param *parameters; int num_of_pars; // pointer to next item in the list struct list_t *next;}list_t;
/* the hash table */static list_t **hash_table;
// Function Declarationsvoid init_hash_table(); // initialize hash tableunsigned int hash(char *key); // hash function void insert(char *name, int len, int type, int lineno); // insert entrylist_t *lookup(char *name); // search for entrylist_t *lookup_scope(char *name, int scope); // search for entry in scopevoid hide_scope(); // hide the current scopevoid incr_scope(); // go to next scopevoid symtab_dump(FILE *of); // dump fileYou can get the code from pastebin: https://pastebin.com/nvN4FbCR
Let's now get into the implementation of the different functions, so that we create the file symtab.c!
Symbol Table Functions
init_hash_table()
This function is used for the initialization of a hash/symbol table.
We already have a prime-size defined (SIZE) and so we simple have to allocate enough memory to store SIZE pointers to hash-table linked lists. Because the hashtable is a dynamic array we will use the malloc() function of C to allocate SIZE times the size of those pointers. These linked list pointers will of course be initialized to NULL at first.
The code for this looks like this:
void init_hash_table(){ int i; hash_table = malloc(SIZE * sizeof(list_t*)); for(i = 0; i < SIZE; i++) hash_table[i] = NULL;}hash()
This function will process the input string/identifier in some way (hash function) and then return a integer value which corresponds to the hash-value of this string, and is representing the position/list of the hashtable in which this string belongs to.
My hash function does the following:
- Initialize a hashval variable with value 0
- Loop through all the characters of the string and add their ASCII value to this variable
- Add the remainder (modulo) with 11 of the first character's ASCII value to the variable
- Add the triple left shift (<< 3) of the first character's ASCII value to the variable
- Substract the ASCII value of the first character of the the variable
- Get the remainder (modulo) with the SIZE of the hashtable and return it
This function is of course not perfect and is just an example so that you understand what it needs to do. Either way, the final result must be an index of the hashtable and so we must do the final modulo and what changes is the operations/calculations on the characters of the input string.
The code for this function is:
unsigned int hash(char *key){ unsigned int hashval = 0; for(;*key!='\0';key++) hashval += *key; hashval += key[0] % 11 + (key[0] << 3) - key[0]; return hashval % SIZE;}insert()
This function is for inserting a new identifier to the Symbol Table.
The parameters are the name of that identifier together with it's length, the type of the identifier that will first be UNDEF and changed afterwards and lastly the line number (lineno) where it was found!
To insert we must first use the hash() function to get the hash-index. After that we can start searching at the corresponding linked list.
If the identifier has not been inserted before then we can create a new entry that will contain the current known information and will also initialize the Reference list. If it was inserted before then we will add the line number to the reference list and can also update the scope (we will get back to that in later posts).
So, the code looks like this:
void insert(char *name, int len, int type, int lineno){ unsigned int hashval = hash(name); list_t *l = hash_table[hashval]; while ((l != NULL) && (strcmp(name,l->st_name) != 0)) l = l->next; /* variable not yet in table */ if (l == NULL){ l = (list_t*) malloc(sizeof(list_t)); strncpy(l->st_name, name, len); /* add to hashtable */ l->st_type = type; l->scope = cur_scope; l->lines = (RefList*) malloc(sizeof(RefList)); l->lines->lineno = lineno; l->lines->next = NULL; l->next = hash_table[hashval]; hash_table[hashval] = l; printf("Inserted %s for the first time with linenumber %d!\n", name, lineno); // error checking } /* found in table, so just add line number */ else{ l->scope = cur_scope; RefList *t = l->lines; while (t->next != NULL) t = t->next; /* add linenumber to reference list */ t->next = (RefList*) malloc(sizeof(RefList)); t->next->lineno = lineno; t->next->next = NULL; printf("Found %s again at line %d!\n", name, lineno); }}lookup()
This function is of course used for searching purposes.
We find the hash-index of the input by using the hash() function, and then start searching for the string on the corresponding linked list.
If it was found then we will return the entry-pointer to the corresponding information of that identifier/string, else we will return NULL, which will mean that it was not found.
So, the code looks like this:
list_t *lookup(char *name){ /* return symbol if found or NULL if not found */ unsigned int hashval = hash(name); list_t *l = hash_table[hashval]; while ((l != NULL) && (strcmp(name,l->st_name) != 0)) l = l->next; return l; // NULL is not found}lookup_scope()
The previous function can be extended so that it also checks for the scope.
All that changes is the while check, cause it now will also see if there is a identifier with the specific scope. I created this function just to have it, cause the scope management is not done yet and changes will be made for sure!
Anyways, the code is:
list_t *lookup_scope(char *name, int scope){ /* return symbol if found or NULL if not found */ unsigned int hashval = hash(name); list_t *l = hash_table[hashval]; while ((l != NULL) && (strcmp(name,l->st_name) != 0) && (scope != l->scope)) l = l->next; return l; // NULL is not found}hide_scope() and incr_scope()
These functions are used for hiding the current scope (decreasing the variable) and going to the next scope (increasing the variable).
There might be changes on these two later on, but for now everything seems right!
The code is:
void hide_scope(){ /* hide the current scope */ if(cur_scope > 0) cur_scope--;}void incr_scope(){ /* go to next scope */ cur_scope++;}symtab_dump()
Lastly, this function will be used for printing out what remained in the Symbol Table and for printing the Symbol Table content for testing in the early stages.
There is nothing special with it. It just loops through all the entries of the hashtable and prints out the name, type and line numbers where the identifierss appear at throughout the code!
We might tweak it a little bit later on, but either way it is just for testing!
The code is:
/* print to stdout by default */ void symtab_dump(FILE * of){ int i; fprintf(of,"------------ ------ ------------\n"); fprintf(of,"Name Type Line Numbers\n"); fprintf(of,"------------ ------ -------------\n"); for (i=0; i < SIZE; ++i){ if (hash_table[i] != NULL){ list_t *l = hash_table[i]; while (l != NULL){ RefList *t = l->lines; fprintf(of,"%-12s ",l->st_name); if (l->st_type == INT_TYPE) fprintf(of,"%-7s","int"); else if (l->st_type == REAL_TYPE) fprintf(of,"%-7s","real"); else if (l->st_type == STR_TYPE) fprintf(of,"%-7s","string"); else if (l->st_type == ARRAY_TYPE){ fprintf(of,"array of "); if (l->inf_type == INT_TYPE) fprintf(of,"%-7s","int"); else if (l->inf_type == REAL_TYPE) fprintf(of,"%-7s","real"); else if (l->inf_type == STR_TYPE) fprintf(of,"%-7s","string"); else fprintf(of,"%-7s","undef"); } else if (l->st_type == FUNCTION_TYPE){ fprintf(of,"%-7s %s","function returns "); if (l->inf_type == INT_TYPE) fprintf(of,"%-7s","int"); else if (l->inf_type == REAL_TYPE) fprintf(of,"%-7s","real"); else if (l->inf_type == STR_TYPE) fprintf(of,"%-7s","string"); else fprintf(of,"%-7s","undef"); } else fprintf(of,"%-7s","undef"); // if UNDEF or 0 while (t != NULL){ fprintf(of,"%4d ",t->lineno); t = t->next; } fprintf(of,"\n"); l = l->next; } } }}And with that we finished the implementation of the Symbol Table...for now!
You can get the final code (symtab.c) from here on pastebin: https://pastebin.com/CbYbjQaJ
Combining with Lexer
Let's now also combine the Symbol Table with the Lexer!
First, the lexer needs to include the library using:
include "symtab.c" (with hash-tag in front)
The lexer also needs to define 2 extern FILE variables, one for the input file (program) and one for the output file of the symtab_dump() function (symtab_dump file).
Those are:
extern FILE *yyin;extern FILE *yyout;(The first is already there by default, but we can add it anyway)
In the ID's action-code we can now also use the insert() function like that:
{ID} { // insert identifier into symbol table insert(yytext, strlen(yytext), UNDEF, lineno); ret_print("ID"); }This is actually all that we will change in the rules of the Lexer-side and has to do with the Symbol Table. The Symbol Table will be used more in the Parser-side (Bison).
Lastly, we now have to initialize the symbol table in the main function, before starting the lexical analysis. After the analysis is done, we can also output the symbol table's entries to a file using the symtab_dump() function.
So, the main() function now looks like this:
int main(int argc, char *argv[]){ // initialize symbol table init_hash_table();
// open input file yyin = fopen(argv[1], "r"); // lexical analysis yylex(); fclose(yyin); // symbol table dump yyout = fopen("symtab_dump.out", "w"); symtab_dump(yyout); fclose(yyout); return 0;}The complete lexer code can be got from here: https://pastebin.com/qgxS9g5C
Running for an Example
Using cygwin let's run our Compiler (lexer actually) again to see what we get.
The command-line now also contains messages for when an identifier is inserted into the Symbol Table for the first time or even Re-inserted (found again) another time and maybe on another line.
Here's a small preview:
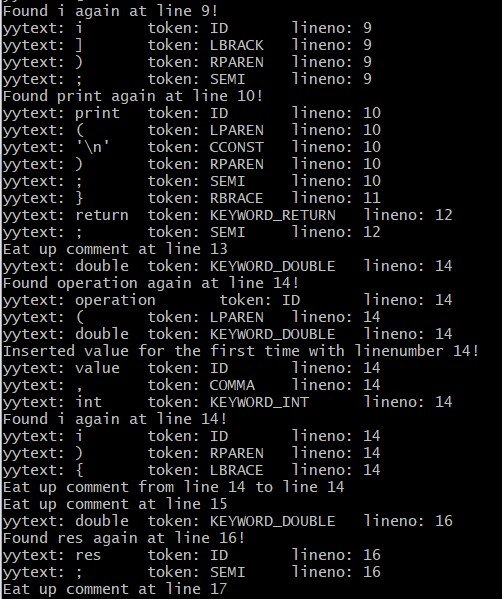
[Screenshot]
There is now also a new file in the folder. This file is the dump_file for the Symbol Table and shows us all the entries that the Symbol Table has.
It looks like this:

[Screenshot]
To run the compiler I used:
flex lexer.l
gcc -o steemit lex.yy.c
rm lex.yy.c
Which do the following:
- Compile the Flex code into C-code (lex.yy.c)
- Compile the C-code the final executable (steemit)
- Remove the file lex.yy.c
You can also put these into a Makefile
Image Sources:
/Guide%20to%20the%20Galaxy%206_%20Design_files/symboltable.gif){kind=link}
Previous posts of the series:
Introduction -> What is a compiler, what you have to know and what you will learn.
A simple C Language -> Simplified C, comparison with C, tokens, basic structure
Lexical Analysis using Flex -> Theory, Regular Expressions, Flex, Lexer
Symbol Table Structure -> Why Symbol Tables and Basic implementation
And this is actually it for today's post and I hope that you enjoyed it!
From next time on, we will start getting into Syntax Analysis!
Bye!