Writing a simple Compiler on my own - Semantics Examples [C][Flex][Bison]
 Github repository:
https://github.com/drifter1/compiler
Github repository:
https://github.com/drifter1/compiler
Introduction
Hello it's a me again @drifter1! Today we continue with my Compiler Series, a series where we implement a complete compiler for a simple C-like language by using the C-tools Flex and Bison. In this article I will try to visualize which exact semantics we have to check for the different rules of the language. Yet another article without any code or implementation procedure for the actual compiler. We just take a look at everything to understand which exact semantics are needed!The topics that we will cover today are:
- Visualization of the Semantics for different rules/cases
- Additional information (attributes) needed by the non-terminal symbols
- What exactly we have to implement
All of this stuff will be implemented in the actual compiler from next time on!
Requirements:
Actually you need to read and understand all the topics that I covered in the series as a whole, as these articles will give you access to knowledge about:- What Compiler Design is (mainly the steps)
- For which exact Language the Compiler is build for (Tokens and Grammar)
- How to use Flex and Bison
- How to implement a lexer and parser for the language using those tools
- What the Symbol Table is and how we implement it
- How we combine Flex and Bison together
- How we can pass information from the Lexer to the Parser
- How we define operator priorities, precedencies and associativity
- What Semantic Analysis is (Attributes, SDT etc.)
Difficulty:
Talking about the series in general this series can be rated:- Intermediate to Advanced
- Medium
Actual Tutorial Content
Visualization of the Semantics
Syntax of the Language
To visualize and explain the semantics we first have to get back to the syntax of the language, to see which exact rules this languages has. The bison parser that we implemented until now, has the following production rules:program: declarations statements RETURN SEMI functions_optional ;
/* declarations */
declarations: declarations declaration | declaration;
declaration: type names SEMI ;
type: INT | CHAR | FLOAT | DOUBLE | VOID ;
names: names COMMA variable | names COMMA init | variable | init ;
variable: ID |
pointer ID |
ID array
;
pointer: pointer MULOP | MULOP ;
array: array LBRACK expression RBRACK | LBRACK expression RBRACK ;
init: var_init | array_init ;
var_init : ID ASSIGN constant;
array_init: ID array ASSIGN LBRACE values RBRACE ;
values: values COMMA constant | constant ;
/* statements */
statements: statements statement | statement ;
statement:
if_statement | for_statement | while_statement | assigment SEMI |
CONTINUE SEMI | BREAK SEMI | function_call SEMI |
ID INCR SEMI | INCR ID SEMI
;
if_statement:
IF LPAREN expression RPAREN tail else_if optional_else |
IF LPAREN expression RPAREN tail optional_else
;
else_if:
else_if ELSE IF LPAREN expression RPAREN tail |
ELSE IF LPAREN expression RPAREN tail
;
optional_else: ELSE tail | /* empty */ ;
for_statement:
FOR LPAREN assigment SEMI expression SEMI expression RPAREN tail ;
while_statement: WHILE LPAREN expression RPAREN tail ;
tail: LBRACE statements RBRACE ;
expression:
expression ADDOP expression |
expression MULOP expression |
expression DIVOP expression |
ID INCR |
INCR ID |
expression OROP expression |
expression ANDOP expression |
NOTOP expression |
expression EQUOP expression |
expression RELOP expression |
LPAREN expression RPAREN |
var_ref |
sign constant |
function_call
;
sign: ADDOP | /* empty */ ;
constant: ICONST | FCONST | CCONST ;
assigment: var_ref ASSIGN expression ;
var_ref : variable | REFER variable ;
function_call: ID LPAREN call_params RPAREN;
call_params: call_param | STRING | /* empty */
call_param : call_param COMMA expression | expression ;
/* functions */
functions_optional: functions | /* empty */ ;
functions: functions function | function ;
function: function_head function_tail ;
function_head: return_type ID LPAREN parameters_optional RPAREN ;
return_type: type | type pointer ;
parameters_optional: parameters | /* empty */ ;
parameters: parameters COMMA parameter | parameter ;
parameter : type variable ;
function_tail:
LBRACE declarations_optional statements_optional return_optional RBRACE ;
declarations_optional: declarations | /* empty */ ;
statements_optional: statements | /* empty */ ;
return_optional: RETURN expression SEMI | /* empty */ ;- We can declare variables, pointers or arrays, with or without initialization
- We can define different types of statements (if, for, while, assignment, function call etc.)
- There are lots of expressions (mostly mathematical and boolean)
- We can declare functions with or without parameters, declarations and statements
A "complete" example program
You might remember the "full" example program that we created in pt.2 of "Finishing off the Grammar/Parser". But, just to be more complete, here it is:// program: declarations statements RETURN SEMI functions
// main function (declarations statements)
// declarations
int i; // simple variable
char c = 'c'; // one with init
double val = 2.5, res[6]; // two variables, one with init and one array
double *p; // pointer variable
// statements
p = &res; // assigment
// for
for(i = 0; i < 10; i++){
// if-elseif-else
if(i > 5){
break;
}
else if(i == 5){
i = 2 * i;
val = func1();
*p = add(val, i);
print(res[i]);
print("\n");
continue;
}
else{
*p = add(val, i);
val = res[i];
print(res[i]);
print("\n");
p = p + 1;
}
// if only
if(i == 2 && val == 4.5){
print("iteration: 3\n");
}
}
// while
while(i < 12){
print(i);
print(" ");
func2(c);
i++;
}
print("\n");
/* RETURN SEMI */
return;
// other functions (functions)
int func1(){ /* without parameters */
// statements
return 5;
}
void func2(char c){ /* with one parameter */
// declarations
char *s;
// statements
*s = c;
print(*s);
}
double add (double a, int b){ /* with two parameters */
// declarations
double res;
// statements
res = a + b;
return res;
}So, let's get into each case on it's own now!
Declaration semantics
When declaring a variable we of course have to check if that variable has already been declared in the current scope that we are in. This scope is mostly the same function. Variables of the main function will be treated as global variables and so each function, either main or of the other optional ones, will have access to these variables. An optional function can of course have an variable with the same name, but then only the current scope's variable will be accessible. This so called scope resolution of variables, is something very important!For the example, the variables and the corresponding scopes of them are:
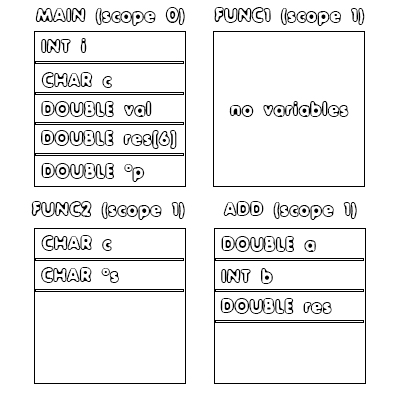
Of course seeing the same scope "value" for the last three functions you might be thinking now "WTF". Let me explain that for you. The current scope variable starts out at '0', which means that the global scope or main function scope is index '0'. Everytime we enter a function we increment (+1) that value. That's why the scope of function "func1" is '1'. Also, everytime we leave a function (a function ends) we decrement (-1) that value, meaning that the value is '0' after leaving function "func1". We of course don't allow nested declarations of functions (for now), and so the value of the scope will be '0' for the main or global scope and '1' for any other function. But, what exactly will happen after we leave a scope? As we leave a scope, we also remove or hide the corresponding symbol table entries of that scope. This explains how scope '1' can store variables of three different functions. So, the variables of a function that we are leaving will not be accessible at the next function. We never actually leave the main scope (to get to '-1') and so the global variables of the main function will be always accessible!
BUT, the scope is not the only thing that we have to check here! Ok, until now we check if a variable has been declared already. If yes, there is of course an semantic error. When declaring simple variables (ID's) or pointers without initialization (pointers don't have an initialization yet), the declaration check is enough. On the other hand, when declaring an array variable with or without initialization and when initializing a simple variable, we have to check some things! For the array and simple variable, the actual initialization values have to be of the correct constant type! An integer array can't have values of double for example, but an double array could have some integer values, cause we can type-cast them, without "losing" information! In the same way, we also have to check the expression inside of the brackets. As already said before in this article, the expression needs to give some positive integer constant value. To keep it even simpler we might just allow an integer constant "ICONST" to be used, by re-writing the grammar rules, making the declaration and use of an array completely different things! We will see how it turns out!
To understand everything even better, here an visualization of what is allowed in the declarations of the example file:
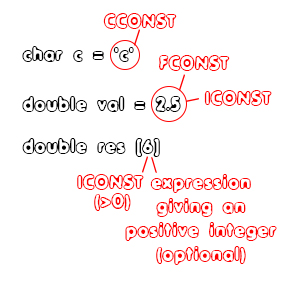
So, you can see that:
- the character type "char" is only allowing "CCONST" constants.
- the "double" type is allowing both "ICONST" and "FCONST" constants.
- the size of an array must be an positive "ICONST" or maybe even an whole expression that gives such a return value.
Statement semantics
There are lots of statements in the grammar. The continue and break statements of course don't need any check. But the others, oh boi, they have lots of semantics. Let's get into each of the statements alone!Incr/decr-ementation of ID
The identifier or simple-variable to increment has to be of a "numeric" type. This means that we can only increment/decrement integers or floating point numbers. So, the identifier (ID) used in this statement needs to be declared as an int, float or double. We also often do character math, cause the ASCII form of characters is very useful. So, in the end, the only type of ID that is not allowed is the void type! For example, in the example program we can clearly see that "i++" is semantically correct, cause the identifier 'i' is of type int, which is allowed.If statement
An if statement is interesting! The expression inside of the parenthesis of the "if" and "else if" parts has to return a boolean value, so that it can be used as a branch condition. A Boolean value can be returned using Boolean operators, which can be the classic and (&&), or (||) and not (!), relation operations (>, <, >=, <=) or equality-inequality operators (==, !=). Sometimes we might even put a constant, variable or whole expression without such things. Than the Boolean value is mostly '0' for numerical values which are zero or less, and '1' for values greater than zero. You can clearly see that there will be lots of type checking!For example:
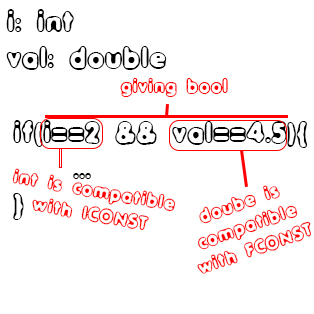
The condition is clearly giving a Boolean value, cause it's an Boolean expression. The different operations that this expression is build of, are also between compatible types. So, in the end the "simple" if statement is semantically correct!
For statement
An for statement is even more complex than the previous one. From the Syntax we already check if the first part of the parenthesis is an assignment or not. So, what remains now is checking if the second part is an expression that can return a Boolean value (0 or 1, false or true), to be treated as an exit condition. The third part can clearly be any expression. During all that we might also want to check if the loop counter (mostly 'i') is present in all three parts!For example:
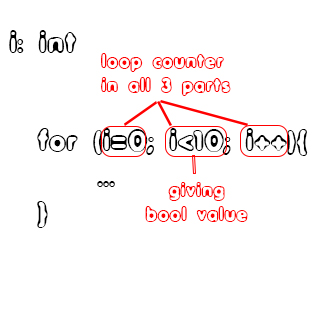
You can see that the loop counter is in all three parts of the for statement and that the condition is valid, cause it returns a Boolean value.
While statement
A while statement is pretty similar to an if statement, cause we only have to check if the condition inside of the parenthesis is returning a valid bool value or not. Being a loop, we might also want to check if the identifiers used in the loop condition are also used in the statements of the loop. Just to have a way of finding infinite loops and to be able to warn the programmer that there might be an semantic error there, without actually stopping the compilation procedure!For example:
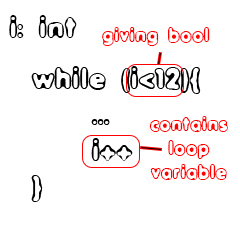
The condition is ok, cause we are checking if an integer is less than an integer. This check will return a boolean value of '1' or '0', meaning that it's a valid loop condition. We can go even further and see that the loop contains the variable again. Doing that we can also come to the conclusion that the loop is not infinite. This might be difficult to implement, cause the actual correctness of the operation on that variable might be difficult to distinguish!
Assigment statement
In the assignment we will have to check that the type of the left part variable is compatible with the result of the right part expression. So, having an integer we can only assign an integer value, having a double we can assign both integer and floating point values. Pretty simple, in theory :PAn example:
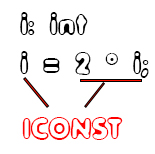
Identifier 'i' is of type int, which means that it expects an "ICONST"-value. Multiplying an integer with an integer of course gives an integer or "ICONST"-value, and so the assignment is semantically correct!
Function call statement
When calling a function, this function might have not been declared yet, cause the function declarations come after the main function! So, the semantic checks for function calls might end up in a "check-afterwards" or "check-later" queue structure. The actual things that we want to check are if the function that we are trying to call has been declared or not (either directly or later on). We also want to see if the function parameters are the same or at least compatible with the parameters of the function call. This means that we have to check the actual count of parameters and if each "calling" parameter is compatible with the "formal" parameters of the function. You can clearly see that this might be the most difficult semantic check of them all!An example:
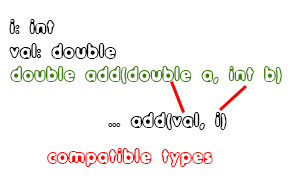
Guess it's self-explanatory that double is compatible with double, and integer with integer. Of course the double parameter can also be an integer, but the integer parameter cannot be a double!
Expression semantics
The following is a table that shows the compatible types for mathematical operations:| Operation \ Type | INT | FLOAT | DOUBLE | CHAR |
|---|---|---|---|---|
| ADDOP (+, -) | INT, CHAR | ALL | ALL | CHAR, INT |
| MULOP (*) | INT, CHAR | ALL | ALL | CHAR, INT |
| DIVOP (/) | INT, CHAR | ALL | ALL | CHAR, INT |
| INCR (++, --) | YES | YES | YES | YES |
In the same way let's also see which types are compatible with Boolean, Relational and Equality operators:
| Operation \ Type | INT | FLOAT | DOUBLE | CHAR |
|---|---|---|---|---|
| OROP (||) | INT, CHAR | INT, FLOAT | INT, FLOAT, DOUBLE | CHAR, INT |
| ANDOP (&&) | INT, CHAR | INT, FLOAT | INT, FLOAT, DOUBLE | CHAR, INT |
| NOTOP (!) | YES | YES | YES | NO |
| EQUOP (==, !=) | INT, CHAR | ALL | ALL | CHAR, INT |
| RELOP (>, <, >=, <=) | INT, CHAR | ALL | ALL | CHAR, INT |
I would like to note that some things might change later on.
Function declaration semantics
First of all, we have to check if the function used before has been declared now (already mentioned previously). Next up is checking the compatibility of the formal and "caller" parameters. And one more thing is checking if the return value is of the correct return type (if there is one - function not void). All these things are not so easy to implement and we will take care of them in articles to follow..The needed Attributes
After this in-depth explanation of the semantics for the different cases, we understand that we have to include (and actually use) the following attributes:- The scope of a variable
- Variable and expression type
- Parameters of function declarations and calls
What to implement
All of these attributes will either be part of the symbol table entry of an identifier or be attributes stored in the actual production rules or non-terminals of the grammar, creating the attribute grammar. So, what we have to implement is:- Scope resolution and declaration-check using Symbol Table
- Type checking
- Function declaration and parameter check
RESOURCES
References:
The following helped me refresh my knowledge around Semantics:- http://cse.iitkgp.ac.in/~bivasm/notes/SDD.pdf
- https://www.d.umn.edu/~rmaclin/cs5641/Notes/Lecture12.pdf
Images:
All of the images are custom-made!Previous parts of the series
- Introduction -> What is a compiler, what you have to know and what you will learn
- A simple C Language -> Simplified C, comparison with C, tokens, basic structure
- Lexical Analysis using Flex -> Theory, Regular Expressions, Flex, Lexer
- Symbol Table (basic structure) ->Why Symbol Tables, Basic Implementation
- Using Symbol Table in the Lexer -> Flex and Symbol Table combination
- Syntax Analysis Theory -> Syntax Analysis, grammar types and parsing
- Bison basics -> Bison tutorial actually
- Creating a grammar for our Language -> Grammar and first Parser
- Combine Flex and Bison -> lexer and parser combined
- Passing information from Lexer to Parser -> Bug Fix, yylval variable, YYSTYPE union, Setting up the Parser, Passing information "directly" and through the symbol table (special case) with examples.
- Finishing Off The Grammar/Parser (part 1) -> Adding the missing grammar rules, small fixes
- Finishing Off The Grammar/Parser (part 2) -> Operator priorities, precedencies and associativity, complete example file (for testing), grammar rule visualization, finish off grammar/parser
- Semantic Analysis Theory -> What is Semantic Analysis about, CSG and CSL, Attribute Grammars, Syntax Directed Translations (SDT)
Final words | Next up on the project
And this is actually it for today's post! I hope that I explained everything as much as I needed to, meaning that you learned something out of it.Next up on this series are:
- Semantic analysis ("extending" the symbol table and creating/using semantic rules in bison)
- Intermediate Code generation (Abstract Syntax Tree)
- Machine Code generation (MIPS Assembly)
So, see ya next time!
GitHub Account:
https://github.com/drifter1
Keep on drifting! ;)
nice post
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @utopian-io and @curie.
If you appreciate the work we are doing then consider voting all three projects for witness by selecting stem.witness, utopian-io and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Hello! Your post has been resteemed and upvoted by @ilovecoding because we love coding! Keep up good work! Consider upvoting this comment to support the @ilovecoding and increase your future rewards! ^_^ Steem On!

Reply !stop to disable the comment. Thanks!
Hi @drifter1!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Hey, @drifter1!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!