Writing a simple Compiler on my own - Combine Flex and Bison


Introduction
Hello it's a me Drifter Programming! Today we continue with my Compiler Series, where we write a simple Compiler using the C-tools Flex and Bison. This is also the first post of the series and my first post in general that I contibute in Utopian.io! I hope that you will like it!
Last time I created/wrote the first Grammar for our language that we will use for the Syntax Analysis, describing the steps of my thinking in a way that I think was very helpful. Today we will write the code for this grammar in Bison (fixing/tweaking some things also) and combine the new Parser with my Lexer from Flex, that I created for the Lexical Analysis.
So, without further do, let's get started!
Grammar in Bison
Fixing/Correcting the Grammar
The grammar that we created last time is:
program: declarations statements ;
declarations: declarations declaration | declaration;
declaration: type names ';' ;
type: INT | CHAR | FLOAT | DOUBLE | VOID;
names: variable | names ',' variable;
variable: ID |
('*')+ID |
ID('['ICONST']')+
;
statements: statements statement | statement;
statement:
if_statement | for_statement | while_statement | assigment |
CONTINUE | BREAK | RETURN
;
if_statement:
IF '(' expression ')' tail
(ELSE IF '(' expression ')' tail)*
(ELSE tail)?
;
for_statement: FOR '(' expression ';' expression ';' expression ')' tail ;
while_statement: WHILE '(' bool_expression ')' tail ;
tail: statement | '{' statements '}' ;
expression:
expression '+' expression |
expression '-' expression |
expression '*' expression |
expression '/' expression |
expression '++' |
expression '--' |
'++' expression |
'--' expression |
expression '||' expression |
expression '&&' expression |
'!' expression |
expression '==' expression |
expression '!=' expression |
expression '>' expression |
expression '<' expression |
expression '>=' expression |
expression '<=' expression |
'(' expression ')' |
variable |
'-'? constant
;
constant: ICONST | FCONST | CCONST ;
assigment: '&'? variable '=' expression ';' ;
I said that this is the "Bison-code", but you can clearly see that some rules are not Context-Free Grammar rules, but Regular Expressions! I'm of course talking about the rules that contain: '?', '*' or '+' that define an optional part, zero or more times the part and 1 or more times the part corresponsdingly.
So, how do we fix this? For the optional part we simply have to create 2 rules: one that contains the part and one that doesn't OR we can define a new rule that will be in the form: "something" or "nothing". For the other 2 we will create left-recursive rules, like those that we used for multiple declarations and statements.

Image source:

Let's start fixing them from the top to the bottom...
The first problem is in the "variable" rule:
variable: ID |
('*')+ID |
ID('['ICONST']')+
;
We defined 3 right-sides that correspond to a variable, pointer and array declaration. Because we can have multiple '*' and "multi-dimensional" arrays (many "[]" parts) we need to create left-recursive rules for those two elements of the rule.
A left-recurcive rule looks like this: rule: rule element | element ;
With such a rule we get 1 or more "element"-parts.
So, the rules for the pointers and arrays are:
pointer: pointer '' | '' ;
array: array '[' ICONST ']' | '[' ICONST ']' ;
Where the first one gives us 1 or more '*' and the second one, 1 or more [ICONST]-parts.
So, the variable-rule now is:
variable: ID |
pointer ID |
ID array
;
pointer: pointer '*' | '*' ;
array: array '[' ICONST ']' | '[' ICONST ']' ;
By using the same concept we can fix all the rules that contain '+'.
For rules that contain '*' we will also insert a rule that gives us 'nothing'!
Let's fix the If-statement.
For the "ELSE IF" part we create a else-if-rule that will give us many of those statements recursively. To be sure that "nothing" is also a choice we will also put a right-side rule "empty".
For the ELSE part we simple write a rule that gives us the else part or "nothing"!
So, our if-statement rule now is:
if_statement: IF '(' expression ')' tail else_if_part else_part ;
else_if_part:
else_if_part ELSE IF '(' expression ')' tail |
ELSE IF '(' expression ')' tail |
/* empty */
;
else_part: ELSE tail | /* empty */ ;
The two final rules that need to be fixed now contain only '?'. Those are the sign (-) of an expression and the reference of a variable
To fix them we simply create a new rule that gives us "this or nothing".
So, we get:
sign: '-' | /* empty */ ;
reference: '&' | /* empty */ ;
And our final rules are:
Expression:
expression:
...
sign constant
...
Assigment:
assigment: reference variable '=' expression ';' ;
Writing the parser code
Let's now write the parser code in Bison, correctly!
First, we can write some actual C-code that will incude libraries, define functions etc, After that we write the %token defintitions. This is for defining the tokens that the Lexer (Flex) will return ( integer codes) to the Parser. After that we can then define the rules of the grammar and priorities for our expressions, that we will take a look next time!
So, the first part (before the %%) of the Bison parser is:
%{
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
extern FILE *yyin;
extern int lineno;
extern int yylex();
void yyerror();
%}
/* token definition */
%token CHAR INT FLOAT DOUBLE IF ELSE WHILE FOR CONTINUE BREAK VOID RETURN
%token ADDOP MULOP DIVOP INCR OROP ANDOP NOTOP EQUOP RELOP
%token LPAREN RPAREN LBRACK RBRACK LBRACE RBRACE SEMI DOT COMMA ASSIGN REFER
%token ID ICONST FCONST CCONST STRING
%start program
/* expression priorities and rules */
After that we of course write the grammar rules...
We have to make a lot of changes, cause our rules contain the actual character sequences and not the Tokens! These changes are not so bad, cause now our grammar will become smaller and some rules will correspond to more then one actual tokens!
For example for the rule declaration we have:
declaration: type name ';' ;
Because the semicolon (;') is the Token SEMI, this now becomes:
declaration: type name SEMI;
Doing this exact process for all the rules we end up with:
program: declarations statements ;
declarations: declarations declaration | declaration;
declaration: type names SEMI ;
type: INT | CHAR | FLOAT | DOUBLE | VOID;
names: variable | names COMMA variable;
variable: ID |
pointer ID |
ID array
;
pointer: pointer MULOP | MULOP ;
array: array LBRACK ICONST RBRACK | LBRACK ICONST RBRACK ;
statements: statements statement | statement;
statement:
if_statement | for_statement | while_statement | assigment |
CONTINUE SEMI | BREAK SEMI | RETURN SEMI
;
if_statement: IF LPAREN expression RPAREN tail else_if_part else_part ;
else_if_part:
else_if_part ELSE IF LPAREN expression RPAREN tail |
ELSE IF LPAREN expression RPAREN tail |
/* empty */
;
else_part: ELSE tail | /* empty */ ;
for_statement: FOR LPAREN expression SEMI expression SEMI expression RPAREN tail ;
while_statement: WHILE LPAREN expression RPAREN tail ;
tail: statement SEMI | LBRACE statements RBRACE ;
expression:
expression ADDOP expression |
expression MULOP expression |
expression DIVOP expression |
expression INCR |
INCR expression |
expression OROP expression |
expression ANDOP expression |
NOTOP expression |
expression EQUOP expression |
expression RELOP expression |
LPAREN expression RPAREN |
variable |
sign constant
;
sign: ADDOP | /* empty */ ;
constant: ICONST | FCONST | CCONST ;
assigment: reference variable ASSIGN expression SEMI ;
reference: REFER | /* empty */ ;
I put semicolons in places that we forgot and also changed the name of the bool_expression in the while-statement to expression ! You can also clearly see that the expression's rule now contains less right-sides , cause some operations are defined by the same Token in the Lexer!
Lastly (after %%) we now only have to define two more functions, the error() function and the main() function. So, the functions are:
void yyerror ()
{
fprintf(stderr, "Syntax error at line %d\n", lineno);
exit(1);
}
int main (int argc, char *argv[]){
// parsing
int flag;
yyin = fopen(argv[1], "r");
flag = yyparse();
fclose(yyin);
return flag;
}
Combine with Flex
Tweaking our Lexer
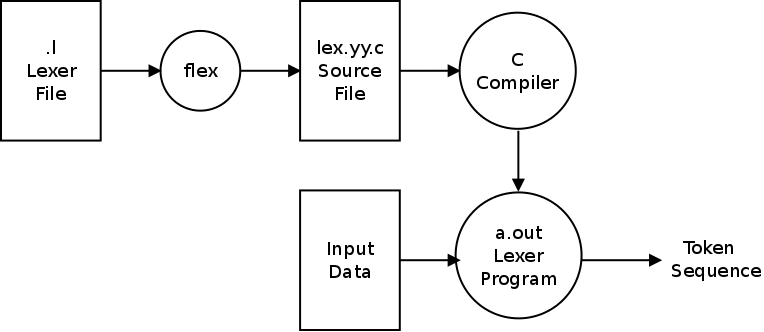
Image source:
Our Lexer must now:
- Use the Tokens from the parser
- Return those Tokens to the parser
- Return some more information (symbol table, token information etc.,)
- Don't include a main() function!
Today, we will just return those tokens to the Parser and next time we will take a look at more!
For the tokens we just have to include the parser.tab.h library that we get by running the bison compilation using the -d argument.
Instead of using the old ret_print() function we will now just return the correct token_id , by using the name we set in our Bison Parser.
Removing the main function we also see that we forgot about the Symbol Table and so we add the initialization and dump methods to the main() function of the Parser!
Doing all this we end up with this Lexer:
%option noyywrap
%{
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "symtab.h"
#include "parser.tab.h"
extern FILE *yyin;
extern FILE *yyout;
int lineno = 1; // initialize to 1
void ret_print(char *token_type);
void yyerror();
%}
%x ML_COMMENT
alpha [a-zA-Z]
digit [0-9]
alnum {alpha}|{digit}
print [ -~]
ID {alpha}+{alnum}*
ICONST "0"|[0-9]{digit}*
FCONST "0"|{digit}*"."{digit}+
CCONST (\'{print}\')|(\'\\[nftrbv]\')
STRING \"{print}*\"
%%
"//".* { printf("Eat up comment at line %d\n", lineno); }
"/*" { printf("Eat up comment from line %d ", lineno); BEGIN(ML_COMMENT); }
<ML_COMMENT>"*/" { printf("to line %d\n", lineno); BEGIN(INITIAL); }
<ML_COMMENT>[^*\n]+
<ML_COMMENT>"*"
<ML_COMMENT>"\n" { lineno += 1; }
"char"|"CHAR" { return CHAR; }
"int"|"INT" { return INT; }
"float"|"FLOAT" { return FLOAT; }
"double"|"DOUBLE" { return DOUBLE; }
"if"|"IF" { return IF; }
"else"|"ELSE" { return ELSE; }
"while"|"WHILE" { return WHILE; }
"for"|"FOR" { return FOR; }
"continue"|"CONTINUE" { return CONTINUE; }
"break"|"BREAK" { return BREAK; }
"void"|"VOID" { return VOID; }
"return"|"RETURN" { return RETURN; }
"+"|"-" { return ADDOP; }
"*" { return MULOP; }
"/" { return DIVOP; }
"++"|"--" { return INCR; }
"||" { return OROP; }
"&&" { return ANDOP; }
"!" { return NOTOP; }
"=="|"!=" { return EQUOP; }
">"|"<"|">="|"<=" { return RELOP; }
"(" { return LPAREN; }
")" { return RPAREN; }
"]" { return LBRACK; }
"[" { return RBRACK; }
"{" { return LBRACE; }
"}" { return RBRACE; }
";" { return SEMI; }
"." { return DOT; }
"," { return COMMA; }
"=" { return ASSIGN; }
"&" { return REFER; }
{ID} {
// insert identifier into symbol table
insert(yytext, strlen(yytext), UNDEF, lineno);
return ID;
}
{ICONST} { return ICONST; }
{FCONST} { return FCONST; }
{CCONST} { return CCONST; }
{STRING} { return STRING; }
"\n" { lineno += 1; }
[ \t\r\f]+ /* eat up whitespace */
. { yyerror("Unrecognized character"); }
%%
There where some problems in the compilation process and so I had to move the cur_scope variable from the symtab.h to the symtab.c file and I also had to include the .h file in the lexer and the .c file in the parser!
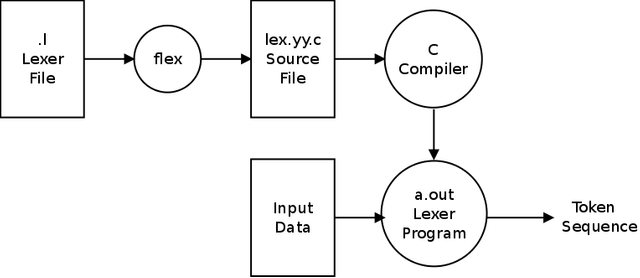
Running the Compiler
To run this Compiler we now use the following commands:
bison -d parser.y
flex lexer.l
gcc -o steemit parser.tab.c lex.yy.c
./steemit example.c
Of course the Compiler doesn't work quite right yet, but we will fix everything next time!
You can download the code that we have till now from here:
Series
Here the previous parts of this series:
- Introduction
- A simple C Language
- Lexical Analysis using Flex
- Symbol Table Structure
- Using Symbol Table in the Lexer
- Syntax Analysis Theory
- Bison basics
- Creating a grammar for our Language
All these where posted directly in Steemit!
I hope that you enjoyed this post and learned something new!
Next time we will continue with how the Lexer passes information directly and indirectly to the Parser using predicates, symbol table etc. and we will also fix some more things!
Bye!
Posted on Utopian.io - Rewarding Open Source Contributors
Your contribution cannot be approved because it does not follow the Utopian Rules.
All your files have been uploaded in the single commit (https://github.com/zhanghengxin/drifter1/commit/cb0c54f03a95644c699f2f56d907050c6d18afe1) which is against the rule in Utopian.
You can contact us on Discord.
[utopian-moderator]
Hey @codingdefined, I just gave you a tip for your hard work on moderation. Upvote this comment to support the utopian moderators and increase your future rewards!
Ok. I will try keeping up with the rules next time!
Thank you!
I am so excited for your work. I hope that you will continue this project soon.
This project takes up a lot of time...
I wanted to do stuff in the Summer, but never found time to do so (was in vacation, did other articles etc.)
Maybe the series will be revived again by September or October, and by that I mean 1 article per week or something like 2-3 per month.
Of course, by doing such a big pause I don't quite remember where I was, which means that revisiting that topic will also take up some time for me :)
Nice article :) will you share more of this? best regards from germany
Thank you.
Yes, I will continue posting my progress with the Compiler. I try to make it in a way that contains all my thinking and also the actual theory behind it. You can see that I talk about every step in detail!
Glad that you enjoyed it...
Thank you fro responding i will follow you and the process in the future :)
These images are A) Not commercially available to re-use B) Not actually linked to any source, just a larger version of the image. I suggest you properly credit images that are CC licensed or public domain if you feel like adhering to the quality standards of steemSTEM =)
Good luck!
Hello drifter1, great job with this series. I am following all along and have a lot of fun. However, it seems there is a slight error in this article.
Your example program reads at the top: "double val = 2.5", however when I run the parser I get an syntax error in this line and I think I also found he reason why:
bison thinks this is a declaration due to:
"declaration: type names SEMI"
but the production for type or names does not lead to the parsing of an assignment "assignment: reference variable ASSIGN expression SEMI ;" because an "assignment" is a statement but not part of a declaration.
This code works:
int val;
val = 2.5;
but not the combined one. How can we fix this?