Writing a simple Compiler on my own - Finishing Off The Grammar/Parser (part 2) [C][Flex][Bison]

[Custom Thumbnail]
All the Code that will be mentioned in this article can be found at the Github repository:
https://github.com/drifter1/compiler
under the folder "Finishing Off The Grammar-Parser-part2".
Introduction
Hello it's a me again @drifter1! Today we continue with my Compiler Series, a series where we implement a complete compiler for a simple C-like language by using the C-tools Flex and Bison. This article is "part 2" of the topic "Finishing Off The Grammar/Parser", where we try to finalize our Bison Parser, to support all the needed grammar rules that we can think of. Last time we covered which exact rules are missing, today we will fix up everything that we messed up last time, by finally making the grammar/parser complete and conflict-free.
The topics that we will cover today are:
- Defining operator priorities, precedencies and associativity (to fix some of the conflicts)
- Creating a complete example file
- Visualizing and understanding how grammar rules are "triggered"
- Finish off the grammar/parser
- Run the "new" parser for the example to "proof" that it's working
Requirements:
Actually you need to read and understand all the topics that I covered in the series as a whole, as these articles will give you access to knowledge about:- What Compiler Design is (mainly the steps)
- For which exact Language the Compiler is build for (Tokens and Grammar)
- How to use Flex and Bison
- How to implement a lexer and parser for the language using those tools
- What the Symbol Table is and how we implement it
- How we combine Flex and Bison together
- How we can pass information from the Lexer to the Parser
Difficulty:
Talking about the series in general this series can be rated:- Intermediate to Advanced
- Easy
Actual Tutorial Content
Defining operator priorities, precedencies and associativity
When fixing a grammar we of course mean fixing anything that might cause a conflict. In the case of expressions or more specifically the "expression"-rule we know that the order/priority of the different mathematical or boolean operators plays a big rule. Being shift-reduce conflicts, bison always chooses to shift them, meaning that the correct priority and precedence of those symbols/tokens is wrong! For example the Add-operator '+' might have a higher priority than the Mul-operator '*'. To fix all these we have to define the specific priorities and so called precedencies for all these operators in the parser file (something very easy to do). Let's start with the operators that the language contains. Those are:
- ADDOP -> '+' and '-'
- MULOP -> '*'
- DIVOP -> '/'
- INCR -> '++' and '--'
- OROP -> '||'
- ANDOP -> '&&'
- NOTOP -> '!'
- EQUOP -> '==' and '!='
- RELOP -> '>', '<', '>=' and '<='
- LPAREN -> '('
- RPAREN -> ')'
- LBRACK -> '['
- RBRACK -> ']'
- ASSIGN -> '='
- REFER -> '&'
- COMMA -> ','
Note that we also have a DOT ('.') operator, that we don't used yet!
Defining those priorities is very easy in Bison and has to be done after the token definitions and before the grammar rules. The order at which we write the precedencies/associativities tells us the high-to-low priority of the operators, meaning that we have to write the operators in decreasing priority. To define the precedence we use something similar to the token definitions.
More specifically:
- To define a operator left-associative we use %left
- To define a operator right-associative we use %right
- To define a operator with only precedence and no associativity we use %precedence
- To define a operator with no associativity we use %nonassoc
So, knowing the specific precedences and associativities of the C-Operators [Ref_2] we can easily include them in our parser. This looks as following:
%left LPAREN RPAREN LBRACK RBRACK
%right NOTOP INCR REFER
%left MULOP DIVOP
%left ADDOP
%left RELOP
%left EQUOP
%left OROP
%left ANDOP
%right ASSIGN
%left COMMA
Creating a complete example file
Until now we only checked some of the grammar rules. To see if all of them are working correctly, we will now write a complete example that contains most of the rules, so that we are able to check if the parser is working correctly.
The "full_example.c" file looks as following:
// program: declarations statements RETURN SEMI functions
// main function (declarations statements)
// declarations
int i; // simple variable
char c = 'c'; // one with init
double val = 2.5, res[6]; // two variables, one with init and one array
double *p; // pointer variable
// statements
p = &res;// assigment
for(i = 0; i < 10; i++){ // for
if(i > 5){ // if-else
break;
}
else if(i == 5){
i = 2 * i;
val = func1();
*p = add(val, i);
print(res[i]);
print("\n");
continue;
}
else{
*p = add(val, i);
val = res[i];
print(res[i]);
print("\n");
p = p + 1;
}
if(i == 2 && val == 4.5){ // if
print("iteration: 3\n");
}
}
while(i < 12){ // while
print(i);
print(" ");
func2(c);
i++;
}
print("\n");
return; /* RETURN SEMI */
// other functions (functions)
int func1(){ /* without parameters */
// statements
return 5;
}
void func2(char c){ /* with one parameter */
// declarations
char *s;
// statements
*s = c;
print(*s);
}
double add (double a, int b){ /* with two parameters */
// declarations
double res;
// statements
res = a + b;
return res;
}
You can see that this example helps us check if the following things are being detected correctly by the grammar/parser:
- more than one declarations of one or more (two in our case) variables with or without initialization and including simple ID-variables, pointers and arrays.
- most of the statements including assignment, for and while loops, if-else statements, functions calls, break, continue and return (which should not be a "normal" statement!)
- more than one function declarations including functions without parameters, with one or more (two in our case) parameters, declarations and statements (in the body) or statements only
Visualizing how grammar rules have to be "triggered" for that file
To understand how exactly our parser should be like and what exactly is wrong and should be tweaked/fixed, I think it's a good idea to visualize how the grammar rules are being "triggered" for that specific example. By that I don't mean constructing a gigantic parsing or syntax tree for the whole program, but making small trees (similar to syntax trees) for specific rules (actually all of them) to see which exact rule has to be defined for each case.
Program
First of all let's start with the complete "program".
We can clearly see that we should split it into:
- declarations and statements for the main function
- the "RETURN SEMI"-statement
- function declarations (optional)
For now this seems right as we clearly have defined such a rule already:
program: declarations statements RETURN SEMI functionsSo, the actual problems will be inside of the declarations, statements and functions!
Declarations
Let's analyze the declarations and initializations of the example.
Simple Declaration of one variable:

This shows us that variables are declared using a "type" which can be INT, DOUBLE, CHAR etc. and afterwards with the variable "name", followed by a semicolon (;).
Simple Initialization of one variable:

This rule now shows us that we can not only declare a variable, but also initialize it. The part [c = 'c'] is very similar to the assignment statement, which makes us think that using a optional "init"-rule, might have been a bad idea as it interferes with the actual assignment rule. Having a initialization of one variable or the initialization at the end of a "declaration-line" we of course create a conflict with the "assignment"-rule. This already shows us that the initialization stuff of the previous part was completely useless and wrong. But, yeah you learn from mistakes :)
Declaring a pointer variable:

This is something that we did right already. Also note that we can also have multiple MULOP's to define pointer arrays etc. The main "pointer"-rule is already right and so does the "variable"-rule that uses it. What's wrong is how we initialize things, which will be fixed later!
Declaring multiple variables:

When declaring multiple variables of the same type, we split them with a comma (','). Each one can be a "simple" variable, by which I mean an identifier (ID), pointer or array, or an initialization. For now we can only initialize variables and arrays, even though I don't included such a example in that program. Seeing that we can declare a variable with with or without initialization, we of course think that the current rule is right ("variable init", with init being optional)! But, that's actually pretty wrong as the same could also be done with two separate rules;one for "simple" variable declaration and one for "initialized" variable declaration that includes the two types of initialization, which will be used for variables and arrays correspondingly.
You can see that we already found out lots of things that need tweaking and fixing in our grammar/parser, by only talking about the "declarations"!
Statements
Taking a look at the example we can see that we are allowed to use the following types of statements:
- assignment (right part is an expression)
- if-else if, with optional else
- for loop
- while loop
- break and continue
- function calls
- postfix and suffix incrementation of ID (INRC)
Only the last bit was not included yet, showing us that we are not that bad at all, but still most of those statements are defined wrong. Note, that we might allow the incrementation of arrays and pointers as well, by using "variable" instead of ID, but I guess such things don't occur that often. The most important one is if-else, where the "else_if_part" is not that optional at all, causing the else part to be "ignored" or don't even allowing us to define a actual if-else statement that doesn't contain "else if's!
Note that we will not include "return;" anymore as it's used to separate the main from the other functions and might cause syntax errors. This is something that we already did last time, but we didn't think about the functions! Functions are allowed to use this statement to "return a result" to the main function or the function that called them, meaning that we will have to include a "optional return" for functions!
Let's start talking about each one of them, one by one...
Assignment
The basic structure of an assignment is:
variable '=' expression ';'Let's analyze the different types of assignments that occur in the example, to see if we did everything wrong. After that we will also talk about some other types that are not included in the example, but are not support "correctly" by the grammar/parser!
variable '=' '&' variable ';' :

Hmmmm, you can see that '&' is allowed to occur in the right part as well, something that is not included in the grammar rules yet! But we should be careful, we should not allow this to be used on expressions, but only on variables! This will get us to a new variable rule later on called "var_ref", which let's us define variable with or without '&' in front to be used as an expression and in the assignment rule in the place of "reference variable". The actual "assignment"-rule didn't work out as the "reference"-part was completely useless causing syntax errors.
variable '=' expressions ';' :

You can see how the left-part can be any "type" of variable, whilst the right part is any expression.
Worth noting is that the left part can also be "& variable", meaning that we will not use variable, but a new "var_ref"-rule, which was mentioned earlier! To make it easier for us to distinguish a initialization from an assignment statement, the "assignment"-rule will not contain the SEMI-part, but the ';' will be be given in the "statement"-rule. Very similar to how we defined the continue, break and "function call" statements!
If-else
As mentioned earlier already, the if-else statement is not working correctly. To understand this better let's analyze the two given examples of the file...
Simple if statement:

You can see that this can be recognized by the current grammar, cause the "else_if_part" and "else_part" are both "empty", causing no trouble at all!
Complex if-else statement:

Here is where the fun begins!
The "else_if_part"-rule gets "triggered" meaning that we allow one or more (or even no) else if "parts". Having the "empty"-rule inside we can use this rule anywhere, meaning that fisrt two rules of the "else_if_part"-rule are actually equal:
else_if_part ELSE IF LPAREN expression RPAREN tail |
ELSE IF LPAREN expression RPAREN tailThe "else_if_part" can become epsilon (ε) at anytime!
Something similar happens at the else_part...
To fix this our "if_statement" needs to have two rules:
- one rule that includes that allows the usage of the "else if"-rule and
- one that only allows an "optional else"
This shows us that the "else_if_part" rule (now called "else_if") will not have an "epsilon"-rule anymore, which was the rule that caused the trouble!
That way we will now be able to have:
- a simple if statement without any "else if" or "else" part
- a if-else statement that doesn't contain "else if's"
- a if-else statement with "else if's" and a optional else
(all the cases that can occur)
Loop statements
The "while_statement" is already correct. What needs tweaking is the "for_statement", cause the assignment doesn't include the ';' anymore! Either way let's analyze an example for each type, so that you understand how such rules have to be recognized by the grammar.
For:
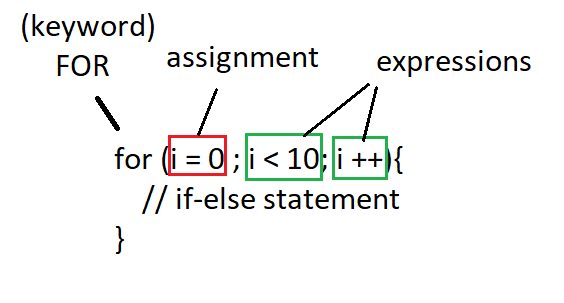
While:

Remaining statements
The remaining statements are:
CONTINUE SEMI // continue statement
BREAK SEMI // break statement
function_call SEMI // function call statement
ID INCR SEMI // prefix increment statement
INCR ID SEMI // suffix increment statementYou can see that they are not that special! The only thing that need's tweaking is the "function_call" statement, cause the "call_param"-rule only talked about variables. The parameter when calling functions can of course be a whole "expression" as well. That way we will include simple variables (ID, pointer, array), "references" to variables (the "var_ref" rule) and also complete expressions to get the value of that expression as an parameter!
Functions
The last part that we have to cover before getting into the actual "bison fixes" is how we should define functions! First of all, functions are optional meaning that we have to make them "truly" optional, by declaring a completely "new" grammar rule that allows us to define functions (based on the "functions"-rule) or not (epsilon-rule or "empty").
The most important things about functions are that:
- they can be without parameters or with one ore more parameters
- the declarations and statements are optional
- functions can "return a value" meaning that they should have a optional "return statement"
Let's analyze each of those examples from the file to understand that better...
Function without parameters and only return statement:

You can see that this function has no declarations or statements. It only returns a value using the "optional" return statement that is not defined as an "actual" statement.
Function with one parameter:

This function is of type "void" meaning that it doesn't return a value, showing us that the return statement is "optional".
Function with two parameters:

This function has everything. It contains multiple parameters (two actually), declarations, statements and the "optional' return statement.
From all this we can clearly understand that our grammar/parser needs lots of fixing, to allow the usage of an "optional" return, by also allowing optional declarations and statements. It's worth noting that we already did optional parameters as the rule "param_empty", which will now change name and become "parameters_optional", as it makes more sense that way!
Finish off the grammar/parser
So, how exactly do we have to start with the fixing?
Well, we actually covered all of the statements and expressions that can occur in a program of this C-like language, and so what remains now is actually implementing all these features! First of all, we should organize the parser rules better, cause the ordering of the rules is pretty bad! By ordering I mean that we should first cover the declaration rules, then the statements and lastly the functions!
First things first, knowing that functions are optional, the main "program"-rule becomes:
program: declarations statements RETURN SEMI functions_optional ;So, let's get into each part of that specific rule!
Declarations (or better said: Initialization)
The only thing that has to be changed is how exactly we "take care" of the initialization. Last time we declared the following "init"-rule:
init: ASSIGN init_value | /* empty */ ;
init_value: constant | array_init ;
This rule seems right, but it isn't! There is one big problem, which is that the "init"-rule is never being used. There is a similar rule already, which is the "assignment"-rule, that is being preferred. The biggest problem is that "init" can be empty. This teaches us that we should avoid epsilon-rules as much as possible! Avoiding this "epsilon rule" is much easier than it seems.
You might remember the "names"-rule, which is:
names: variable init | names COMMA variable init;
Instead of doing this we can also just let the "names"-rule use two "kinds" of variables:
- The simple variable based on the "variable"-rule, that allows the declaration of ID's, pointers and arrays, without initialization and
- A "new" type of variable that let's us initialize IDs or arrays, based on another rule called "init"!
This looks as following:
names: names COMMA variable | names COMMA init | variable | init ;
init: var_init | array_init ;
var_init : ID ASSIGN constant
array_init: ID array ASSIGN LBRACE values RBRACE ;
values: values COMMA constant | constant ;
Statements
As we already mentioned in the previous section of the article, some statements and expressions are missing. So, let's start by changing the "statement"-rule into:
statement:
if_statement | for_statement | while_statement | assigment SEMI |
CONTINUE SEMI | BREAK SEMI | function_call SEMI | ID INCR SEMI | INCR ID SEMI
;
Maybe the most important fix is the if-else statement! The "new" subrules for that specific statement are:
if_statement:
IF LPAREN expression RPAREN tail else_if optional_else |
IF LPAREN expression RPAREN tail optional_else
;
else_if:
else_if ELSE IF LPAREN expression RPAREN tail |
ELSE IF LPAREN expression RPAREN tail
;
optional_else: ELSE tail | /* empty */ ;
You can see how the "main" rule allows two specific cases:
- if statement with "else_if"-part and optional else
- if statement with optional else
By doing that we now overcome the problem of having the "else_if"-rule contain a "epsilon rule", which as we mentioned earlier creates syntax problems. That way the "else_if"-rule becomes optional without creating a separate rule that let's it be the actual rule or "nothing". Having an "invisible" epsilon-rule we now overcome the previous syntax problems, allowing us to define all the types of if-else statements!
assignment statement:
Another very important rule is the assignment statement which changes FROM
assigment: reference variable ASSIGN expression SEMI ;
assigment: var_ref ASSIGN expression ;
var_ref : variable | REFER variable ;
for statement:
Changing the assignment rule, we now also have to change the "for rule", cause it expected the ';' from the "assignment"-rule, which no longer includes it! Therefore, the "for_statement"-rule becomes:
for_statement: FOR LPAREN assigment SEMI expression SEMI expression RPAREN tail ;
expression rule:
Another rule that needs changes is the "expression"-rule, as we have to tweak some of it's subrules!
Those are:
- allow postfix and suffix INCR to be applied only on ID's (this might change later on into variable)
- change variable into "var_ref" to allow '&' to occur in front of a variable (as we saw in the example)
expression:
expression ADDOP expression |
expression MULOP expression |
expression DIVOP expression |
ID INCR |
INCR ID |
expression OROP expression |
expression ANDOP expression |
NOTOP expression |
expression EQUOP expression |
expression RELOP expression |
LPAREN expression RPAREN |
var_ref |
sign constant |
function_call
;
function call:
Lastly, we also have to tweak the parameters of function calling. For now, we only allowed the passed parameters to be variables separated with ',', strings (for the print function) or nothing (for functions without parameters). To allow whole expressions to give value on parameters, we will change "variable" into "expression" now. Note that we now allow variables to be passed by "reference" using '&', which is something that we didn't think of last time!
Fixing that we now have:
function_call: ID LPAREN call_params RPAREN;
call_params: call_param | STRING | /* empty */
call_param : call_param COMMA expression | expression ;
Functions
The grammar/parser that we have now, don't really makes the functions and their declarations, statements, return statement optional! We never really thought of the last things, cause we just used the same "declarations" and "statements" rules that the "main function" uses. Also, making the functions "optional" was done in the wrong place, direclty inside of the function-rule, again causing the grammar to become ambiguous. The "epsilon rule" of "function" could be called and used at any time, causing syntax errors!
To fix all this let's first make the "functions"-rule truly optional! This can be done using a "new" rule called "functions_optional" that let's us have the "previous" function-rule or "nothing". We could also just change the "program"-rule to have one rule with and one rule without functions, but let's stay on the previously mentioned implementation.
Making the functions optional looks as following:
functions_optional: functions | /* empty */ ;
functions: functions function | function ;
function: function_head function_tail ;
function_head: return_type ID LPAREN parameters_optional RPAREN ;
return_type: type | type pointer ;
parameters_optional: parameters | /* empty */ ;
parameters: parameters COMMA parameter | parameter ;
parameter : type variable ;
The "function_tail"-rule now becomes:
function_tail: LBRACE declarations_optional statements_optional return_optional RBRACE ;
declarations_optional: declarations | /* empty */ ;
statements_optional: statements | /* empty */ ;
return_optional: RETURN expression SEMI | /* empty */ ;
Example compilation
Let's finally also run the compiler for the example...In the console we get:

RESOURCES
References:
The following helped me define operator precedencies and associativities:
- https://www.gnu.org/software/bison/manual/html_node/Precedence.html
- https://en.cppreference.com/w/c/language/operator_precedence
Images:
All of the images are custom-made!
Previous parts of the series
- Introduction -> What is a compiler, what you have to know and what you will learn
- A simple C Language -> Simplified C, comparison with C, tokens, basic structure
- Lexical Analysis using Flex -> Theory, Regular Expressions, Flex, Lexer
- Symbol Table (basic structure) ->Why Symbol Tables, Basic Implementation
- Using Symbol Table in the Lexer -> Flex and Symbol Table combination
- Syntax Analysis Theory -> Syntax Analysis, grammar types and parsing
- Bison basics -> Bison tutorial actually
- Creating a grammar for our Language -> Grammar and first Parser
- Combine Flex and Bison -> lexer and parser combined
- Passing information from Lexer to Parser -> Bug Fix, yylval variable, YYSTYPE union, Setting up the Parser, Passing information "directly" and through the symbol table (special case) with examples.
- Finishing Off The Grammar/Parser (part 1) -> Adding the missing grammar rules, small fixes
Final words | Next up on the project
And this is actually it for today's post! I hope that I explained everything as much as I needed to, meaning that you learned something out of it.
Next up on the series are:
- Semantic analysis (predicates, more about the symbol table)
- Intermediate Code generation (Abstract Syntax Tree)
- Machine Code generation (MIPS Assembly)
Which are all topics that will need more than one article to complete. Also, note that we might also get into Optimizations later on or could even extend the Language by adding complex datatypes (structs and unions), more rules etc.
So, see ya next time!
GitHub Account:

Keep on drifting!
Thank you for your contribution @drifter1.
We've been reviewing your tutorial and suggest the following points below:
Good job, your tutorial is great. Thanks for the development of this tutorial.
We are waiting for the next tutorial.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
Thank you for your review, @portugalcoin!
So far this week you've reviewed 3 contributions. Keep up the good work!
Hi @drifter1!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server