Writing a simple Compiler on my own - Scope Resolution using the Symbol Table [C][Flex][Bison]

[Custom Thumbnail]
All the Code of the series can be found at the Github repository: https://github.com/drifter1/compiler
Introduction
Hello it's a me again @drifter1! Today we continue with my Compiler Series, a series where we implement a complete compiler for a simple C-like language by using the C-tools Flex and Bison. In this article we will try to implement the Scope Resolution using the Symbol Table. That way it will be very easy to check the declaration of an identifier, cause they are already being stored in the Symbol Table.The topics that we will cover today are:
- What we have now in the Symbol Table
- Scope resolution
- Integrating with the Parser
- Running for the full example to see the current output
Requirements:
Actually you need to read and understand all the topics that I covered in the series as a whole, as these articles will give you access to knowledge about:- What Compiler Design is (mainly the steps)
- For which exact Language the Compiler is build for (Tokens and Grammar)
- How to use Flex and Bison
- How to implement a lexer and parser for the language using those tools
- What the Symbol Table is and how we implement it
- How we combine Flex and Bison together
- How we can pass information from the Lexer to the Parser
- How we define operator priorities, precedencies and associativity
- What Semantic Analysis is (Attributes, SDT etc.)
Difficulty:
Talking about the series in general this series can be rated:- Intermediate to Advanced
- Medium
Actual Tutorial Content
What we have now in the Symbol Table
We have already created a Symbol Table in a previous part of the series. This Symbol Table is a Hash Table implemented using Linked Lists. Each symbol or list item of that Symbol table stores lots of attributes and information about an identifier. Some of them are general, others are only for some specific types of identifiers. To create the table, to insert into the table, to lookup an entry etc. we of course have to implement the correct functions. Until now, we have implemented only some of them correctly, Most of the functions and even the whole header (symtab.h) and code (symtab.c) files for the Symbol Table, need some revamping. Let's get more in-depth..Being a hash table, we defined some maximum size of hashing (SIZE variable). The prime number that I chose back then was "211", cause it's more than enough for the simple examples that we want to compile. We also defined some maximum length (or size) for the token and identifier names (MAXTOKENLEN). We could also just allocate enough memory for any size, but I chose to set a limit of "40" characters. Knowing the types that the identifiers of our language can have, we set up some token type constants, which help us identify "undefined", integer, real (float or double), string (including char's), logic (for bool expressions), array, pointer and function identifiers. I also defined "ways' of passing, allowing parameters to be passed by value or by reference (&).
To store the information/attributes about the identifiers, I had to define some structures. These are:
/* parameter struct */
typedef struct Param{
// parameter type and name
int par_type;
char param_name[MAXTOKENLEN];
// to store the value
int ival; double fval; char *st_sval;
int passing; // value or reference
}Param;
/* a linked list of references (lineno's) for each variable */
typedef struct RefList{
int lineno;
struct RefList *next;
}RefList;
// struct that represents a list node
typedef struct list_t{
// name, size of name, scope and occurrences (lines)
char st_name[MAXTOKENLEN];
int st_size;
int scope;
RefList *lines;
// to store value and sometimes more information
int st_ival; double st_fval; char *st_sval;
// type
int st_type;
// for arrays (info type), for pointers (pointing type)
// and for functions the (return type)
int inf_type;
// array stuff
int *i_vals; double *f_vals; char **s_vals;
int array_size;
// function parameters
Param *parameters;
int num_of_pars;
// pointer to next item in the list
struct list_t *next;
}list_t;The struct "list_t" is the main symbol table item, which builds up the Symbol Table. The struct "Param" is used in a dynamic array, to allow any number of parameters. The struct "RefList" is also a dynamic structure, but defined as a Linked List. Depending on the type of identifier, each element of these structs can have a different use. The best example might be "inf_type", which can work as the type of array or pointer, but can also work as the return type of a function.
The whole Symbol Table is being declared as :
static list_t **hash_table;
Note:I guess it's worth mentioning that I never really included anything related to pointers, cause back then they where not in my implementation list.
Right now, the implemented functions of the Symbol Table are:
- init_hash_table() -> which allows us to initialize the hash table
- hash() -> the hash function
- insert() -> which inserts an entry into the symbol table
- lookup() -> which gives back an entry
- lookup_scope() -> which gives back an entry in a specific scope
- hide_scope() -> which hides the current scope
- incr_scope() -> which let's us go to the next scope
- symtab_dump() -> which prints out what remained in the symbol table (mainly for testing purposes now)
Some of these functions have not been implemented right. First of all, why do I have two lookup functions? I don't know why either :P The good thing about the insert function is that it's almost perfect. When not thinking about scopes, this functions does a nice job. We will only have to check that variables with the same name and different scopes are not stored in the same scope.
So, let's get into all that scope and declaration checking stuff now...
Scope resolution
Inserting and accessing entries
The scope resolution can be done in the Symbol Table. Last time I already explained that the main or global scope will have the value '0' and that functions will have the value '1'. There is no other scope value that can exist right now! Knowing that we understand that the lookup function has to allow access to both '0' and '1' scope variables when inside of functions. When a variable with the same name occurs in both scopes, then only the variable of the current scope will be accessed. For the main function we always have a scope of '0' and there is no declaration of variables in any other scope, meaning that we can use the same code as before. But, when being inside of a function (scope 1), we will first take a look at scope '1' variables and if the variable is not one of them, then and only then we will get into global variables of scope '0'.This is quite easy to implement, cause we only have to insert the identifiers of scope '1' in the beginning of the list (something that we already did for all the new entries). That way the first entry that will be found in the symbol table, when searching for a specific entry, will always be the identifier/variable of scope '1'. If there is none, then we might also get into scope '0' variables. So, you can see that the lookup function doesn't really have to care about the scope! The current lookup function is completely right! What we have to change is the insert function, where we will only add a new entry when we are currently declaring and in a different scope. All this can be managed easily by a flag variable that has a value of '1' when declaring and '0' when not. Of course being in the same scope and declaring the same identifier again will cause a multiple declarations error!
So, the extended insert function is:
void insert(char *name, int len, int type, int lineno){
unsigned int hashval = hash(name);
list_t *l = hash_table[hashval];
while ((l != NULL) && (strcmp(name,l->st_name) != 0)) l = l->next;
/* variable not yet in table */
if (l == NULL){
/* set up entry */
l = (list_t*) malloc(sizeof(list_t));
strncpy(l->st_name, name, len);
l->st_type = type;
l->scope = cur_scope;
l->lines = (RefList*) malloc(sizeof(RefList));
l->lines->lineno = lineno;
l->lines->next = NULL;
/* add to hashtable */
l->next = hash_table[hashval];
hash_table[hashval] = l;
printf("Inserted %s for the first time with linenumber %d!\n", name, lineno);
}
/* found in table */
else{
// just add line number
if(declare == 0){
/* find last reference */
RefList *t = l->lines;
while (t->next != NULL) t = t->next;
/* add linenumber to reference list */
t->next = (RefList*) malloc(sizeof(RefList));
t->next->lineno = lineno;
t->next->next = NULL;
printf("Found %s again at line %d!\n", name, lineno);
}
/* new entry */
else{
/* same scope - multiple declaration error! */
if(l->scope == cur_scope){
fprintf(stderr, "A multiple declaration of variable %s at line %d\n", name, lineno);
exit(1);
}
/* other scope - create new entry */
else{
/* set up entry */
l = (list_t*) malloc(sizeof(list_t));
strncpy(l->st_name, name, len);
l->st_type = type;
l->scope = cur_scope;
l->lines = (RefList*) malloc(sizeof(RefList));
l->lines->lineno = lineno;
l->lines->next = NULL;
/* add to hashtable */
l->next = hash_table[hashval];
hash_table[hashval] = l;
printf("Inserted %s for a new scope with linenumber %d!\n", name, lineno);
}
}
}
}You can see that we use a new global variable called "declare". A value of '1' changes the behavior of the insertion function, cause it inserts a new entry and checks for the semantic error of "multiple declarations" only then. So, using a variable in a function without declaring it, meaning that we access the global scope '0', doesn't create a new entry!
The unchanged lookup function is:
list_t *lookup(char *name){
unsigned int hashval = hash(name);
list_t *l = hash_table[hashval];
while ((l != NULL) && (strcmp(name,l->st_name) != 0)) l = l->next;
return l;
}Hiding a scope
Last but not least, the "go to next scope" function is right, cause we only have to increment the cur_scope variable ( cur_scope++ ). But, the "hide_scope" function is unfinished, cause decreasing the cur_scope variable is not enough. We will also have to remove the entries for that scope from the symbol table. Having only two scopes, we only have to remove the entries for each function scope before getting into the next function.The hide_scope function looks as following:
void hide_scope(){ /* hide the current scope */
list_t *l;
int i;
printf("Hiding scope \'%d\':\n", cur_scope);
/* for all the lists */
for (i = 0; i < SIZE; i++){
if(hash_table[i] != NULL){
l = hash_table[i];
/* Find the first item that is from another scope */
while(l != NULL && l->scope == cur_scope){
printf("Hiding %s..\n", l->st_name);
l = l->next;
}
/* Set the list equal to that item */
hash_table[i] = l;
}
}
cur_scope--;
}To check if the scope resolution works as it should, we can simply add the scope to the dump file generation. It will be in the code on Github! Of course you will have to "comment out" the scope hiding to see all the entries, from all the functions. Doing that values greater than '1' will be possible! I will show you what comes out, by the end of this article...
Integrating with the Parser (Bison)
Nothing has to change in the Lexer or Flex. What we have to do is add some actions to the rules of the parser. More specifically we have to:- Manage the value of the variable "declare" to let the insert function know when we are declaring and when not
- Use the function "incr_scope" whenever we enter a scope
- Use the function "hide_scope" whenever we exit a scope, so that the entries of that scope get removed
declaration: { declare = 1; } type names { declare = 0; } SEMI ;and
parameter : { declare = 1; } type variable { declare = 0; } ;Pretty easy actually, cause we just have to set the value to '1' before getting into any ID and to '0' again after leaving the rule. This means that the first part could also come after "type" and so exactly before "variable". But, it is not that important I guess.
So, for the next two points now. Where exactly do we enter and leave a scope? That's even simpler! We do these things in the "function"-rule. Increasing just before the function_head and hiding the scope right after the function_tail is done! In code that looks as following:
function: { incr_scope(); } function_head function_tail { hide_scope(); } ;Compiler output for "full_example.c"
Compiling that example file we get: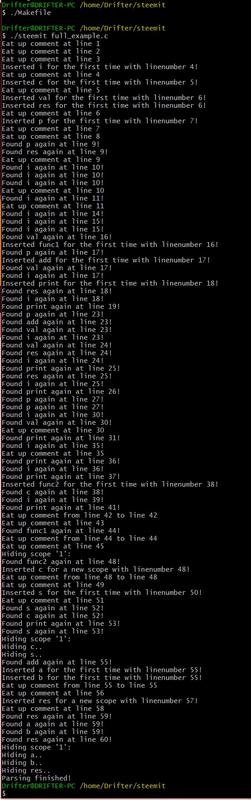
The symbol table dump file contains:
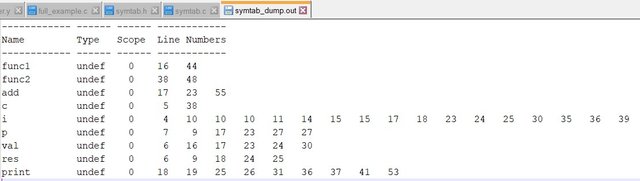
Commenting out the hide_scope function...

...we can get all the entries:
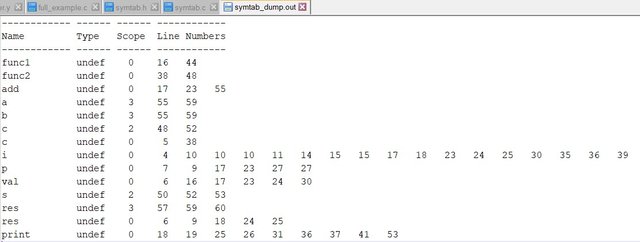
You can see that we get scope values greater than '1', but that was just for testing and so is fine! What matters is that the un-commented code works correct.
RESOURCES
References:
The following helped me refresh my knowledge around Symbol Tables:- https://www.tutorialspoint.com/compiler_design/compiler_design_symbol_table.htm
- http://jcsites.juniata.edu/faculty/rhodes/lt/sytbmgmt.htm
Images:
All of the images are mine!Previous parts of the series
- Introduction -> What is a compiler, what you have to know and what you will learn
- A simple C Language -> Simplified C, comparison with C, tokens, basic structure
- Lexical Analysis using Flex -> Theory, Regular Expressions, Flex, Lexer
- Symbol Table (basic structure) ->Why Symbol Tables, Basic Implementation
- Using Symbol Table in the Lexer -> Flex and Symbol Table combination
- Syntax Analysis Theory -> Syntax Analysis, grammar types and parsing
- Bison basics -> Bison tutorial actually
- Creating a grammar for our Language -> Grammar and first Parser
- Combine Flex and Bison -> lexer and parser combined
- Passing information from Lexer to Parser -> Bug Fix, yylval variable, YYSTYPE union, Setting up the Parser, Passing information "directly" and through the symbol table (special case) with examples.
- Finishing Off The Grammar/Parser (part 1) -> Adding the missing grammar rules, small fixes
- Finishing Off The Grammar/Parser (part 2) -> Operator priorities, precedencies and associativity, complete example file (for testing), grammar rule visualization, finish off grammar/parser
- Semantic Analysis Theory -> What is Semantic Analysis about, CSG and CSL, Attribute Grammars, Syntax Directed Translations (SDT)
- Semantics Examples -> Visualization of Semantics for different rules/cases, needed attributes, what we have to implement from now on
Final words | Next up on the project
And this is actually it for today's post! I hope that I explained everything as much as I needed to, meaning that you learned something out of it.Next up on this series are:
- Semantic analysis (creating and using even more semantic rules in bison)
- Intermediate Code generation (Abstract Syntax Tree)
- Machine Code generation (MIPS Assembly)
So, see ya next time!
GitHub Account:
https://github.com/drifter1
Keep on drifting! ;)
Another beautiful piece of work @drifter1
We just love seeing your progress on the compiler.
The compiler output was a bit difficult to read, a smaller screenshot or better resolution image would have been much better. Aside from that, nicely done!
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
Thank you for your review, @mcfarhat! Keep up the good work!
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @curie.
If you appreciate the work we are doing then consider voting both projects for witness by selecting stem.witness and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Hey, @drifter1!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Hi @drifter1!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your UA account score is currently 3.504 which ranks you at #6277 across all Steem accounts.
Your rank has improved 88 places in the last three days (old rank 6365).
In our last Algorithmic Curation Round, consisting of 490 contributions, your post is ranked at #76.
Evaluation of your UA score:
Feel free to join our @steem-ua Discord server
Hello! Your post has been resteemed and upvoted by @ilovecoding because we love coding! Keep up good work! Consider upvoting this comment to support the @ilovecoding and increase your future rewards! ^_^ Steem On!

Reply !stop to disable the comment. Thanks!