Curate like a Boss - A Beginner's Guide to Querying SteemSQL (by a complete SQL beginner)

Tutorial and example SQL queries for: @curie curation; returning posts from multiple tags/categories; and following "favorite authors".
To the Curie Curators
The @curie guidelines are really the impetus behind this post. When I first began looking into what it would take to become a @curie curator I quickly realized that it would take a lot of work and time! With no efficient way to filter out new posts by the @curie guidelines, finding a quality post that fits the bill is a lot like the proverbial search for a needle in a haystack. So I started teaching myself enough SQL to build a query that would do the job. I am still working on a few things but I think what I have provided here is a decent start, and as far as I know it is the closest thing out there to a Curie customized advanced search. I am sharing this with you in the Steemit spirit of giving. At the end of this post I talk about what I am still trying to add to this query - if you have a better grasp of SQL than me (and if you have any experience with SQL at all, you probably do) and want to help me get this query over the remaining hurdles, please DM me (@carlgnash on steemit.chat / @gnashster on discord chat).
To the technophobes
Some parts of this post may look intimidating, particularly the SQL queries themselves. I want to break down the process of using one of the pre-built queries for you. You will have to navigate downloading a freeware software program and filling in a few fields to connect the software to the SteemSQL database, with step-by-step instructions below. Then you will just paste one of the SQL queries I provide below into the software and press "execute". You will receive a list of all posts that meet the search criteria in return. That is it. There is absolutely no special knowledge of coding or anything technically demanding about using a pre-built SQL query to filter new posts.
Some thanks!
First many thanks to @arcange for creating and hosting the publicly accessible SteemSQL database and for help with my queries, and @drakos and @justyy for helping with my queries as well. Another thanks goes out to @stoodkev for pointing out a potential solution to the problem of filtering out posts that do not contain any English characters in the post body - check out @stoodkev / @steem-plus' Steemit browser extension SteemPlus - among other things it lets you filter (by tag/resteem/reputation) and sort the posts (by time/payout/votes) from your own feed.
Last but not least I want to thank @misterakpan for recommending me as a @curie curator and spending a lot of time talking over the curation process and the custom @curie sql query with me. You are truly a gentleman and a scholar, and I am proud to call you my friend.
Background
I have found myself wondering many times why the search function within Steemit.com is so lacking. Why isn't there an advanced search option with filters that you can apply? There are a few 3rd party tools out there on various websites but none that I have found with truly customizable search features. A while back I ran into Arcange's SteemSQL database and told myself I needed to learn SQL to be able to query the database myself and get what I wanted.
Just this past week I started diving into SQL tutorials online and looking at SQL queries built by other users to crib something together. It turns out SQL is pretty intuitive, at least on the basic level, and I was able to have some success. As an absolute SQL neophyte myself, I figured who better to write a guide for SQL beginners?
What is the SteemSQL database?
A publicly accessible SQL database that contains the information from the Steem blockchain and structures the information in a manner that allows fast querying by any application able to connect to a SQL server. The main benefits are twofold; first, SQL database queries are executed much faster than queries to the blockchain itself; and second, no real programming knowledge is needed to interface with the SQL database.
How do I connect to the SteemSQL database?
If you have Microsoft Excel you can connect to the SteemSQL database with Excel, and @arcange has provided step by step instructions on how to do this here (just stop following his tutorial at the step where he starts talking about creating charts out of the results of the query ). Assuming you do not have Excel, or don't want to use it for this purpose, you can use any number of freeware applications. I personally use LINQPad 5 and the rest of this tutorial will explain how to download LINQPad, connect it to the SteemSQL database and execute SQL queries to return results.
STEP ONE - Download and install LINQPad
- Download LINQPad 5 here and install (no you do not have to pay for the deluxe version, the freeware version will do everything we need so just select continue with the free installation).
STEP TWO - Connect LINQPad to SteemSQL
Once LINQPad has installed, open it and select the "Add connection" option at the top left:
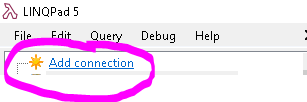
Fill in the information in the "Add connection" pop-up window exactly as follows:
- Select "LINQ to SQL" and click "Next" (this should be the default as shown below)
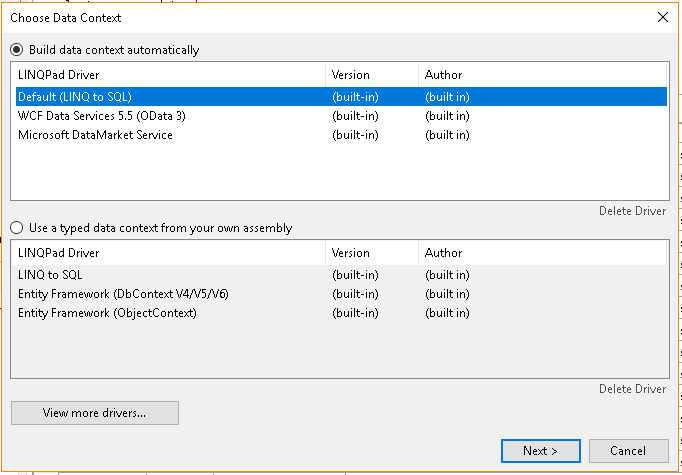
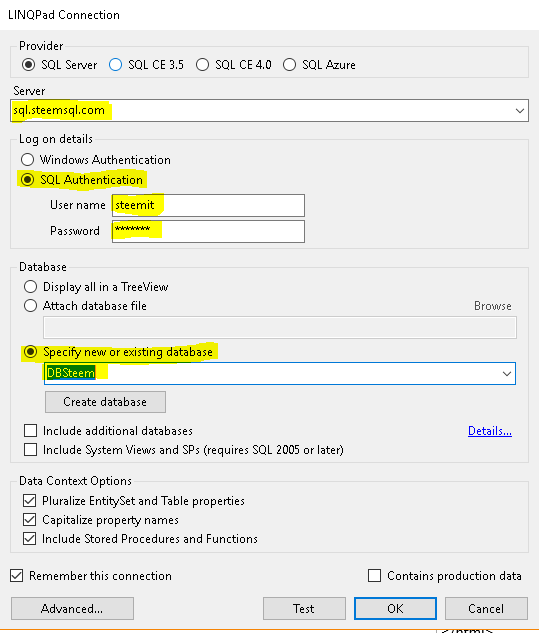
- At the next screen you will enter the following information where I have highlighted yellow, then press "OK":
Server: sql.steemsql.com
User: steemit
Password: steemit
Database name: DBSteem
STEP THREE - Execute a Query!
Pick one of the sample queries provided below and copy it into your clipboard. Paste the query into the LINQPad window where I have highlighted the text "PASTE YOUR QUERY HERE!". You will also need to select the query language (SQL) and connection (the connection you set up at the last step) from the drop down menus where I highlighted yellow:

Now just press the play icon (execute) or press the F5 key:
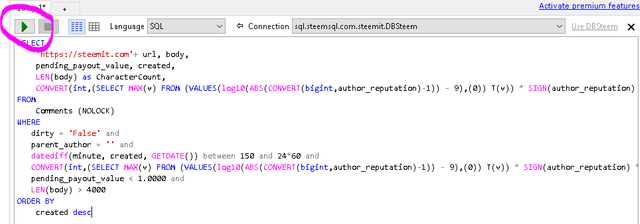
STEP FOUR - Enjoy the fruits of your query
It will take a few seconds for the query to run, then the results will appear below the query box:
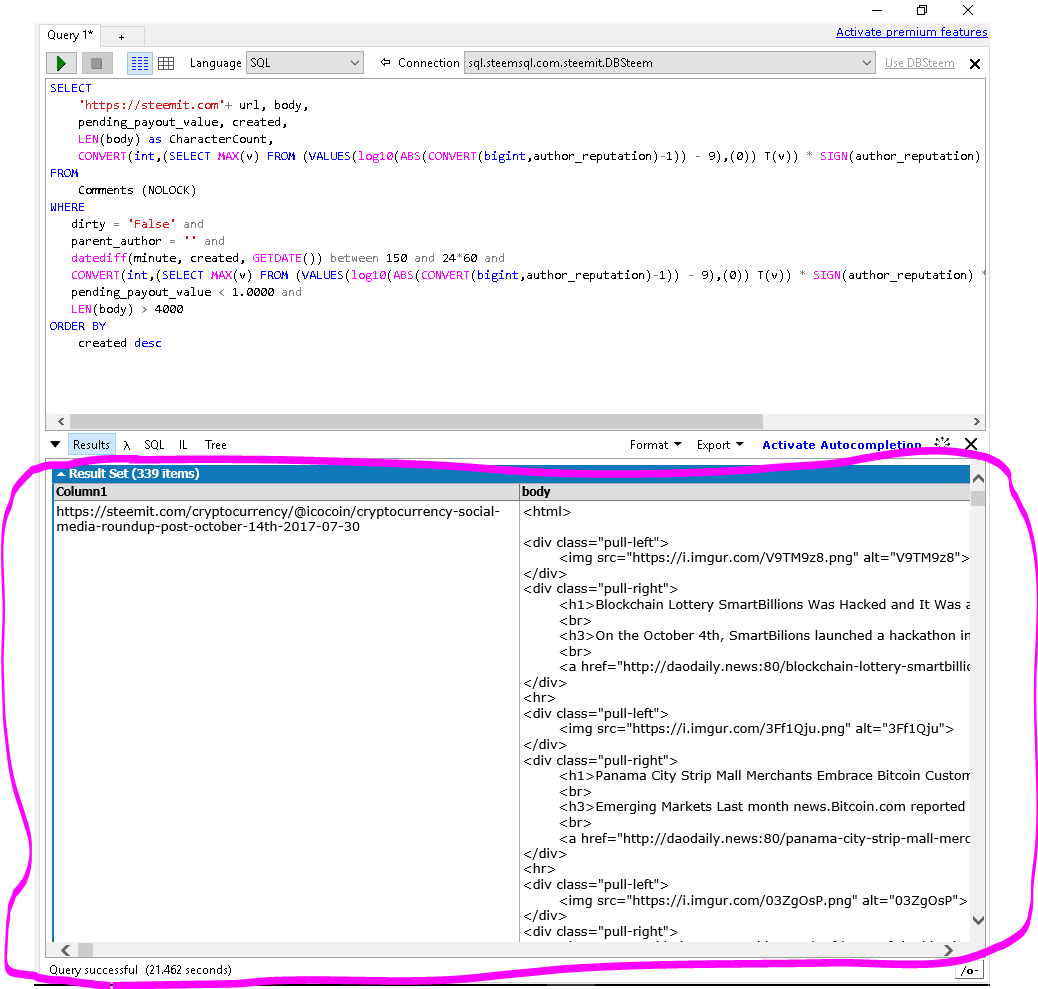
STEP FIVE - Save your query for future use!
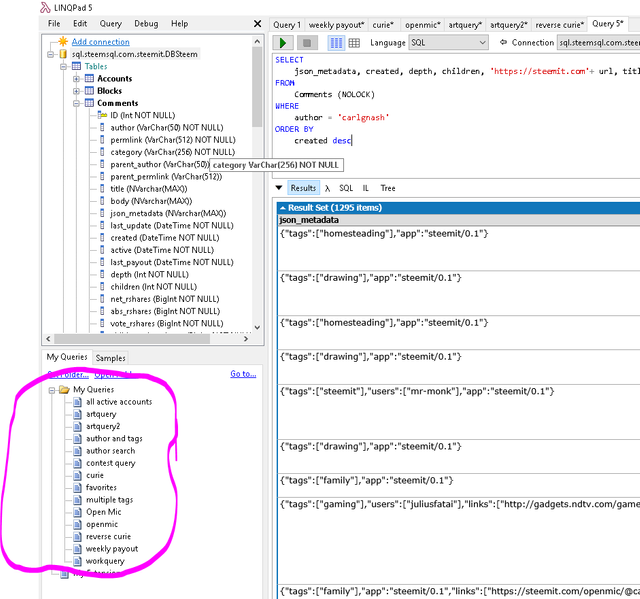
Before you close out of LINQPad, save the query you executed so you can use it in the future without having to paste it in again. File / Save, Ctrl-S or right-click and save. Once you have saved a query, it will appear under "My queries" toward the bottom left of the LINQPad window (circled in pink below). Simply click on a saved query to load it.
Example Queries
For each of the example queries below I will first present the default query then I will discuss what the various parts of the SQL query do and how to customize it. There are three lines present in all the queries that I will go over here for all:
dirty = 'False' and
This line excludes all posts that have been flagged. If you do not want to exclude flagged posts, remove this line.
parent_author = '' and
This line excludes comments. If you want to include comments as well as posts in your results, remove this line.
ORDER BY
created desc
This line orders the results by post age with newest posts first. "desc" stands for "descending"; if you want to see oldest posts first change that to "asc" (for "ascending") like so:
ORDER BY
created asc
You can choose other things from the queries to order the post by, using asc or desc to specify ascending or descending order for whatever you choose. For instance, to order posts by pending payout from least to most would be:
ORDER BY
pending_payout_value asc
Example @curie Curation Query
SELECT
'https://steemit.com'+ url, body,
pending_payout_value, created,
LEN(body) as CharacterCount,
CONVERT(int,(SELECT MAX(v) FROM (VALUES(log10(ABS(CONVERT(bigint,author_reputation)-1)) - 9),(0)) T(v)) * SIGN(author_reputation) * 9 + 25) as rep
FROM
Comments (NOLOCK)
WHERE
dirty = 'False' and
parent_author = '' and
datediff(minute, created, GETDATE()) between 150 and 24*60 and
CONVERT(int,(SELECT MAX(v) FROM (VALUES(log10(ABS(CONVERT(bigint,author_reputation)-1)) - 9),(0)) T(v)) * SIGN(author_reputation) * 9 +25) between 27 and 52 and
pending_payout_value < 1.0000 and
LEN(body) > 4000
ORDER BY
created desc
This query will return all new posts aged between 150 minutes and 24 hours, by authors with REP between 27 and 52, with pending post payout value less than $1, with no flags and with more than 4000 characters in the post body (including HTML). Things you can customize:
datediff(minute, created, GETDATE()) between 150 and 24*60 and
This line specifies the post age between 150 minutes and 24 hours. If you want to include posts aged as young as 45 minutes you would change the "150" to a "45" - if you want to include all posts up to one day old you would change the "150" to a "0" (posts aged 0 to 24 hours).
CONVERT(int,(SELECT MAX(v) FROM (VALUES(log10(ABS(CONVERT(bigint,author_reputation)-1)) - 9),(0)) T(v)) * SIGN(author_reputation) * 9 +25) between 27 and 52 and
This scary looking line specifies author REP between 27 and 52. Look for the numbers 27 and 52 at the end of the line - change these numbers to change the REP filter.
pending_payout_value < 1.0000 and
This line is pretty self-explanatory and specifies pending post payout value less than $1. Adjust the number after the < symbol to change this but make sure to keep the number in X.XXXX format - e.g. pending_payout_value <0.5000 would only return posts with less than $.50 pending post payout.
LEN(body) > 4000
This line specifies only posts with more than 4000 characters in the post body. Change the number after the > symbol to adjust this filter. Normally 4000 characters is about 500 words, but remember that the query will count the HTML characters that format the post body as well; in my experience having used this query for a few days I think 4000 is a good minimum. If you do not want to filter by post length at all just change the "4000" to a "0" to include all posts.
Example Query for Multiple Tags/Categories
SELECT
'https://steemit.com'+ url, body,
pending_payout_value, created,
CONVERT(int,(SELECT MAX(v) FROM (VALUES(log10(ABS(CONVERT(bigint,author_reputation)-1)) - 9),(0)) T(v)) * SIGN(author_reputation) * 9 + 25) as rep
FROM
Comments (NOLOCK)
WHERE
dirty = 'False' and
parent_author = '' and
category IN ('poetry', 'fiction', 'writing') and
datediff(hour, created, GETDATE()) between 0 and 7*24 and
CONVERT(int,(SELECT MAX(v) FROM (VALUES(log10(ABS(CONVERT(bigint,author_reputation)-1)) - 9),(0)) T(v)) * SIGN(author_reputation) * 9 +25) between 25 and 100 and
pending_payout_value < 9000.0000
ORDER BY
created desc
This query as written will return all posts from the past week that have at least one of the following tags: #poetry; #fiction; #writing, from authors with 25+ rep. Insert your own tags/categories by editing this line:
category IN ('TAG1', 'TAG2', 'TAG3', 'TAG4ETC') and
Make sure you have single quotes around each tag ('example') and include a comma after each tag except the last tag.
datediff(hour, created, GETDATE()) between 0 and 7*24 and
This line specifies post age - this is in hours, so to see posts between 6 and 12 hours old you would adjust this to:
datediff(hour, created, GETDATE()) between 6 and 12 and
You can change the time unit to days like so (the below would return all posts aged 0 to 30 days):
datediff(day, created, GETDATE()) between 0 and 30 and
CONVERT(int,(SELECT MAX(v) FROM (VALUES(log10(ABS(CONVERT(bigint,author_reputation)-1)) - 9),(0)) T(v)) * SIGN(author_reputation) * 9 +25) between 25 and 100 and
This line controls the author REP parameter - as written this would return posts by authors with REP between 25 and 100, which effectively means REP 25+. If you want to specify a different range of author REP just adjust the numbers at the end of this line, e.g. to only see posts by authors with REP between 25 and 50:
CONVERT(int,(SELECT MAX(v) FROM (VALUES(log10(ABS(CONVERT(bigint,author_reputation)-1)) - 9),(0)) T(v)) * SIGN(author_reputation) * 9 +25) between 25 and 50 and
pending_payout_value < 9000.0000
This line specifies only posts with pending payout less than $9000 - so effectively this is including everything. I included this line so you could adjust it if you did want to filter for posts by pending payout. If you change this number make sure to keep it in the format X.XXXX with four decimal places. To only include posts with less than $5 payout:
pending_payout_value < 5.0000
To included posts with pending payout between $.50 and $1:
pending_payout_value between 0.5000 and 1.0000
Example Query to Follow Favorite Posters
SELECT
'https://steemit.com'+ url, body,
created
FROM
Comments (NOLOCK)
WHERE
parent_author = '' and
datediff(hour, created, GETDATE()) between 0 and 7*24 and
author IN ('crimsonclad', 'vachemorte', 'buckydurddle', 'yusaymon', 'juliakponsford', 'stickchumpion', 'stitchybitch', 'jrhughes', 'clayboyn', 'aggroed', 'sircork', 'sammosk', 'spaingaroo', 'tremendospercy', 'gmuxx', 'misterakpan')
ORDER BY
created desc
This query returns all posts created in the past week by some of my favorite Steemit posters - give it a run and enjoy some terrific posts! You can thank me later :) I wrote this query because I have always wished that Steemit had a way to "favorite" someone you were following so that you would always see their posts - I am adding my favorites to this query so I can run it and see all their recent posts. To my friends, don't be offended if you don't see yourself in the above query - it is most likely operator error, I am still adding folks to this list and I know I am still forgetting some people that I definitely want to be on there!
To create your own version of a favorite poster query, just edit this line to include your own favorite posters. Do NOT include the "@" symbol in front of the user name, make sure to enclose each name in single quotes (like so: 'username') and remember to put a comma after each name except for the last one:
author IN ('carlgnash', 'favoriteposter2', 'favoriteposter3ETC')
datediff(hour, created, GETDATE()) between 0 and 7*24 and
This line specifies post age - this is in hours, so to see posts between 6 and 12 hours old you would adjust this to:
datediff(hour, created, GETDATE()) between 6 and 12 and
You can change the time unit to days like so (the below would return all posts aged 0 to 30 days):
datediff(day, created, GETDATE()) between 0 and 30 and
You can remove this line entirely if you want to see all posts by your favorite authors.
What I am still working on for the @curie query
There are two more big things I want to accomplish with the @curie curation query:
- Filter by sum of past week's pending author payout (e.g. only include posts where the author has less than $25 pending post payout for all posts in the past week). This would both take care of the requirement that the author not have received a @curie vote in the past week, and would help exclude authors who are making too much money on their posts to qualify as "persistent without much success". I don't think this should be terribly hard but I am still figuring out how to nest the WHERE statements properly.
- Filter out posts that do not contain any English characters in the post body (to satisfy the English language requirement). This one is kind of tricky as the HTML that formats the post body is included in the post body column in the SteemSQL database. @stoodkev pointed out that I could use regex to strip the HTML and other formatting characters out first, then exclude the post if no English characters remain in post body. @stoodkev gave me the regex I will need to accomplish this, but I still need to build it into the query and test it.
I am not kidding when I say that I literally just started teaching myself SQL within the past week. I learn quickly and have already grasped a lot compared to where I was at when I first poked my head in the SteemSQL help chat on steemit.chat... but I am still very much a SQL novice. If you are a SQL master and can help me take care of these last two items and add them into the @curie query I would certainly be grateful for any help!
Much love - Carl

"Upvote Follow Resteem" lettering by @dillemma | color by @carlgnash
This post, like a number of others that I have recently seen, make me want to cry! You see, I am an experienced programmer (though with just a little bit of experienced using SQL inside SAS) and when I look at what you’ve done and then scroll down to see a payout off $16.35 I really want to weep. What’s more you even had 274 views. This is ridiculous!
The reward system in Steemit may never change, so let us thank God that there are authors who are prepared to do good work and not worry about the fact that their cash reward is a couple of cups of coffee at Starbucks.
BTW -- I do not mean to beat upon the designers of the reward system; but it is evident that it was set up in such a way that it becomes extremely difficult for people in particular areas of technical expertise to have the value of what they produce properly recognized in the system. For one thing, these people are not going to have hordes of Followers and only the geeks among the Whales will be able to identify good value when it is staring them in the face.
What’s more, while it is evident that to succeed here you need those hordes of followers and you need to cultivate a relationship with certain Dolphins and Whales (none of which is problematic when you remind yourself that this is at the core a social network), there is no professional specialization that I know about where productive people would be able to afford to spend their time this way!
Why am I crowing about this piece so much? I read about this linkage to an SQL server which gives you a chance to look at everything on the block chain several days ago, and I decided that I would get on with doing that because of the particular analyses that I wanted to do. I took a quick look at the available help and thought that it wasn’t great -- that is I would probably have to jump through a few hoops to get the whole thing working. But now here comes this wonderful post which has all the steps laid out at my feet.
Good show @carlgnash!
Hey thanks! I have to give you points for your user name, that is genius ;) Glad this was useful to you, and while I get your general point (and I consider quite a few of my posts to be criminally underpaid), in this case the work was definitely its own reward. I am having a blast poking around at the data contained in the blockchain and my understanding of the entire beast has deepened so much since the beginning of this undertaking. Obviously I wouldn't be spending as much time as I did on a post like this for the reward - even if it were to get up into the low 3 digits it wouldn't be a very good hourly wage LOL Cheers - Carl
Agreed that the work is its own reward. However, there are other writing venues where the reward system is set to provide decent focus to non-dollar factors.
Here, when I finish reading the ton of stuff now posted on the reward system, I'm almost made to feel badly that I have no desire to play a game in which I might struggle for days to produce good 'green' content, watch it disappear into 'ether' 20 minutes after I upload it, and find out days later that almost nobody saw it! This is not a good picture, Carl.
Hey I meant to reply to you earlier but my thoughts were still kind of gelatinous and oozing around and I couldn't quite crystallize my response. My first reaction was, this is kind of a curmudgeonly attitude but the more I thought about it the more I have to admit you do have a valid point. I can point to many posts of mine that actually received a very good reward for the time I spent making them, but in every case they were art or music posts. Art and music are much easier for a broader swathe of users to appreciate - they are as close to universal as anything is with humanity. A tutorial post on the other hand takes an insane amount of time but is hardly appreciated. A literally insane amount of time. Unless you have actually tried to break a process down into its component parts and outline them step by step with illustrations, you really don't have a clue how long that process takes. On the encouraging front, at least utopian.io is now properly rewarding posts like this. I just came along too soon with this. That is one of the beautiful things about the Steem ecosystem is that solutions to problems can and will just arise because it provides the basic mechanisms and the potential combinations and applications are only limited by the nearly limitless imagination and creative genius of the early adopters who are congregated here.
Thanks for your comment, @carlgnash.
@carlgnash great work.
I run my query successfully. I was wondering if there is any way to filter out / exclude, some tags, such as 'aceh', or 'chinese' etc?
sure, I actually just added this filter to the query I am using myself last night and was going to include it in a future update to this post. To exclude something we will use the "NOT" operator: add this in after the WHERE statement:
above I have excluded categories that are not allowed in the guidelines (introduceyourself/myself and religious posts) as well as cn and aceh (mostly foreign language posts) and meme (mostly memes LOL). You can add others to exclude of course but I found that just excluding these already made a big difference as far as getting rid of chaff in the search results. Thanks for the question and I am glad you were able to follow my instructions and run the query! Cheers - Carl
to add more categories to exclude just make sure to enclose them in single quotes (example: 'categoryname') and to include a comma after each category except the very last one before the closing parenthesis.
Brilliant!! Thanks a lot :)
Great work, and you re very welcome!
Thanks and thanks for the tip - it seems like the regex should do the trick, just haven't had the time to try to impliment this yet. Cheers! - Carl
@carlgnash is there no limit to your powers??? This is excellent info. I have been struggling with the "New" category on Steemit. I want to find new exciting Steemians, but that "new" category was sucking the life out of me. Tomorrow (Sunday) I will be implementing your instructions. I will set this up to let me search for those nuggets of Steemian diamonds in the rough :)
No, no there is no limit. Hop on board Bucky I will fly you to the moon!
Feel free to DM me if you run into any sticking points or need help customizing a query. I think you are really going to like playing around with this for curation, it really has made a big difference for me already for the Curie curation.
a really interesting way to approach the curie issue... I am afraid I cannot help you on SQL.
But basically what you are doing is very logical...
there are thousands of posts per day and looking through them is indeed like looking for a specific needle in a whole lot of needles and what you are trying to do is make the needlestack smaller
thumbs up for trying to make your life easier
I love the way you phrased this! Yes, this is exactly what I was trying to do - make the needlestack smaller! I pretty much realized right away that either I was going to figure out a way to filter the posts, or I was going to fail at Curie curation because I just don't have the time required to sift through every post manually. Cheers - Carl
This is very good info, I will discuss with you about my requirement of a query for my caption contest. May be you can build something that can be used by all contest creators.
Hey @sanmi that is a terrific idea and would be very easy to implement, this is well within my burgeoning SQL capabilities. DM me on Discord I would like to hear if you have any special requirements or requests for this kind of query, but I think I already just worked out how to do the basic query for contest entries in my head.
Congratulations. This post is featured in today's Muxxybot Curation post.https://steemit.com/curation/@muxxybot/muxxybot-curation-32
this looks way complicated with all the coding in there. while i love your subjects, they intimidate me a little in their complexity and breadth. i'm interested in adding this program but ima look at it a bit more in comparison to the way im currently doing curie. or not doing curie...
Yeah there is certainly the intimidation factor when you look at a line like this:
Honestly if you don't have a specific use case (like Curie curation in my instance) it might not make a lot of sense to use SQL query, although I personally am already in love with the "favorite posters" query and it will keep me up to date on my favorite Steemiters much better than my feed which is clogged with a lot of crap. I was never a "follow for follow" guy but I have followed an awful lot of people and without something like this I just miss posts from my friends all the time.
If you do end up thinking it makes sense to dig into SQL deeper, feel free to DM me (I know you would anyway). Much love - Carl
it isnt that so much as that i have another system. i cant deal with the feed its nice to check at a given moment but to curie from there is dikulous. i have a bunch of people on notify and a bunch bookmarked but not sure its a smart way
Good post, and well done for teaching yourself some SQL. Once the new Hivemind DB is up and running you'll be able to apply it to that too :)
Hivemind DB... that sounds very intriguing! Is this a new project of yours Andy? Do tell! I am fascinated with hive mind both in the sci fi / telepathic / communal intelligence and also with the real world group level intelligence demonstrated by social insects. Excellent name for a DB!
It is an interesting name for the reasons you mentioned, but it's not my project, just one I'm very interested in:
https://steemit.com/steem/@furion/upcoming-hive-db
They have hit a bug when loading data from the blockchain though, so not sure when it will be fixed and ready.
Oh that looks really useful! From what little I have learned about SQL, it also seems like it is a good thing that it is MySQL
Dude!
I would be tempted to add #bisteemit as a tag and perhaps remove umm curie?
Awesome stuff, I have bookmarked and 100% voted and there's more on the way. Great work!
oh I assumed the curie tag would be okay since this is pretty much built for curie curators but following your suggestion for now - removed curie and added bisteemit. Can you elaborate on why you said that RE the tags?
the bisteemit tag I know is checked by people doing similiar stuff to you - I have a feeling you'll be getting some interest from their soon.
Wasnt sure which tag to swap it with (out of the 4 you are able to, not the first). maybe click them all and see what the level of action is
Cheers
Asher