Die Rettung der Gesundheit? Wie gelange ich zur Wahrheit?
Liebe Community,
es wird allmählich Zeit für den finalen Akt in meiner Reihe „Rettung der Gesundheit“. Ursprünglich war es wie gesagt eine Reply von @lauch3d, die mich dazu bewegt hat etwas darüber zu schreiben, doch mittlerweile hat es sich zu einem wahren Gemeinschaftsprojekt entpuppt. Warum? Nun, weil die Resonanz derart gewaltig und die Replys derart konstruktiv waren, dass man eigentlich immer weiter machen könnte. Gerade bei den letzten beiden Artikeln zum Thema gab es viele interessante Hinweise, auf die ich nach und nach noch eingehen möchte. Beginnen möchte ich mit einer Reply von @sco, die hervorragend entscheidende Aspekte vorweggenommen hat, die ich im heutigen Post behandeln wollte. Der Kommentar von @sco war folgender:
2 Quellen die auf einen Zusammenhang hindeuten sind natürlich noch nichts. Da braucht es noch wesentlich mehr Forschung (wie immer^^), um die Zusammenhänge besser raus zu arbeiten…
Ja ganz richtig. Was sind eigentlich zwei Quellen? Was sagen die überhaupt aus? Was ist, wenn es stattdessen 20 Quellen wären? Hätten die dann mehr Gewicht? Das Fazit des letzten Artikels kann im Wesentlichen so zusammengefasst werden:
Die Zelle ist ein hoch-komplexes Gefüge, dass nicht anhand von einzelnen Parametern vollständig erklärt werden kann!
Aber wie soll man denn eine Zelle erklären? Was soll man Leuten sagen? Wie kann man zumindest ermessen was eigentlich ganz gut oder besonders schlecht wäre?
Die Antwort darauf ist: Statistik!
Zunächst sei folgendes Zitat genannt, welches anscheinend fälschlicherweise Winston Churchill angedichtet wird:
Traue keiner Statistik, die du nicht selbst gefälscht hast.
Jaja, die liebe Statistik. Fluch und Segen der Wissenschaft und eigentlich vom ganzen Rest auch. Vor Beginn des 20. Jahrhunderts gab es sowas übrigens gar nicht wirklich. Die großen Entdeckungen bis dahin kamen gänzlich ohne Statistik aus. Das bedeutet Newton und wie sie alle hießen war Statistik völlig egal!
Erst unser aller liebstes Getränk führte zum Siegeszug der Statistik. Die Rede ist von Bier. Ja richtig gehört, wegen Bier wurde Statistik erstmals wirklich wichtig.

Abb.1 Da lässt es sich doch schön einkehren oder? Quelle Pixabay
Wir schreiben das Jahr 1908. Die Guinessbrauerei hat ein paar Probleme. Sie braucht köstliches Getreide, aber leider sind die Preise hoch, der Markt umkämpft, die Qualität der Ressourcen mangelhaft und das Geld knapp. Alles wie immer also. Da es sich die Brauerei nicht leisten kann irgendwelches Getreide zur Herstellung des leckeren Guiness zu verwenden, muss sie versuchen vorauszusagen, welches Getreide von welchem Bauern oder Lieferanten die beste Qualität hat. Natürlich kann man nun nicht zig Chargen an Getreide holen. Besser wäre es einen Test zu entwickeln, welcher halbwegs zuverlässig den besten und beständigsten Lieferanten ausfindig macht. Das Problem: so einen Test gibt es nicht! Ein junger talentierter Chemiker namens William Sealy Gosset wurde daher damit beauftragt einen Weg zu finden so eine Beurteilung durchzuführen. Glücklicherweise waren seit Gauß schon einige mathematische Grundlagen für statistische Betrachtungen ausgearbeitet wurden und so konnte Gosset sich an dem Wissen über die sogenannte Normalverteilung bedienen.
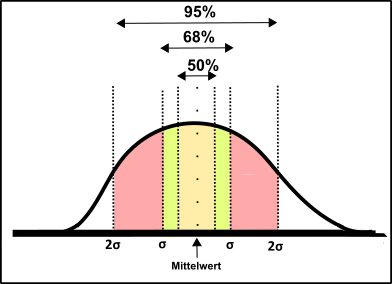
Abb.2 Die Normalverteilung. Made by Chapper - unrestricted use allowed
Damit etwas als normal-verteilt gilt müssen bestimmte Kriterien erfüllt sein. Dazu gehört, dass die einzelnen Datenpunkt nur in bestimmter Weise um den Mittelwert streuen dürfen. Der Mittelwert ist die Summe aller Daten dividiert durch deren Anzahl. Die Streuung um diesen Mittelwert wird auch als Standardabweichung σ bezeichnet. Die Standardabweichung ist somit ein Maß für die „Ausbreitung“ der Datenpunkte um den Mittelwert. In der Guinessbrauerei würde dies bedeuten, dass z.B. die Menge an Malz, welche aus einer Tonne Gerste eines Lieferanten extrahiert werden kann, über die Gesamtheit aller Stichproben nur so stark schwanken sollte, dass sich etwa 68% aller Datenpunkte innerhalb der Standardabweichung (also 1xσ) um den Mittelwert herum befinden. 95% der Datenpunkte sollten innerhalb der doppelten Standardabweichung (also 2x σ) auffindbar sein.
Zum näheren Verständnis schaut euch die nächste Abbildung an.
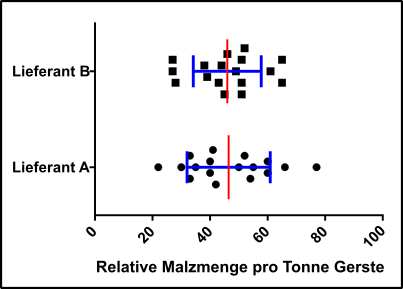
Abb.3 Hypothetische Daten zweier Lieferanten (schwarze Vierecke und Punkte), sowie der Mittelwert (rot) und die Standardabweichung σ (blau). Mehr als 70% aller Daten liegen in beiden Fällen innerhalb von σ, daher ist grundsätzlich die Voraussetzung einer Normalverteilung erfüllt. Made by Chapper - unrestricted use allowed
Prinzipiell ist es sehr praktisch, wenn eine Erhebung von Daten einer Normalverteilung folgt, denn dies ermöglicht eine „weniger störanfällige“ Beurteilung von Wahrscheinlichkeiten. Alle anderen Verteilungen erfordern zusätzliche mathematische Spielereien, sind demnach also komplexer.
Weiterhin muss beachtet werden, dass zum Beispiel stark „verrauschte“ Daten oft mit mangelhafter Datenerhebung in Zusammenhang stehen könnten und somit weitere statistische Beurteilungen von vornherein in Zweifel ziehen könnten.
Ok, zurück zum Thema. William Sealy Gosset hat also die Malzausbeute aus Gerste von verschiedenen Lieferanten untersucht und wollte nun wissen von welchem Lieferanten das beste Getreide oder die beste und konstanteste Qualität stammt.
William Sealy Gosset könnte also (so genau weiß ich das nicht, hab‘ das Paper nie gelesen) eine Hypothese aufstellt haben, die zum Beispiel lautet:
„Es gibt keinen Unterschied zwischen Lieferant A und Lieferant B“.
Diese Hypothese wird auch als Null-Hypothese oder H0 bezeichnet. Demgegenüber kann eine Alternativhypothese HA formuliert werden, die dann zum Beispiel besagt:
„Es gibt Unterschiede zwischen Lieferant A und B“.
Es ist aber wichtig zu verstehen, dass beim Verwerfen einer Hypothese KEIN Beweis erbracht wurde, dass die Hypothese tatsächlich falsch ist. Es ist lediglich ein Indiz dafür!
Um zu klären ob man eine Hypothese verwerfen sollte muss u.a. folgendes beachtet werden:
- Wenn eine Hypothese von beiden simpler gestrickt ist, so ist die kompliziertere zu verwerfen, falls es nicht genug eindeutige Belege für deren potentielle Richtigkeit gibt
- Wenn Unterschiede nur sehr gering ausfallen, dann sollte man besser davon ausgehen, dass es keinen Unterschied gibt.
- Die Nullhypothese ist erst bei Vorhandensein starker statistischer Belege für die Alternativhypothese zu verwerfen.
Will man nun einen t-Test anwenden ist folgendes wichtig:
- Man muss festlegen ob es ein gepaarter oder ungepaarter Test sein soll. Gepaarte Tests könnte man zum Beispiel dann verwenden, wenn zwei Lieferanten quasi in direkter Competition sind. Also zur gleichen Zeit, die gleiche Saat, auf der gleichen Feldgröße ausbringen. Diese Saat gleich düngen, gleich bearbeiten, gleich ernten, zur gleichen Zeit die gleiche Menge einschicken etc. Natürlich ist es nicht denkbar, dass das so abgelaufen ist, deshalb hat William Sealy Gosset wahrscheinlich einen ungepaarten Test angewandt.
- Als nächstes muss sichergestellt werden, dass die Stichproben zufällig sind. Eine Vorauswahl würde das Ergebnis verfälschen. Ich gehe jetzt mal davon aus, dass die Daten nicht manipuliert wurden.
- Es ist weiterhin erforderlich, dass die Stichproben normalverteilt sind. Dies ist in Abb.3 der Fall.
- Zusätzlich darf der Umfang der beiden Stichproben nicht zu stark schwanken. Der Umfang der Stichproben muss vergleichbar sein. Also ihr dürft z.B. von Lieferant A nicht nur 10 Proben mit 100 Proben von B vergleichen. Das sollte mehr oder weniger einheitlich sein. Da wir von beiden Lieferanten die gleiche Anzahl an Stichproben haben, ist also alles prima.
- Wenn wie in unserem Falle der Stichprobenumfang sehr gering ist, dann sollte die Standardabweichung beider Lieferanten vergleichbar sein. Der Stichprobenumfang ist zwar gering, aber σ ist in beiden Fällen vergleichbar, dies passt also auch.
- Darüber hinaus muss festgelegt werden ob man einen sogenannten einseitigen oder zweiseitigen Test durchführen möchte. Einseitige Tests werden zum Beispiel durchgeführt, wenn man die Richtung des Ergebnisses schon kennt, also zum Beispiel weiß, dass der eine Lieferant schlechtere Chargen bringt, weil er diese immer im Regen liegen lässt oder so. Generell verwendet man aber zweiseitige Test da man unvoreingenommen an die Sache herangeht.
- Außerdem sollte vorher definiert werden wann man eine Hypothese behält oder verwirft.
Der letzte Punkt ist tatsächlich so eine Sache, wie ich finde. Ich denke es hängt stark von der Datenlage ab. Im obigen Fall (Abb.3) sind die Werte beider Lieferanten fast vergleichbar, d.h. ich würde die Grenzen so eng wie möglich fassen. Man muss sich für ein Signifikanzniveau entscheiden, welches entscheidet wie vertrauenswürdig die Unterschiede prinzipiell sind. Dadurch ergibt sich der sogenannte P-Wert, den wir auch schon aus dem letzten Post kennen. Der P-Wert (P für Probability also Wahrscheinlichkeit) ist quasi die Schwelle, die festgelegt wird um zu erkennen wann man dem Test noch traut bzw. die Hypothese ablehnt.
Das Problem ist nämlich folgendes:
Es kann passieren, dass wir eine Nullhypothese fälschlicherweise ablehnen. Also einen Unterschied sehen der eigentlich gar nicht da ist. Dies wird als Fehler 1. Art bezeichnet. Umgekehrt kann es aber auch sein, dass man keinen Unterschied sieht, es aber tatsächlich einen gibt. Das ist ein sogenannter Fehler 2. Art. Ein Fehler 2. Art ist für die Wissenschaft aber nicht so schlimm wie ein Fehler 1. Art, weil durch einen Fehler 1. Art der Gemeinschaft ein Effekt suggeriert wird, welcher sich weiterverbreitet und viel Schaden anrichten kann. Fake-News also. Hätte man einen Fehler 2. Art begannen gäbe es zumindest keine Fake-News, sondern man würde erstmal dastehen wo man vorher auch schon war, es bleibt gewissermaßen beim Alten. In Firmen ist das natürlich auch tragisch, denn dann würde die Guinessbrauerei minderwertige Gerste einkaufen und ggf. viel Geld verlieren, dies wäre ihr aber auch bei einem Fehler 2. Art passiert. Der Fehler 1.Art ist daher vor allem für Wissenschaftler eine Katastrophe. Wir wollen einen Fehler 1. Art daher so effizient wie möglich vermeiden und deshalb sagen wir, dass wir quasi bis zu einer „Wahrscheinlichkeit" von 1% dazu bereit wären Störeinflüsse zu akzeptieren. Also z.B., dass Messeinflüsse letztlich das Verwerfen einer Null-Hypothese verhindern.
Man kann dann, mittels den Mittelwerten beider Lieferanten, sowie dem Standardfehler (= Standardabweichung bezogen auf den Stichprobenumfang) nun das t berechnen (Keine Ahnung für was t eigentlich steht). Weiterhin müsst ihr noch die Freiheitsgrade eurer Testung bestimmen, die sich vom Stichprobenumfang ableiten. Je mehr Stichproben, desto mehr Freiheitsgrade.
Mit dem t das ihr berechnet habt, den Freiheitsgraden die ermittelt wurden und dem Signifikanzniveau welches festgelegt wurde, könnt ihr in speziellen Tabellen mit kritischen Werten für den t-Test ablesen ob es einen Unterschied gibt oder nicht.
Der kritische t-Wert für meine Untersuchung liegt bei 2.567, da mein t aber 0.107 hat bin ich weit von einer Signifikanz entfernt. Tatsächlich beläuft sich der P-Wert auf hammerharte 0.918.
Es ist also für die Guinessbrauerei egal welchen Lieferanten sie nimmt.
Zugegeben dieser Fall war recht klar und eigentlich hätte man es auch schon anfangs erkennen können, dass es keine Rolle spielt welcher Lieferant jetzt die Gerste bringt. Der t-Test ist übrigens einer der einfachsten statistischen Tests, den ihr machen könnt. Als der Test entwickelt wurde und sich als funktionell entpuppte, wollte William Sealy Gosset ihn veröffentlichen was aber wegen Betriebsgeheimnissen der Guinessbrauerrei etc. nicht so einfach war. Aus diesem Grund hat William Sealy Gosset sich das Synonym „Student“ gegeben, weshalb der t-Test heute auch Students t-Test heißt.
Ich persönlich finde, dass dieser Test eine geniale Leistung ist und William Sealy Gosset wohl eines der großen Genies des 20. Jahrhunderts darstellt, denn immerhin wird sein Test nicht nur bis heute angewandt, nein viele weitere Tests wurden konzipiert, die sich womöglich an diesem Vorbild orientierten.
Ich habe bereits erwähnt, dass die Wissenschaft vor dem 20. Jahrhundert nahezu ohne solche Spielereien auskam. Aber warum? Waren die Wissenschaftler damals einfach besser als die Wissenschaftler von heute und haben exakter gearbeitet, sowie klare Hypothesen formuliert und Beweise generiert? Ich persönlich denke, dass die Wissenschaft einfach wesentlich komplexer geworden ist. Die Verarbeitung großer Datenmengen wäre ohne Statistik beispielsweise niemals möglich. Leute wie William Sealy Gosset haben demnach die Tools entwickelt, um der Wissenschaft des 20. Und 21. Jahrhunderts überhaupt die Möglichkeit zu geben sich in der Form zu entwickeln. Für mich ist William Sealy Gosset deshalb ein Jahrhundert-Genie. Keine Frage!
Leider gibt es natürlich auch zahlreiche Probleme mit diesen Sachen. Zum einen ist es sehr schwierig alle Details perfekt zu verstehen, dann ist es weiterhin eine Herausforderung die Testungen richtig einzusetzen. Darüber hinaus kommt zum anderen auch oft zu mehr oder weniger gezielter Datenmanipulation.
Um dies etwas näher zu beleuchten und einen Turn hin zu den Telomeren zu erhalten, habe ich eine kleine Fantasy-Studie entworfen. Im Artikel von Samassekou et al. 2010 sind einige Werte bzgl. Telomerlänge aufgeführt [1]. Die Telomerlänge schwankt zwar ganz klar in Abhängigkeit vom Zelltyp, Alter, Belastung etc. (Wir gehen da im nächsten Artikel genauer drauf ein. Es tut mir leid, aber ich habe mich mal wieder total verzettelt). Ich lege, da ich ungefähr weiß in welchen Dimensionen wir unterwegs sind, die Telomerlänge in Lymphozyten von Erwachsenen auf etwa 10 kb fest (das sind 10,000 Basenpaare!). Lymphozyten eignen sich für solche Untersuchungen aus mehreren Gründen hervorragend: 1. Sind diese Zellen als Bestandteil des Immunsystems immer direkt am Geschehen beteiligt, 2. verfügen sie über Telomeraseaktivität und 3. kann man die einfach durch Entnahme von Blut aus den Probanden erhalten.
Meine Fantasy-Studie sieht nun wie folgt aus: Ich möchte herausfinden ob es einen Einfluss auf die Telomerlänge hat, wenn ich statt Facebook Steemit nutze. Aus diesem Grunde schnappe ich mir 50 Probanden, die Facebook nutzen und 50 die Steemit nutzen. Beide Gruppen sollen zwischen 30 und 40 Jahre alt sein, dürfen nicht rauchen oder Alkoholiker sein, keine Drogen nehmen oder extremen Stress ausgesetzt sein. Mal ganz davon abgesehen, dass diese Einschränkungen noch viel zu wenig sind, denn zahlreiche weitere Faktoren wie Umgebung, Bildung, Essverhalten, familiärer Background, Altersverteilung (ich sag ja nur zwischen 30 und 40 Jahre alt), Beruf etc. lasse ich einfach außeracht [2].
Aber egal, ich schnappe mir jetzt die Probanden und zapfe denen Blut ab. Hier kommt schon das nächste Thema. Zapfe ich denen das gleichzeitig im Hochsommer ab oder nehme ich manchmal Blut im Winter, manchmal im Herbst oder Frühling ab? Je nach Jahreszeit schwankt die „Qualität“ der Lymphozyten natürlich auch [3]. Außerdem ist der Begriff Lymphozyt dehnbar, der eine hat vielleicht etwas mehr T-Zellen, die in bestimmter Art und Weise genau hier Telomerase-technisch sehr aktiv sind, der andere bringt ein paar träge B-Zellen zu viel mit.
Aber ok, das Blut wurde jetzt abgenommen und kommt ins Labor. Und hier geht’s gleich weiter: Macht der Laborangestellte seine Arbeit richtig oder schlampt er (oder sie natürlich auch). War bei einer Aufarbeitung der Puffer vielleicht etwas alt und beim nächsten Mal wurde frischer Puffer verwendet. Wie sieht es mit den technischen Schwankungen aus. Was für Geräte wurden verwendet? Wie groß ist der Fehler von denen? Alles also Störfaktoren, die eigentlich den entscheidenden Schritt der Datenerhebung schon stark verzerren können.
Egal, wir gehen davon aus, dass alles passt und jeder Datenpunkt 100% verlässlich ist (was übrigens niemals nie möglich sein kann!!!).
Aber juchhu juchhu, wir haben es geschafft, die Daten der Probanden sind im Kasten, wir beginnen also mit der Datenverarbeitung und verwenden, weil wir nix anderes kennen, unseren geliebten Students t-Test.
Nun muss man einfach erstmal schauen ob wir mit den Daten die Vorgaben eines t-Tests erfüllen können:
- Gepaart oder ungepaart? Natürlich ungepaart, weil zwischen den Probanden kein unmittelbarer Zusammenhang besteht.
- Wurden die Probanden zufällig ausgewählt? Na klar doch!
- Sind die Daten Normalverteilt? Ja!
- Stichprobenumfang vergleichbar? Na logo, Fifty:Fifty!
- Ist Stichprobenumfang ausreichend? Auf jeden!
- Einseitig oder zweiseitig? Obwohl ich als Steemian natürlich ganz genau weiß, dass wir längere Telomere haben, verwende ich trotzdem einen zweiseitigen Test. Man weiß ja nie.
- Und wo soll das Signifikanzniveau liegen? Natürlich bei unter 0.01!
Ok, dann schauen wir uns die Sache mal an:
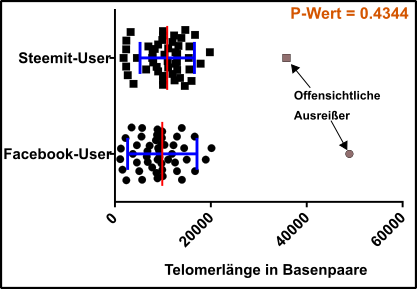
Abb.4 Alle Daten! Datenpunkte für Test = schwarze Vierecke und Kreise; Ausreißer = graue Vierecke und Kreise; Standardabweichung (blau) und Mittelwert (rot). Beachtet, dass man bei solchen Analysen immer der Standardfehler verwendet wird. Made by Chapper - unrestricted use allowed
Ah Panik! Was soll das denn? Was sind das für Daten? Und warum ist das nicht signifikant?
Ok, erstmal mit der Ruhe, da sind zum Beispiel zwei Datenpunkte (die grauen), die sind ja völlig bekloppt, das kann nicht sein, also weg mit denen.
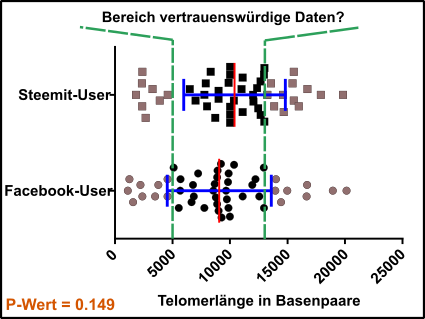
Abb.5 Ausreißer sind zwar weg, aber es sind immer noch Querschläger dabei! Datenpunkte für Test = schwarze Vierecke und Kreise; Ausreißer = graue Vierecke und Kreise; Standardabweichung (blau) und Mittelwert (rot). Beachtet, dass man bei solchen Analysen immer der Standardfehler verwendet. Made by Chapper - unrestricted use allowed
Ok, das sieht ja schonmal besser auf, aber ein P-Wert kleiner 0.01 ist weit und breit nicht in Sicht. Wie soll ich das denn meinem mysteriösen Auftraggeber von der Steemit Inc. (😉) klar machen und außerdem finde ich das auch voll doof, weil ich Steemit über alles liebe und Facebook voll doof finde. Ich will das die ganze Welt nur noch Steemit macht, das ist mein Ziel!
Nachdenken!!! Ah ich hab’s! Im Paper von Samassekou et al. 2010 stand doch drin, dass Telomere im Fötus so um die 13 kb lang sind und in Zellen, die schon richtig am Arsch sind so um die 6 kb. Naja, dann machen wir es doch ganz einfach: Ich schmeiße alle Daten raus, die sagen wir kleiner 5 kb (die können sich ja vermessen haben) oder größer 13 kb sind.
Na schauen wir mal.
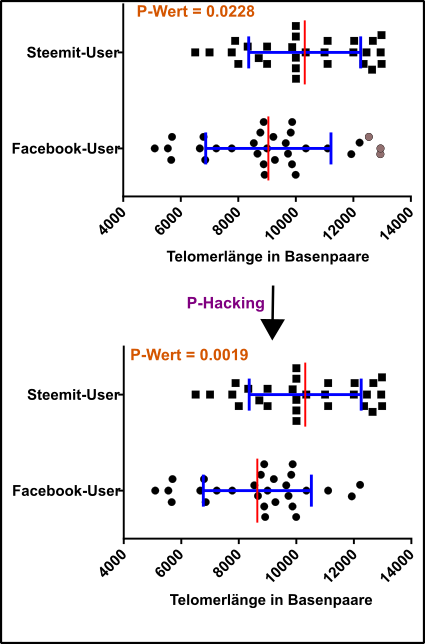
Abb. 6 P-Hacking erfolgreich! Datenpunkte für Test = schwarze Vierecke und Kreise; Ausreißer = graue Vierecke und Kreise; Standardabweichung (blau) und Mittelwert (rot). Beachtet, dass man bei solchen Analysen immer der Standardfehler verwendet. Made by Chapper - unrestricted use allowed
Nachdem ich den Bereich eingegrenzt habe, kam ich erstmals in den Bereich statistischer Signifikanz. D.h. einen P-Wert kleiner 0.05, ich wollte aber kleiner 0.01 haben, weshalb ich mal so clever war und einfach die obersten Werte meiner Facebook-Gruppe eliminiert habe. Das ist natürlich völlig legitim, weil nun habe ich die gleiche Anzahl in beiden Kohorten. Haha! Geschafft!!!
Das ist natürlich alles andere als legitim, das ist um ehrlich zu sein komplette Sch****!!!
Dieses Vorgehen erfüllt den Tatbestand des sogenannten P-Hackings in einer äußerst dramatischen Form. Man eliminiert einfach Punkte bis der P-Wert hinhaut. Aber auch schon die Schritte davor waren äußerst kritisch. Ok, die Entfernung der beiden extremen Ausreißer war vielleicht noch ok und auch bei der Einengung der Grenzen hätte man bis zu einem bestimmten Wert noch alle Hühneraugen zudrücken können. Wobei auch hier schon die Frage ist ob eine Studie, die man als Referenz nimmt (siehe dazu auch den Kommentar von @sco unter meinem letzten Telomerpost hier überhaupt ausreicht. Aber spätestens bei bewusster Entfernung von Datenpunkten ist endgültig Schluss. Zumal der P-Wert nur eine fiktive Grenze ist, die man irgendwie definiert. Dieser Wert ist lediglich eine Orientierung und kein absolutes Kriterium dafür, dass dies oder jenes wahr oder falsch ist. Wenn man sich die Daten oben einfach nur anschaut, wird man auch so schon feststellen, dass ein gewisser Unterschied vorhanden ist. Durch die einseitige Fixierung auf den P-Wert werden solche Sachen nicht nur nicht erkannt, es kommt auch dazu, dass sich sowohl die Urheber von Studien wie auch die Leser dieser nicht mehr ausreichend mit den eigentlichen Daten befassen. Dann heißt es nur: „P-Wert zu hoch, Studie fehlgeschlagen!“. Dies ist ein riesiges Problem, welches wohl kaum im Sinne von William Sealy Gosset war. Der womöglich einfach nur eine mathematische Grundlage zur Besseren Beurteilung von Stichproben schaffen wollte. In einer Veröffentlichung von Wasserstein und Lazar wird hart mit solchen Sachen ins Gericht gegangen, denn vor allem in Feldern wie der Psychologie ist dies ein Riesenproblem (in anderen Feldern natürlich auch).
Neben Fehlinterpretationen kommen außerdem noch wirtschaftliche Interessen hinzu. Natürlich wird eher gemauschelt, wenn ein mächtiger Geldgeber unbedingt ein tolles Ergebnis haben will. Es ist selbstverständlich klar, dass z.B. ein Hersteller von Vitaminpillen, welcher eine teure Studie in Auftrag gegeben hat, es nicht so einfach akzeptiert, wenn rauskommt, dass entweder nix passiert oder sogar nachteilige Effekte mit seinem Produkt verbunden sind. Zusätzlich müssen viele Forschungsinstitute und Gruppen auch schauen „wo sie bleiben“. Forschung ist aufwändig, kostet viel Zeit und Geld. Studien, die am Ende nix taugen liefern erstmal keinen Beitrag zur Reputation und Finanzierung. Getreu dem Motto Publish or Perish stehen viele Wissenschaftler heute mit dem Rücken zur Wand.
Die Lösung von allen solchen Dingen könnte (oder vielmehr wird) natürlich auch im Blockchainbereich liegen. Stellt euch vollkommen transparente Studien vor. Die gesamte Datenerhebung wird von der Blockchain getracked. Gleichzeitig sucht die Blockchain den besten Test, ermittelt die vertrauenswürdigsten Referenzen und würdigt den akribischsten Wissenschaftler, auch wenn der vielleicht nur alle 5 Jahre mal etwas veröffentlicht. Die Blockchain weiß aber, dass er einen sehr guten Job macht und alle können es sehen und vertrauen ihm. Keine Vetternwirtschaft, keine Korruption, keine Fehler 1. Art mehr! Freie Forschung 2.0 oder 4.0. Wie auch immer. Die Blockchain hat hier großes Potential meiner Meinung nach.
Gut, ich denke es ist erstmal klar geworden worauf ich hinauswollte. Für den nun wirklich letzten Artikel musste ich nämlich verschiedene Studien lesen und dabei war es erforderlich diese Finessen so halbwegs zu überblicken. Das war natürlich ordentlich Arbeit und so ganz fertig bin ich leider immer noch nicht.
Es sollte aber die nächsten Tage klappen, denke ich.
Bis dahin eine schöne Woche
Euer Chapper
Anmerkung
Ich habe die Hintergründe über die statistischen Testungen nach Besten Wissen und Gewissen recherchiert und dabei versucht alles Notwendige einzubringen, und unnötigen Ballast zu vermeiden. Bitte verzeiht mir, wenn ich hier und da vielleicht etwas nachlässig mit mathematischen Spitzfindigkeiten war. Mein Anliegen war es primär den Leuten, welche überhaupt keine Ahnung von sowas haben einen guten Einblick zu ermöglichen und den Leuten, die sich schon etwas besser auskennen Zusatzinfos zu geben. Falls ihr besondere Anmerkungen oder Korrekturvorschläge habt, dann postets in die Kommentare. Über eine lebhafte Diskussion freue ich mich sehr!
Beachtet bitte weiterhin, dass ich den amerikanischen Stil hier verwendet habe: Punkt (.) steht für Komma (,).
Quellen
Vieles dessen was im Artikel beschrieben wurde könnt ihr auch im Buch „Mathe für Biologen“ von Alan J. Cann nachlesen (Referenz siehe unten [4]). Meine Eltern haben mir es am Anfang meines Studiums mal geschenkt, ich habe es aber nie gelesen, weil unsere Matheprofs sagten es tauge nix. Ich habe es vor kurzem nochmal zur Hand genommen und muss sagen, dass es mir sehr gut gefällt. Falls ihr nicht die totalen Mathe-Heros seid, wird ich euch dieses Buch gewiss nicht schaden.
Außerdem sind einige Infos der Ausgabe “STATISTIK – Zahlenspiele mit Mehrwert” (Spektrum der Wissenschaft KOMPAKT 2.18) entnommen.
Weitere Infos findet ihr hier:
- Samassekou, O., et al., Sizing the ends: normal length of human telomeres. Ann Anat, 2010. 192(5): p. 284-91.
- Starkweather, A.R., et al., An integrative review of factors associated with telomere length and implications for biobehavioral research. Nurs Res, 2014. 63(1): p. 36-50.
- Naviaux, R.K., Metabolic features of the cell danger response. Mitochondrion, 2014. 16: p. 7-17.
- Cann, A.J., Mathe für Biologen. 2004: Wiley-VCH Verlag GmbH & Co. KGaA, Weinheim.

schön Wasserstein und Lazar hier zu sehen. Die meisten Publikationen basierend auf einem p-Wert sind falsch. Der bekannteste ist hier J. Ioannidis mit seinem 2005er Paper "Why Most Published Research Findings Are False"
viel verändert hat sich seit dem aber nicht. Es macht auch wenig Sinn mit Biologen und Medizinern hier zu diskutieren. Das Problem ist hier, dass sie anders als Trader, nicht von der Realität sondern von ihren Instituten bezahlt werden. Sie können falsch liegen, solange es dem Konsens entspricht und keine direkt zurückführbaren Schäden enstehen.
Nichts desto trotz bleibt Iantrogenität die häufigste Todesursache. Nicht etwa Krebs oder Krieg, sondern die Behandlung durch medizinisches Personal.
Und genau DAS ist zum kotzen in unserer Gesellschaft. Niemand muss für Falsches gerade stehen, solange Falsches als "wahr" deklariert wird.
Dabei verkraftet Wissenschaft es locker, dass das meiste falsch ist, es wäre sogar gut. Denn Wissenschaft basiert nicht auf Konsens (sollte nicht, die Menschen machen es aber so). Solange einer/eine eine Hypothese hat, die nicht falsifizierbar ist, ist doch alles wunderbar. Meta-Analyse und gut (was zum Glück oft noch so gemacht wird, oft aber leider auch nicht, da wird eine Meta-Analyse zur Synthese)
Oft kommt dann das Argument: "warum entwickelt sich die Menschheit dann immer weiter?, Fliegen bald auf den Mars? Wenn alles so kacke ist?!" :D Nichts was uns im Alltag umgibt, ist aus dem wissenschaftlichen Prozess entsprungen und erst recht nicht aus p-values. Würden Flugzeuge auf p-Values und einem 95% oder auch 99% Konfidenzintervall basieren, dann würde es keine mehr in den Lüften geben.
Es wird einfach Statistik gelehrt ohne Wahrscheinlichkeitstheorie. Das ist wie wenn sich jemand mit Autos bis ins Detail auskennt, sie aber nicht fahren kann.
Toll!
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @utopian-io and @curie.
If you appreciate the work we are doing then consider voting all three projects for witness by selecting stem.witness, utopian-io and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Congratulations @chappertron! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board of Honor
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @steemitboard: