Common Mistakes in Forecasting
So I have been reading some papers that came out recently, talking about forecasting markets and introducing new methodologies. I find huge mistakes that many novices and even professionals do in these models. Especially if you look on Youtube, there are plenty of amateurs there doing forecasting in spreadsheets or with R or other software, but they always make some kinds of mistakes that make their research completely bogus.
Yes, if you do only 1 mistake, then your entire model is rubbish. Historical data has to be handled carefully, because it's past data, so you have to simulate as if you were in the present, and the data next to it you know, but you have to pretend like you don't, since you are trying to simulate a model on something you don't know until the future comes. In a real-time model you don't know the future, so in the past model you should pretend that you don't know it either. So you can't leak into the future that is one mistake that many people do.
Don't Leak Into the Future
So on many Youtube videos they do things like, they calculate some statistic on the main data, like say the average price. And then they introduce weights according to that observation on a sample data, let me give you an example:
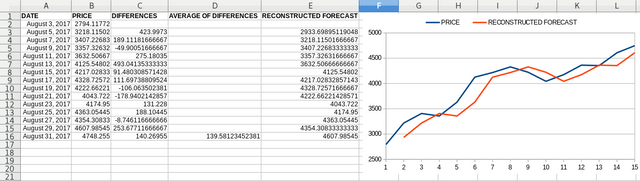
So in this example we have the BTC/USD price, we calculate the differences between the days, then we take the average of the differences, and then we add the average difference to each datapoint, to forecast the next datapoint from it.
Sounds easy right? Except that this forecast is bullshit. We have leaked into the future, by using the average of the differences. When we are at datapoint 1, we are not supposed to know anything about datapoint 2 and anything that comes in the future. Nothing!
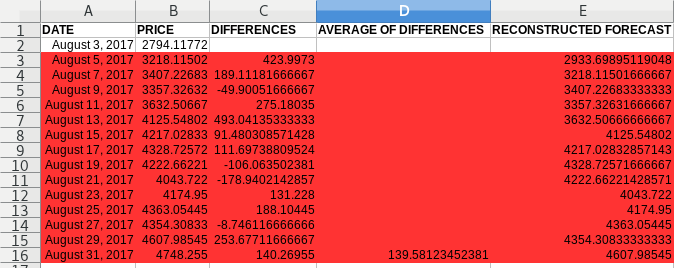
At datapoint Aug 3, we are not supposed to know anything about anything that comes after that, because if that had been the present, we would not know anything about Aug 4 either. So we have to work as if we don't know anything about the future. So any tool that we use, can only be used on the data leading up to that point, but it can't incorporate information we don't know at that point.
This also applies to regressors as well. Suppose you use the BTC/USD data with some trade volume regressor, and the main BTC/USD data is aligned to 00:00 UTC midnight, but the regressor is aligned to 00:10 UTC midnight (I have literally seen sliding time like this in data).
And then you apply the regressor with the price, not knowing that the regressor leaks in the future by 10 minutes, which you are not supposed to know at 00:00 UTC time.
So aligning the time is also very important, it's a pain in the ass most of the time, since most of the data is really aligned like that. Some data, are represented in their own timezone, not even UTC. Now that is a real pain in the ass to align time then, since even something like a leap year or leap hour can mess up our analysis.
So I can't take any data seriously which isn't in UTC midnight format, if it's daily data. If hourly then also it should be aligned to the hour at 0 minutes.
So it's very important to only use past datapoints in your model, and also have those datapoints aligned by date and time correctly. Plus some models leak into the future by default, like the HP filter, so you can't use those incorporated into the model. The parameters has to be based on past data only.
So you can't introduce future information of any kind in your past data, that you didn't know at that moment in time.
Injective Transformation
The other mistake people do is by using bogus transformation functions. You can do anything you want with your data, if you follow the previous rule. Anything except introducing new information.
So transforming the data is sometimes useful to remove noise, or big spikes that distort it but have no meaning.
However the transformation function must be injective, possibly bijective, but at least injective.
This is to avoid bogus values at reconstruction. A non-injective surjective function can have 2 original values for 1 transformed value:
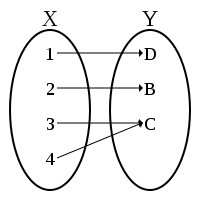
A good example of this is the Cosine function:
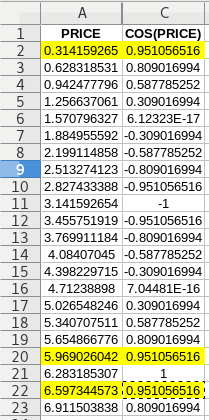
So you have the price in column A and you transform it through a cos(x) function in column C. You do your analysis on that. Now you want to transform it back to reconstruct the forecast, and you realize that C2,C20,C22 values can give different values. So which one is it? It can be any of them.
So this just introduces randomness in your model, which you don't want. So you can't use functions that are non-injective, probably all trigonometric functions are useless in forecasting. Not just that but any cyclical functions are probably useless too.
Good Benchmarking and Error Quantification
Another mistake is that people compare apples to oranges. So you have a model and you compare it's results to another model. I think that is wrong. Simply because different models use different lags or sizes of the data.
So I just introduced a new comcept, by comparing a model to it's random equivalent. The hypothesis is that the price is random, which is described by a white noise model ARIMA(0,0,0), basically taking the previous price as a forecast for the next price.
Then the error terms have to be un-biasedly described where I find RMS and things like that ridiculously biased, so I use LN ratio based errors.
Then just compare the LN Error of the model to the LN Error of it's "Random Walk" hypothesis. If the error is smaller then, the model is predictive, and gives us a positive edge. If it's equal then it has 0 edge. If bigger, then it's worse than randomness, a negative edge.
- https://steemit.com/trading/@profitgenerator/more-playing-with-btc-usd-data-quantitatively
- https://steemit.com/trading/@profitgenerator/the-real-structure-of-the-market
- https://steemit.com/mathematics/@profitgenerator/variability-in-a-heteroskedastic-market
So this is to avoid using things like Theil's U which is popular, but I think it's biased too.
"Technical Analysis"
So I have a distaste for TA, it's complete nonsense, mysticism based price analysis. Not science. But really apart from being non-factual and visual based, it can't be quantified, and the worst part is that TA analysts violate all these rules unconsciously.
For example the first rule is not just violated by visual TA analysts but also by science oriented quantitative analysts, but it's more hilarious seeing both people make those mistakes, it's more fun watching TA people drawing lines on the price showing some future price movement on the chart, that they have supposedly guessed, but they wouldn't have known about it if it wouldn’t have already happened.
They can draw nice lines on historical price, but they can’t predict shit about actual future data, and they always lose money in trading.
It’s interesting to see when brokers release their customer’s win/loss statistics, it shows that about 90% of traders consistently lose money, while only 10% of them make money and a few of them make really good money.
Almost like in a casino, except that a casino is provably negative expectancy, the house edge makes it probably negative.
A market is not negative expectancy, except for the tiny exchange fees like 0.1-0.2%, which normally should be negligible. But it’s mostly because these people don’t know how to forecast the market.
Prices can be forecasted, maybe even profitably, it’s just that they don’t know how, and they commit these mistakes. So trading is not necessarily gambling, only if they don’t know what they are doing.
Sources:
https://pixabay.com

In others words, will I make position opposite to technical analysis a smart choice? As they are major losers.
No, that is nonsense, the TA is no better than randomness, it might be worse.
In the sense that in roulette if you place your bet on the red chip, if you lose that doesn't mean that placing it on the black one would result in win.
It's random, and randomness goes both ways. Taking trades opposite to TA is exactly like taking bets opposite to "gambling strategies".
They are both useless, and no better than the random walk output.
For your strategy to be profitable, it must have smaller errors than the random walk output (the previous value as the forecast for the next one).
That still not guarantees profitability, but if it's higher than that, then it's certainly not profitable.
Interesting post.
The share / stock market is full of analysis tools that can basically "crystal ball" the future.
The big question I have is "do these tools apply to crypto markets"
I suspect the crypto marks is different, in nature and performance as well as volatility.
Time will tell
Stock market is certainly easier to predict since it's usually trending up (due to stupid monetary policies, leverage, QE, you name it).
Crypto markets have a trend for now, but its only 7 years old, so I's certainly not a robust model.
I agree crypto is new & volatile, & that makes it great for day traders perhaps.
The stock market on the other hand is over inflated in every direction IMHO
Trump keeps going wow wow wow, I keep saying ow ow ow :-)
The P/E and all the fundamentals I have ever learned / studied point to a bigger than '29 and then add in the speed of computers compared to '29 or even '08, it is going to be huge.
I don't know when, but it will be soon. IMHO
maybe crypto petro or maybe iran-russia oil maybe some other trigger, but soon.....
so relatively, crypto is 'safe' juts hodl is enough IMHO
But I'm just an old fart, been there done that around the block a few times but what do I know.? But I do sense a certain amount of 'controlled' media that has been going on :-)
Time will tell.
Yes, volatility is usually associated with predictability, a static sideways market is more likely to be just random noise than a swinging market, so that should be easier to predict.
As for the stock market, it's economically inevitable for it to crash, but I don't think it's politically viable, so they will just keep pumping it up, so I think the endgame will be hyperinflation of the USD, perhaps hyperinflation of all fiat currencies at the same time since the ECB and other major central banks have huge exposure to the dollar as well, if it goes south, all of them go south.
I agree, one down all down!
I also think sooner than later.
Time will tell.
No, in the case of a hyperinflation the stock market would skyrocket, but that would be just an illusion of wealth since the currency would fall quicker than the stock market rising. Thus your true pruchasing would would go down no matter what you would do (except if you'd find a market that would go up quicker than the fiat would fall, perhaps cryptos).
It would be an illusion of wealth. In fact right now, most of the stock market growth is inflation, the net growth may be negative.
It's not in the USA since the USD is a global reserve currency, but in other countries the stock market growth is effectively smaller than the true inflation rate. So most people are losing money day in day out.
I am talking about BUY & HOLD strategies. Like buying an index.
Of course that is the basic expectanc of the stock market, but with some careful analysis it might be possible to outperform that with either good stock picks or higher frequency trading of the index with leverage.
Interesting thoughts. Thank you.