Improving Steem’s rankings to cater to diverse content preferences
Improving Steem’s rankings to cater to diverse content preferences
Would Steem fail if every blog post of a lady putting on her makeup is rewarded $26,000?

This non-meritorious aberration is because Steem’s incentive system maximally rewards those who vote in a groupthink. This is becoming a significant concern that threatens to destroy Steem’s utility and value as evident by the parodies and rants against ‘circlejerks’.
The One-Size-Fits-All Problem

I explained in a comment that the fundamental technical flaw appears to be that Steem’s ranking model computes a one-size-fits-all ranking for all users.
It's getting harder and harder to find all the hidden gems on Steemit these days.
That is unavoidable in the current system design, due to the one-size-fits-all reputation system, i.e. each user will have different priorities but the design of the system doesn't accommodate such degrees-of-freedom.
If some of the voting power shares your preferences, that content will rank higher than content that interests none of the voting power, but assuming that interests are reasonably diverse then ranking will be more or less uniform and uncorrelated to individual preferences. So thus more or less in order for any content to rise up, it must be a groupthink effect.
To maximize each voter’s reward, the optimum mathematical strategy is for all voters to vote on the same blog post, because currently Steem only computes a one-size-fits-all global ranking metric. I explained in another comment that invested whales who were expected by Steem’s whitepaper to vote to curate and protect the long-term value of Steem ecosystem, are mathematically incapable of fulfilling that expectation, because they are tied in a knot of a one-size-fits-all global ranking metric.
I suppose that one possible response is that whales have an incentive to preserve the value of their investments, and the best way to do that is to promote a system of fair voting and promote the integrity of the system
The one-size-fits-all ranking system (c.f. my other reply to @smooth below) makes it impossible for whales to act rationally, because they can't compute a set of votes which would reflect their individual preferences for quality which might be shared with other like-minded users.
Thus as far as I can see, the system disincentivizes the whales from participating in voting, for they will come to see that either they become one dysfunctional groupthink monolith or they more or less effectively nullify each others votes in terms of anything other than a uniform ranking which is functionally equivalent to no ranking.
Proposed Solution of Clustering Multiple Rankings
In my prior comment I had alluded to a possible improvement and solution to the dilemma:
An improvement would be some algorithm which allows each grouping of like-minded interests to have their own separate ranking computation. The monetary reward algorithm would also need to change, so as to reward content that ranks highly in any grouping.
The inspiration is that votes should be automatically clustered (grouped) into coteries by an algorithm which can automagically detect the users’ shared preferences, so that a plurality of rankings are allowed: one for each coterie cluster detected. Each user will then see rankings customized to that user’s content preferences.
Benefits
Hypothetically, not only would this eliminate the mindless strategy of voting only for the most globally popular posts, thus reducing rewards for blogging to the meritorious content quality perceived by the voters, it would also stop spamming users with content they aren’t interested to see first. Each user would only see highest ranked the content that they prefer and the content rankings would vary for each user given each user’s individual content preferences. This should reduce animosity between people who have different content preferences and are in the current system competing against each other to spam each other.

And all of this would happen automatically, with no changes to the user interface. Users would continue voting, and only their optimum voting strategy would change. Users browsing blogs would continue to do so with the only change being they would see content highest ranked relevant to their preferences.
This would be in theory be a major innovation as compared to Reddit's global one-size-fits-all ranking algorithm.
Technical Description
The technical description of the algorithm I propose may be a bit difficult for some readers to grasp, but I’ll try to not use more technobabble words than absolutely necessary. Notice above I used ‘voting strategy’ instead of ‘game theory’, and I avoided mentioning ‘Nash equilibrium’.
I propose we compute the like-minded distance Dₛₜ between each pair of voters s and t by finding the mean of the following value (Dₛₜ)ⱼ for each pair of votes sⱼ and tⱼ for instance j of content on which either (or both) of these paired users voted.
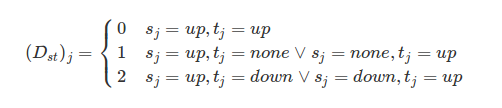
Alternatively we may wish to underweight in the computation of the mean, the cases where the value is 1, given these add less information because one of the paired voters has not voted on the instance of the content. The term ‘content’ means for example a blog post.
The distances Dₛₜ are grouped into k clusters with the Jenks natural breaks optimization, a.k.a. one dimensional (univariate) k-means clustering.
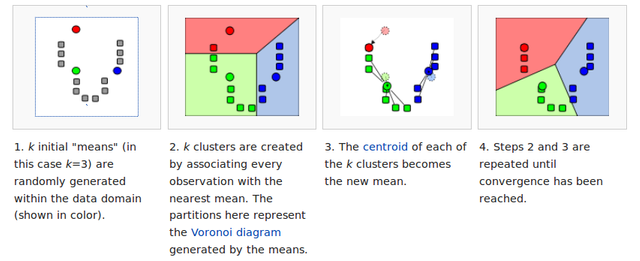
This clustering algorithm groups the distances Dₛₜ into the k clusters which minimize the sum-of-the-squares of the deviations of each member distance Dₛₜ of the cluster from the mean of the cluster. As depicted in the image above, this maximizes the separation between clusters by maximizing the sum-of-the-squares of the deviations of the cluster means from the mean of all the distances Dₛₜ.
We can either choose a value k; or find the value of k which provides the a minimum value for GVF (goodness of variance fit) we’ve chosen.
This algorithm has then grouped the voters into k clusters which maximize the like-mindedness of content preferences for the members of each cluster.
An extra restriction is required on the algorithm, in that for every instance of voter (for s or t) that is a member of a cluster then all instances of that voter (for s or t) must be grouped in the same cluster.
Application
The ranking within each cluster can be computed weighted by Steem Power (SP) according the current computation in the Steem white paper. These totals from the clusters are fed into the algorithm from the white paper to determine the relative rewards for each instance of the content.
Each voter will see the rankings for the cluster which he/she is automagically a member of.
Also the like-minded distances and clustering algorithm could be applied orthogonally to each hashtag (a.k.a. Tag or category), so that voters can be clustered differently for different hashtags. Individuals may have different automatically computed groupings depending on which genre of content they are voting on.
I don't know that it would (FWIW, I do not believe that every such post would be so rewarded, only the first that emerged as a hit or others that offered something new). Look around you. The most commercially successful music is cookie cutter. The most successful TV shows are dumb. Nobody even buys books any more at all (other than maybe romance novels?). One of the top posts at reddit right now (5000 votes) is: "Excluding my mom, what's the worst sex you've ever had?"
What is successful is what addresses the market as it exists, and that includes a great deal of demand for shallow content and being popular for being popular.
Also, implemention factors are very important. Voting is processed by the consensus code which needs to not only be kept relatively simple but also very high performance. This doesn't mean that your ideas can't work but to be a credible proposal you need to completely specify how and when the various processing steps occur. Of course that can be the subject of later posts.
I realize that opening statement could be interpreted the way you did. Rather I intended it in the context of the article, meaning that given the current optimum voting strategy of each voter maximizing his/her reward by choosing to vote on the posts with the highest $rewards, then there will always be some post that is awarded far too much while so many others are rewarded far too little. Btw, my proposal isn't intended to entirely interfere with the intended psychology effect of quadratic weighting of voting power which the white paper says is intended to motivate blog posters by causing them to incorrectly assess the odds of their likely average reward. Rather my proposal is merely so that the voting power isn’t incorrectly incentivized to vote as a groupthink monolith. I realize some people may be voting their conscience in spite of it not maximizing their curation rewards, but still my proposal benefits them because their conscience will then actually be more highly reflected in the ranking for the cluster that shares the same like-mindedness.
My rebuttal to the claim that one-size-fits-all content is what the masses want, is to observe the decline in viewership of non-interactive media (e.g. newspapers and TV) since the Internet. Apparently the masses want to customize their experience with media, while sharing that experience/content with like-minded community (and 5000 people in a like-minded cluster is sufficient socializing and good feeling being a member of a group that shares interests). Meaning I agree and disagree with you, in that yes masses want to share things that many others also like, but they want to prioritize their sharing around their mutual likes, not everything under the sun. And they probably do also want to venture outside their priority interests sometimes to see what is going on outside. Even my 26 year old filipina gf tells me she doesn't like seeing violent sharings on her Facebook timeline. She wants cutesy and humorous content, e.g. dogs dancing, etc.. She would have absolutely no interest in reading this proposal. But she will partake of an occasional guy who got crushed under a bus (or apparently a pornographic scandal she did not tell me about lol).
Given the millions of users who visit Reddit every day, 5000 up votes seems quite low. This seems to confirm that millions of viewers are being spammed with content they probably aren’t interested in. We might have an opportunity to improve upon Reddit’s ranking algorithm.
A “Trending for Others” ranking choice could still provide the original unclustered rankings when users want to venture outside their voting preferences. These could even be sparsely interleaved by the UI in the clustered rankings to provide some statistical opportunities for users to morph their voting preferences and not get stuck in a localized groupthink. Yeah we probably need both! Good point.
Note none of the reduces the other main benefit of my proposal which is that curator rewards would be confined to clusters, to remove the incentive for voting in one global groupthink.
The voting is recorded on the blockchain in I presume real-time, but the rewards are only recorded periodically. Note the rankings and rewards can be computed in real-time for the UI independently of the consensus validators. Thus afaics, it is only when the rewards need to be periodically recorded that those computations need to be performed by the consensus validators. Thus it appears the cost can perhaps be amortized over significant periods.
Agree overall on most most points. Re. implementation, payouts are transactions too. Currently those perform a relatively simple calculations based on shares, and those transactions would need to remain limited in computational cost. I don't think this proposal changes that much though, it just has more complicated (but still computationally simple) accounting of shares by clutser. My concern is primarily the k-means clustering; Incremental k-means variants exist, so it is probably solvable.
Also, dividing users into clusters requires a minimum number of users in each cluster, thus a minimum number of users on the site as a while. At present I doubt that is feasible as the number of users on the site is just barely reaching the point where it works at all. Ideally of course the number of users will be much larger in the future, so something like this could be phased in.
Pleas check out this post I made about a steemit Bug the dev's should see this post so they can fix it. https://steemit.com/bug/@stijn/steemit-bug-needs-to-be-fixed
You are right about that but I think if the interface had clearly defined groups like Reddit, which were moderated like Reddit or Facebook, where only people in that group selected as moderators can determine for example to allow a post into that topic, then maybe you can focus the curation per topic.
Right now if I check the basic income topic I can't find anything related to basic income without digging through all sorts of noise.
It would help but not resolve the main issue. Currently users are rewarded more to rewarding content creators with the highest rewards rather than best content.
The best content is subjective. The only way to determine best is to go by rank and the only rank we have is votes. So the most votes is considered the best by the community. No different from Reddit or Slashdot or any other collaborative filtering.
Afaics, my proposal when orthogonally clustered per topic (aka tag or hashtag) would automatically (i.e. algorithmically) accomplish the same by ranking the irrelevant posts at the bottom of the list of posts for the topic, without needing to manually pick and trust moderators.
True, but hypothetically my clustering proposal should offer the advantage that rankings are customized for each cluster, i.e. for each group of people who tend to vote with the same preferences, thus automatically customizing rankings to different people’s likes (up votes) and dislikes (down votes).
Not all votes are equal. Rich/Powerful voters have more important vites.
I would not even try to map the data to the Grassmannian and use the naturally defined metric to determine clustering of the data on various manifolds.
Bad ideas don't work in practice.
Seriously. Avoid this notion at all costs. Grassmannians are tricky beasts.
Is it the intermediate mean for Dₛₜ? You think I should cluster directly on the votes? That worry crossed my mind but I hadn't yet had time to delve into the ramifications. I am not familiar with why they are tricky.
I dunno man. Anytime I start thinking about the space of k-dimensional linear subspaces on an n-dimensional space (i.e. Gr(n,k)), and about points on that space, my mind begins to get warped.
The big question is how can other metrics be used as a way of identifying clustered points on a manifold.
I think we'll see how persistent homology will be coming into play.
I think the only thing Steemit needs to do is improve the user interface so we can find posts on topics we look for. Now it's hard to do because the interface doesn't make it simple.
In Reddit you can subscribe to groups. Groups have moderators. You can expect to see only posts of a certain topic within certain groups. Same with Facebook.
Steemit doesn't yet have clear groups. This is why it's hard to find the topics which we look for. I don't think the math or technical aspects need to change but I do think the interface needs to be at least Reddit level.
Afaics, the problem can not be solved only with filtering the display by tag or grouping without changing the underlying computation of the rewards. Without my proposal, the voters have a mathematical incentive to vote on only the highest payout posts, in order to maximize their own curator rewards. Maybe it is not clear to everyone why I think that is the case. The reason is because I presume the voter has no way to predict which voters will vote on each blog post and thus which blog posts which be optimum for them to vote on to maximize their curator rewards constrained to their cluster. So I presume absent an a priori strategy to maximize their curator rewards, they will choose to vote honestly according their content quality preferences. Note this aspect of the game theory needs to be pondered carefully.
Additionally, I quote what I wrote in reply to @smooth:
As the system is right now, perhaps he doesn't even need to "predict". He can vote, see whether others voted, and then if they did vote and raised money preserve the vote. If they didn't raise money, he can proceed to unvote and vote something else: https://steemit.com/steemit/@alexgr/curation-gamed-through-unvoting
This doesn't work. I'll explain why in a response to your post.
I am not concerned about the rewards. I think the rewards are working great. Popular content is getting the most money. Sure you can have content which gets a lot of votes but which doesn't get much money because not a lot of voting weigh is behind it but that will change over time as more people have Steem Power.
I don’t understand why you are not concerned that people are apparently not always voting for the content which they like the best, but instead for the content they think can give them the highest curator rewards? I am doubting that you have understood deeply enough the various concepts and impacts of this proposal.
The point is voters are being incentivized by the curator rewards to not vote on the most relevant content, but rather on the content that other whales have voted on. This apparently causes a swarm vortex effect where all the votes get sucked towards what ever got the early momentum, regardless if that blog post was not so much better in quality than all the others.
Granted I am not sure that everyone is voting to maximize their curator rewards. But if say two whales who have 3 million Steem Power voted for a blog post, then many others will vote for it, because not only their curator rewards will be higher for doing so than wasting their vote on another blog post, but also because that blog post being at the top of the listing will also cause it to be seen by EVERYBODY more often.
Hypothetically my proposal not only divvies up the curator rewards by like-mindedness, it also divvies up what people see at the top of the listings so not everybody sees the same top ranked blog posts.
In the abstract, my proposal is about adding more degrees-of-freedom to the ranking system in all aspects of it.
I posted my proposal to solve this issue the other day which actually fits in with your algo as well.
https://steemit.com/steemit/@jacobt/the-circlejerk-needs-to-end-now
This need to be on first page. Upvoted.
EVERYONE UPVOTE THIS MAN!! We need him to have a vested interest in the platform so he'll keep on contributing his brilliance to the community!
This was long due! As a non-coder I can really hope that some of what you've suggested gets implemented. This is a great proposal and I hope it will bring many positive changes to this platform. I hope it makes it to the front page and stays there for a while! :)
This is what will make this platform great. People from all walks of life putting their efforts in. Great post!
I agree about the imperfections of the issues with the ranking and reward systems. However, I do not see the solution as fully considered in its present state.
Primarily, what are the implications for the allocation of rewards across tags? How much should #steemit get versus #beauty?
Might multiple cluster membership or topic modeling be a better fit?
And by automagically, I assume machine learning of some variety?
Multiple cluster membership is what I alluded to in the last paragraph of the last section:
You are correct to point out I was vague in the last section, but afaics the rewards should still be according to voting power; thus the relative allocation between clusters and hashtags could remain an orthogonal attribute of the voting power. In other words, the total reward for the blog post’s author would still be based on the sum of the voting power for it, but the rankings would be clustered. However, the voter’s reward should be constrained to the voting power of the clusters he/she is a member of, so that the Nash equilibrium of voting for the posts with the highest rewards is I think removed. The proposed algorithm incentivizes the voting power to divvied up more granularly by providing orthogonal rankings for like-minded clusters of voters and this could be computed orthogonally for each hashtag. I will be pondering more the game theory ramifications of this proposal.
I did actually think of this issue, but I just forgot to write it into the last section. My energy level and focus was tailing off apparently as I composed the end of the document. There were many details I thought of and I may not have written them all down yet. I will as I remember.
The automagic is the algorithm as described.