阿里云新一代视觉语言模型超越Openai-4o?

阿里云近日重磅发布了新一代视觉语言模型Qwen2-VL,其在图像、视频理解和交互等方面展现出卓越能力,并在多个基准测试中取得全球领先成绩。Qwen2-VL不仅支持多种语言和不同分辨率的图片处理,还能理解长视频内容,甚至具备操作手机和机器人的视觉智能体能力。此次开源Qwen2-VL-2B和Qwen2-VL-7B,并发布Qwen2-VL-72B的API,将进一步推动多模态AI技术的发展和应用。
新功能速览:
Qwen2-VL在Qwen-VL的基础上进行了全面升级,主要特点包括:
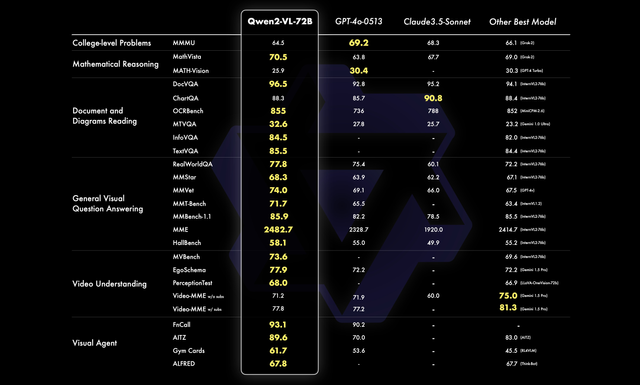
更强的视觉理解能力: 在图像理解基准测试中表现优异,例如MathVista、DocVQA、RealWorldQA和MTVQA等。
长视频理解: 可以理解长达20分钟以上的视频,并应用于问答、对话和内容创作等场景。
视觉智能体: 能够集成到手机、机器人等设备,根据视觉环境和指令自动操作。
多语言支持: 除了英语和中文,还支持多种欧洲语言、日语、韩语、阿拉伯语等。
功能解读:
Qwen2-VL的核心是将视觉Transformer(ViT)与Qwen2语言模型结合,并通过一系列创新技术实现了强大的多模态处理能力。
- 动态分辨率支持: Qwen2-VL能够处理任意分辨率的图像输入,并将其转换为动态数量的tokens,有效确保了模型输入与图像原始信息的一致性。
- 多模态旋转位置嵌入(M-ROPE): 通过将旋转位置嵌入分解为代表时间、高度和宽度的三个部分,实现了语言模型对文本、图像和视频位置信息的综合理解和建模。
重要性:
Qwen2-VL的发布具有重要的意义:
推动多模态AI技术发展: Qwen2-VL在视觉理解、视频理解和视觉智能体等方面取得的突破,标志着多模态AI技术迈入新的阶段。
拓展AI应用场景: Qwen2-VL强大的能力使其能够应用于更广泛的领域,例如智能客服、教育、医疗、机器人等。
促进开源生态繁荣: 阿里云开源Qwen2-VL-2B和Qwen2-VL-7B,并发布API,将进一步促进多模态AI技术的开源生态发展。
我们在想:
Qwen2-VL的发布,预示着多模态AI技术将加速融入我们的生活。未来,我们可以期待:
更智能化的智能助手: Qwen2-VL可以帮助我们更好地理解和使用各种视觉信息,例如识别图片内容、理解视频信息、操作智能设备等。
更便捷的跨语言交流: 多语言支持能力将打破语言障碍,促进全球范围内的沟通和协作。
更强大的机器人应用: 视觉智能体能力将赋予机器人更强的感知和行动能力,推动机器人应用的普及。
然而...
Qwen2-VL在某些方面仍存在局限性,例如无法从视频中提取音频、知识更新截至2023年6月、在复杂指令和场景下不能保证完全正确等。因此,在使用Qwen2-VL时,需要结合其特点和局限性,合理应用。
总结:
Qwen2-VL是阿里云在多模态AI领域取得的重要成果,其强大的能力和开源策略将有力推动多模态AI技术的应用和发展。未来,随着Qwen2-VL的不断完善和应用,我们将会看到更多令人惊喜的AI应用,进一步改变我们的生活和工作方式。
Upvoted! Thank you for supporting witness @jswit.