Research into the next killer app for the blockchain
How to make information absorption and engagement better and easier?
Statistics
Languages
The number of people who speak English as a 2nd language is greater than the number who speak it as a 1st language
China is, or will soon be, the largest English-speaking population.
Percent of YouTube visitors that come from outside the U.S. was 70 % in 2016
Number of countries with localized versions of YouTube was 42, total number of languages Youtube is broadcast in was 54
Video
YouTube has 258 million users, 50% visit weekly or more; more than100 million YouTube videos a day are being watched (July 2007)
6 out of 10 people prefer online video platforms to live TV
In 2015, 18-49 year-olds spent 4% less time watching TV while time on YouTube went up 74%
You can navigate YouTube in a total of 76 different languages (covering 95% of the Internet population)
- Over 30 billion videos were watched in Feb 2010, but in 2016 there were 3.25 billion hours of video watched each month
In 2009, video accounted for almost one third of the total internet datatraffic; by 2013 it is projected to be over 60% of all internet traffic
by 2019, online video will be responsible for four-fifths of global Internet traffic. The stats for the U.S. are even more impressive, coming in at 85%
Globally, IP video traffic will be 82 percent of all consumer Internet traffic by 2021, up from 73 percent in 2016
Content Delivery Network (CDN) traffic will carry 71 percent of all Internet traffic by 2021
Traffic from wireless and mobile devices will rise to 66% in 2019.
Learning
One week of today's NY Times contains more information that a typical person would encounter in their entire lifetime in the 18th century
that is increasingly rich multimedia to an audience that is increasingly remote;
in new formats that are penetrating new audiences increasingly quickly;
that is consumed by an audience that must absorb and comprehend information at an unprecedented rate;
to audiences that are increasingly global and diverse in abilities;
to audiences that are increasingly likely to be non-native Englishspeakers;
that may use English terms that are not familiar even to native speakers
Second language learners can more quickly assimilate material in written form than oral form.
Comprehension (and grade point average) increases when students view content with captions.
Captions help students recognize and research unfamiliar terms.
Captions help people access material in environments that are unfriendly to audio.
Caption allow viewers to more quickly locate material of interest in video.
Solutions
The ideal would look and function like this:
(thanks to @AlexPMorris)
How do we make people more aware of their personal data?
and
Animated text spoken out load with presentation slides in-bewteen
or going even further
Cutting out what is not needed or confusing
Take look at the audiowaveform below and imagine a lot of redundant words and pauses.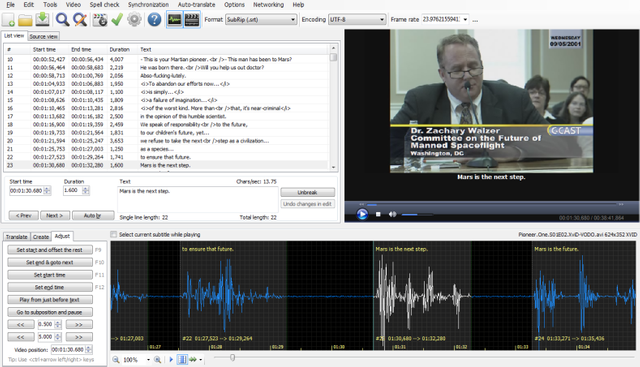
With any dialog misunderstandings can happen. Especially when you see or don't know who is speaking on the other side in a telephone converstation or on Mumble like we do in the #BeyondBitcoin #Whaletank
To make the information denser we'd need word-level granularity for subtitles, in order to trim the audio with a package like Videogrep: Automatic Supercuts with Python
Which you can see here in action:
Subtitles are always time-stamped for a few words but to get a timestamp for each word i.e. word level accuracy you'd need an aligner like this one:
execute_taskwill align 107 fragments, at word-level granularity. A Practical Introduction To The aeneas Package
Who is saying what?

With identifying speakers I think Google is making the most progress:
Through Deep Learning Google home can differentiate up to 6 speakers in your home. And instead of 8 microphones it needed just 2, using deep learning again called neural beamforming which is all software. Google I/O Keynote 2017
But YouTube does not support any speaker differentiation. It is just one big word salad with no sentence structure like punctuation or capitalization. So we use a punctuator to get a sentence structure and
restore punctuation in unsegmented English text.
Chapters and markers
With YouTube having a billion hours of views each day you might also consider that most is a waste of time, especially when you are looking for speficic information which makes you a knowledable person, and maybe even high payed thus your time is precious.

Eventhough you can have chapters below the video it would be surpisingly effective to have them displayed on the timeline. With an indication of chapters or other markers such as comments! Similarly what SoundCloud does with audio.
Highlighting videos

You could even stitch multiple videos together automatically by looking for words in comments alongside the timeline or by searching and selecting relevant text from their subtitles. Thus remixing videos, making your own story or documentary.
Maybe the day you shot your action was not as nice than those from others and you could show those videos to make the best sports action movie, documentary or any mash-up.
Feedback, comments and curation
Steem incentivizes users to curate quality content. It takes a brief look at comments on YouTube for example to quickly see the atrocities a semi-anonymous centralized commenting system does to people wanting to genuinely engage.
This is another big plus for social media blockchains like Steem.
Links to research:
- an extensive list of current Speech-to-Text and captions technlogies
- Comparing Transcriptions
- Needs for a Captioning Tool
- Prosodylab-Aligner
- aeneas aligner YouTube
- A Practical Introduction To The aeneas Package
- Google opens access to its speech recognition API (techcrunch.com) and HackerNews comments
Culture
One could argue that remix culture has been around as long as the idea of “culture” itself. techcrunch 2015
Wayne enterprises video remix:
Other notable mentions:
Target audience
- Help decentralized autonomous companies (DAC's) present their white papers
- Let decentralized news agencies fact check and easily remix video
- Help grow (truth) documentaries
- Schools, Universities, Home schooling
a Better product for a whole new social media blockchain?
That's what matters in the end, is the end result better or achieved faster and with less friction?
Many steps vs a few
This is simply the right direction. You gave the necessary changes to make in order to get the best. Well done
just to clarify how the latest srt2vtt works, it creates a batch file that uses ffmpeg to cut and/or splice the various segments of the video/audio track, as designated using SubTitle Edit:
If you right-click over the timeline, you get another menu that easily lets you split, add text, etc. SubTitle Edit even tries to determine where best to "split" the caption. And to add a new caption, just left-click and hold between two points, and then right-click "Add text here".
srt2vtt will also readjust all the timestamps to account for the cuts and splits as well.
I wonder how it does that ;) Might have explained my questions sooner.
So it uses an alligner which means it will check if a word corresponds with the audio. Much easier to do than having a machine learning algorithm like a neural network which tries to guess what's being said by having billions of training examples.
This way YouTube can allign transcripts to audio and figure out time codes. The probability of the next uttering being the word you are looking for is much higher than not knowing what's being said at all. Kuddo's to Google's neural networks!
Wooow nice sir.............. Special respect......👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍