You are viewing a single comment's thread from:
RE: Research into the next killer app for the blockchain
just to clarify how the latest srt2vtt works, it creates a batch file that uses ffmpeg to cut and/or splice the various segments of the video/audio track, as designated using SubTitle Edit:
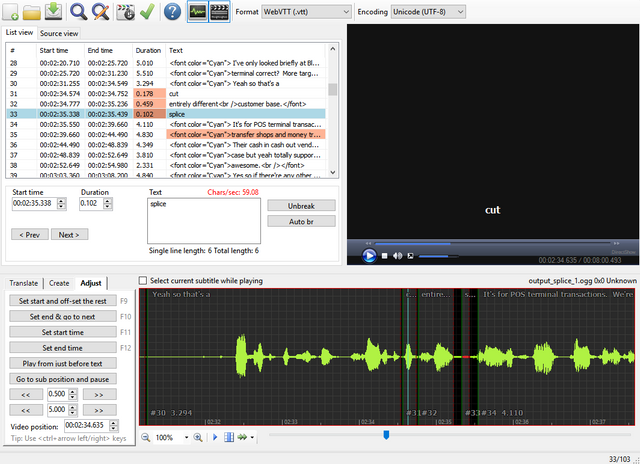
If you right-click over the timeline, you get another menu that easily lets you split, add text, etc. SubTitle Edit even tries to determine where best to "split" the caption. And to add a new caption, just left-click and hold between two points, and then right-click "Add text here".
srt2vtt will also readjust all the timestamps to account for the cuts and splits as well.
I wonder how it does that ;) Might have explained my questions sooner.
So it uses an alligner which means it will check if a word corresponds with the audio. Much easier to do than having a machine learning algorithm like a neural network which tries to guess what's being said by having billions of training examples.
This way YouTube can allign transcripts to audio and figure out time codes. The probability of the next uttering being the word you are looking for is much higher than not knowing what's being said at all. Kuddo's to Google's neural networks!