Semantic Web - Do We Need To Rewrite The Whole Web?
Image Credit: Flickr, CC BY 2.0
I am back with Semantic Web this time. One of my previous posts was about Natural Language Processing, in which I mentioned Semantic Web. NLP basically just assists a bit to get started with Semantic Web. You may want to read my NLP post and mainly its introduction and the Web 1.0, 2.0, 3.0 part.
Introduction
To explain what it is, I will start with Web 2.0. The kind of web, we use today i.e. HTML pages are constructed and all are linked through hyperlinks. Users enter keywords to search these pages. The system/machine doesn’t have a clue about the nature of data, it just delivers “what” is asked, not what the user “wants”. In short, the web works on keyword based searching.
What is Web 3.0 or Semantic Web? The kind of web in which all the data is structured which is not only human readable (HTML pages) but it is machine readable. So that the web can do a little thinking for us.
That's the simplest possible way to explain it.
Do you know how data is stored on Internet?
Database, of course! In web 2.0, all information is stored in a database which is relational or hierarchical. Some nodes have more precedence over others. Like there are parent nodes, child nodes, root nodes etc. Whereas in Web 3.0, data is stored in the form of Data Graph. The main difference is that all nodes have same precedence over each other and are also inter-related or linked.
Let's get things straight with examples of each.
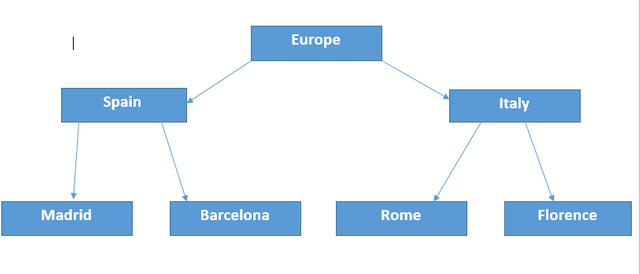
Example of Hierarchical Database
Each node is linked to another node that is either its parent or child. Below is an example of such database.
This image is my work( You are free to use it anyway).
You can see Europe is the parent class here. It has two extended nodes Spain and Italy which are its countries but in hierarchical terminology, these are child nodes of Europe.
Next each country has two more child nodes or cities. You can see the pattern. These are all implicitly linked.
Example of Relational Database
It’s not like Hierarchical Database in which nodes are implicitly linked. Relational Database joins table. And each table is linked to another explicitly. For such purposes there are primary and foreign keys. Below is an example.
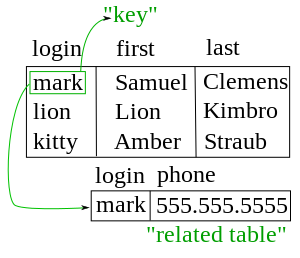
Image Credit: Wikimedia Commons, CC SA 3.0
{kind=link}
You can see two tables here. The primary key in first table is login. As you can see it makes a relation with another table. Primary key is unique. It can't be repeated like the login names here.
Example of Graph Database
All data is linked without any precedence over each other. Below example will explain everything:
Graphical Database:
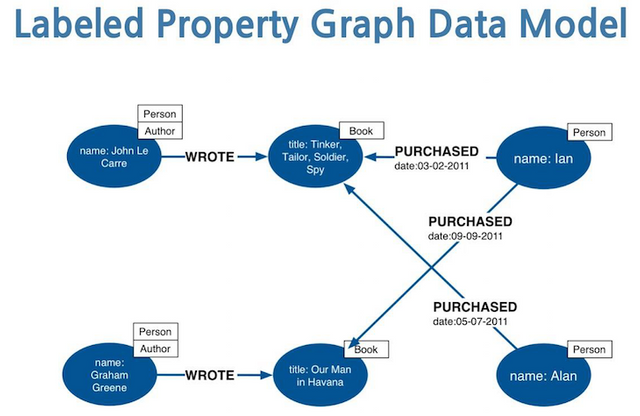
Image Credit: Wikimedia Commons, CC SA 4.0
{kind=link}
In this example we can see the relation between entities is shown. There is no hierarchy, instead any entity could be linked to other. You can see the relations forming in this diagram like Wrote, Purchase.
Triple Generator
Basically the first step towards Semantic based Web is to determine three things i.e. Subject, Object and Predicate. Here comes NLP into action.
From the above examples: Bob is a friend of Alice. Bob's dob is 31-07-1992.
Bob is Subject.
Friend and DOB are Predicates.
Alice is Object.
You can see the relationship forming. Now taking along this information further to RDF.
Resource Description Framework RDF
Now the information (Subject, Object, Predicate) gathered through Triple Generator is used in creating RDF documents which are in machine-readable form. See the below snippet for a glimpse of how RDF looks like.
<rdf:RDF>
xmlns:rdf = "http://w3.org"
</rdf:RDF><rdf:RDF> is a root tag which depicts that it encloses a RDF document.
Now look at this :
<rdf:RDF>
xmlns:rdf = "http://w3.org"
<rdf:Description rdf:about = "http://example.org/person#Bob">
</rdf:Description>
</rdf:RDF> I have added Description tag which describes the Subject, Bob and it has unique id http://example.org/person#Bob. (Unique ids are given to exchange data globally and these are called URIs - Unique Resource Identifiers)
Now have a look at this:
<rdf:RDF>
xmlns:rdf = "http://w3.org"
<feature:dob> 31-07-1992 </feature:dob>
</rdf:Description>
</rdf:RDF> This little addition of feature tag shows the property of Bob which is called Predicate in terms of RDF.
<rdf:RDF>
xmlns:rdf = "http://w3.org"
<rdf:Description rdf:about = "http://example.org/person#Bob">
<feature:dob> 31-07-1992 </feature:dob>
<feature:friend rdf:resorce = "http://example.org/person#Alice"/>
</rdf:Description>
</rdf:RDF> Now I added another property but it has not literal value like the previous one i.e. DOB. It refers to an Object Alice with unique id. And it could be a Subject in another statement.
Ontology
Ontologies are also graphical representation of data which shows contextual relationship between the defined vocabulary. OWL syntax is used to describe it. Just like RDF is a syntax, OWL is more diverse and have wide range of vocabulary. You can check this link for an example.
Although I can show you a visual example of Ontology.
Image Credit: Wikimedia Commons, CC SA 3.0
{kind=link}
SPARQL
Just like MySQL, it is also a query language for retrieving semantically structured data.
Select , Where , From, Order By clauses are used in this language as well.
Let's learn through an example:
Data:
John(S,http://example.org/person#John) lives(P, http://example.org/person#lives) in Canada(O).
Alice(S, http://example.org/person#Alice) lives(P, http://example.org/person#lives) in Russia(O).
Bob(S, http://example.org/person#Bob) lives(P, http://example.org/person#lives) in Columbia(O).
Anna(S, http://example.org/person#Anna) lives(P, http://example.org/person#lives) in Canada(O).
I have mentioned Subjects, Objects and Predicated and URIs with each entity.
SPARQL Query:
PREFIX persons <http:example.org/persons>
SELECT * WHERE
{ ?name: persons:lives ? "Canada"
}In this query we are trying to retrieve the name of persons who live in Canada. The result will be like this:
<sparql xmlns="https://w3.org/sparql-results#">
<head>
<variable name = "name"/>
</head>
<results>
<result>
<binding name= "name">
<uri> http://example.org/person#John </uri>
</binding>
</result>
<result>
<binding name= "name">
<uri> http://example.org/person#Anna </uri>
</binding>
</result>
</results>
</sparql>I hope you understand what will it look like.
Note: These codes are just to give a glimpse. I haven't run them on any applications. You need to go the proper way to write these when working on a project.
Why Semantic Database is needed to gather World's Data?
I will start with an example explained in this link. If you don't want to read, I'm summarizing it anyhow.
There is a website A which has information of all the actors and their short biographies, the movies they have worked in, the awards they have won.
And there is a website B which has all the information of released and upcoming movies, the actors that worked in those movies, the awards movies won.
A user opens website A and starts looking for example Leonardo Di Caprio and opens the list of movies he has worked in. A movie Inception came across the list. He wants to know more about the movie but the website doesn't provide any information.
One solution: He could search separately about that movie in another site like B.
Second Solution: Implementer of site A could leave hyperlinks of movies which would lead the users to site B.
But this needs to be done beforehand, to know what kind of information a user could demand. And when both sites are implemented using different databases then joining tables would be difficult too. Because an entity "actor name" could mean something else or nothing in another database. Either the two websites have to be implemented by the same person or both websites owner could make a contract of pre-decided vocabulary, they would use.
Still there is a weakness in the solution. When we try to gather data on a much larger scale, things get complicated. We all know that primary keys can help join tables and so does the foreign keys. But do they really know how they are related. Columns names suggest links to other tables but that is not enough. Characteristics of a column may also suggest something like giving us some insight into the Semantics. Which is lacking in all traditional databases.
You may want to read this article for detailed description of how Semantic Database is better.
Successful Examples of Semantic Web
- Facebook is using Open Graph Protocol which is like RDF.
- Microsoft, Yahoo and Google are now using Scehma.org which is aslo similar to RDF.
- Chevron is using semantic web to combine and understand arbitrary data and are getting successful outcomes.
- BBC is one of the biggest example of semantic web application lately.
- Biogen Idec (pharmaceutical company) is another great example.
You can read details of how they are using Semantic Web in this link.
Drawbacks and Future of Semantic Web
Semantic Web is a great idea but the major drawback is rewriting the whole web. There has to be some other way of linking all the data without starting from scratch.
Artificial Intelligence is making huge advancements by making computers smarter than ever. Would there be any need of Semantic Web then? What if both technologies are combined and we advance exponentially in technology. Who knows !
References
- http://www.linkeddatatools.com
- https://www.cambridgesemantics.com/blog/semantic-university/semantic-technologies-applied/example-semantic-web-applications/
- https://www.w3.org/2007/03/VLDB/
This a very good question that I am sure, eventually, developers will be able to answer. We just have to wait. Great post!
Yes, I hope they combine the both techniques. 😊