Building a bot for StarCraft II 4: Results and Conclusion
Rewards
| Episode | Reward | Minerals | Gas |
|---|---|---|---|
| 2104 | 446064.0 | 2345 | 468 |
| 19972 | 437483.9 | 1775 | 556 |
| 33434 | 388482.7 | 2375 | 432 |
| 60775 | 368278.0 | 1410 | 644 |
| 22227 | 356823.1 | 1315 | 452 |
| 32624 | 355436.2 | 1545 | 500 |
| 21229 | 354093.9 | 2590 | 164 |
| 25682 | 352979.6 | 2975 | 0 |
| 19094 | 340669.9 | 2930 | 0 |
| 32586 | 339692.5 | 3095 | 0 |
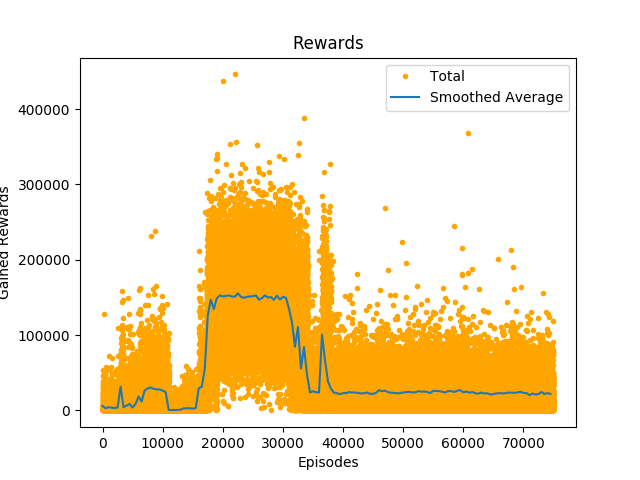
Figure 1 shows all the gained rewards for every episode as well as the smoothed average of the rewards. Both plots show a very steep increase in the gained after around 15000 episodes. This lead to a plateau at a reward of around 150000 from around 17000 episodes to around 30000 episodes, where rewards were rather high in average with a few very high outliers. From 30000 episodes to 35000 episodes the average rewards were constantly decreasing, with two spikes, due to very high or rather high rewards. Around 36000 episodes there is another spike in the average rewards, that is around 100000. From that on the rewards reach another plateau at around 40000 till the end. Looking at the plot of all rewards shows that there is a high variance in gained rewards.
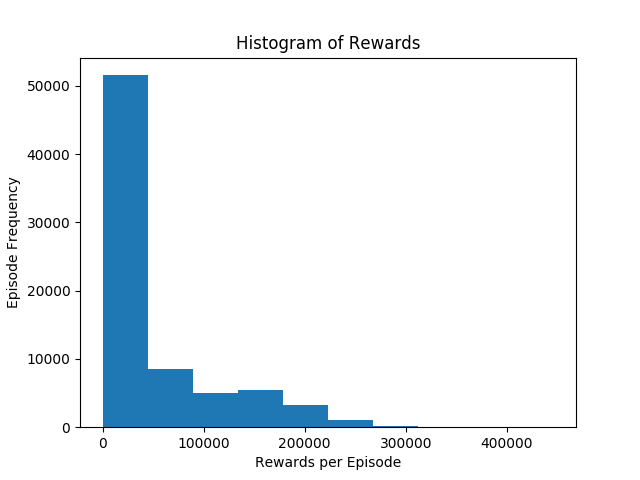
Figure 2 shows that the vast majority of episodes is in the first bin, meaning that they had a reward from 0 to 44606.4, this also shows that the agent was stuck in a plateau where the reward was around 40000 for most of its runtime, more than 50000 episodes fall in this bin and only had a reward between 178425.6 and 223032 than between 133819.2 and 178425.6, which is not apparent from the plot of all rewards.
Table 1 shows the top 10 episodes in terms of rewards. The top 7 episodes are episodes which are a combination of relatively high amounts of collected gas and high amounts of collected minerals, while in the last three episodes only minerals had been collected. The reason why the episode with a higher mineral count is because for the log files I use the last reward and not a sum of all rewards in an episode. By doing so, it is also visible if an agent performed actions that led to a decrease of the reward. This happened e.g. in episode 32586, where the agent started collecting minerals quickly, but then performed actions that didn't contribute to the increase of the reward and thus leading to a lower reward even though the total amount of collected minerals is higher than for e.g. episode 19094. Note that the final reward is only used for logging, for training the agent all cumulated discounted rewards that the agent receives are used.
Minerals
| Episode | Reward | Minerals | Gas |
|---|---|---|---|
| 32586 | 339692.5 | 3095 | 0 |
| 37906 | 327749.7 | 3045 | 0 |
| 30191 | 277834.5 | 3020 | 0 |
| 29342 | 337969.1 | 2995 | 0 |
| 17437 | 261376.8 | 2980 | 0 |
| 25682 | 352979.6 | 2975 | 0 |
| 30978 | 258900.1 | 2965 | 0 |
| 24885 | 256661.0 | 2960 | 0 |
| 30162 | 334053.1 | 2960 | 0 |
| 26006 | 316695.7 | 2955 | 0 |
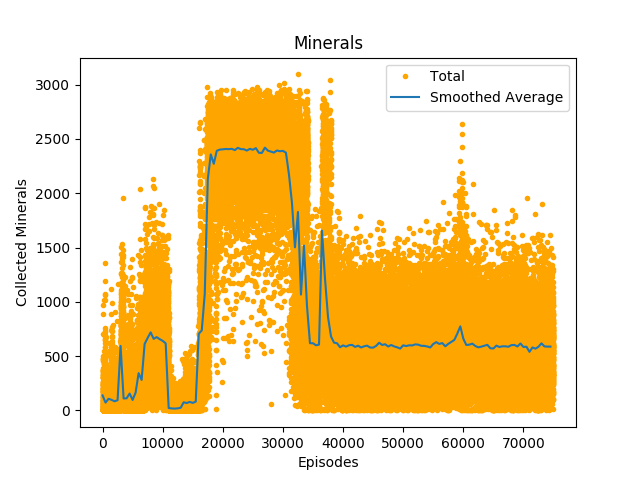
Figure 3 looks very similar to figure 1, indicating that the collected minerals are mostly responsible for the gained rewards. Also around 15000 episodes there is a steep rise in the amount of collected minerals, to slightly less than 2500 collected minerals per episode. As for the gained rewards, the agent stays at this plateau until around 30000 episodes, until it steadily decreases to around 700 collected minerals per episode until the end, there is also a spike around 36000 episodes, where it goes up to around 1000 collected minerals per episode. Around 59000 episodes there is also a small spike up to 800 collected minerals per episode, which does not have much influence on the gained rewards. Note that here the variance is also very high, but around the one high plateau, there are almost no very low outliers, meaning that during this plateau the agent practically collected minerals during every episode.
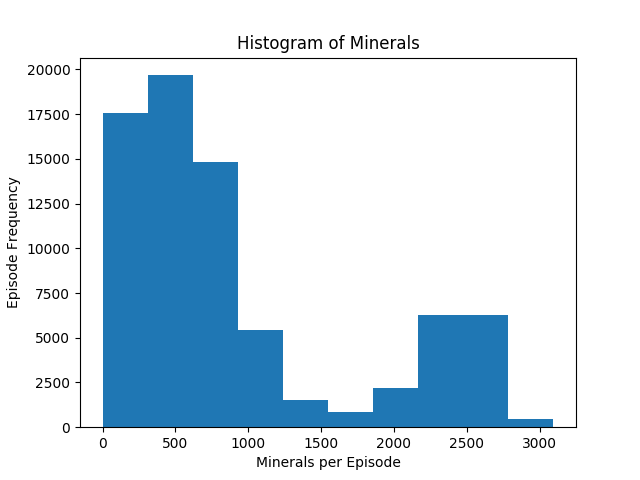
Figure 4 has also some similarities to figure 2, but there is one obvious difference: the bin with the most episodes in is from 309.5 to 619, so there are more episodes where the agent collected at least 309.5 minerals than where it collected no minerals. Also the plateau of where the agent collects between 2476 and 2785.5 minerals per episode for around 14000 is easily visible in the histogram. This influences the slight spike in the histogram of the rewards, although since the influence of collected minerals on the total reward is damped, it is not so visible in the rewards histogram.
Table 2 shows the top 10 episodes in terms of collected minerals. As mentioned above also here a higher amount of collected gas does not necessarily mean a higher amount of gained reward. It is notable that even though most of the top 10 episodes happened when the agent reached the highest plateau, the three episodes with the most collected minerals happened when the agent left this plateau and the are responsible for the spikes in the figure 3. Episode 17437 might be responsible for the steep increase in gained rewards and collected minerals that is visible in figure 1 and figure 3, together with episodes 19972 and 19094 as shown in table 1 because they gave very high rewards early in the agent's runtime.
Gas
| Episode | Reward | Minerals | Gas |
|---|---|---|---|
| 47860 | 152955.0 | 760 | 708 |
| 60775 | 368278.0 | 1410 | 644 |
| 18985 | 334472.5 | 1595 | 636 |
| 58515 | 244735.3 | 1100 | 604 |
| 61472 | 187292.0 | 665 | 588 |
| 67944 | 213293.6 | 915 | 584 |
| 6113 | 106560.4 | 480 | 580 |
| 62611 | 160610.8 | 355 | 576 |
| 19972 | 437483.9 | 1775 | 556 |
| 4370 | 127439.7 | 640 | 556 |
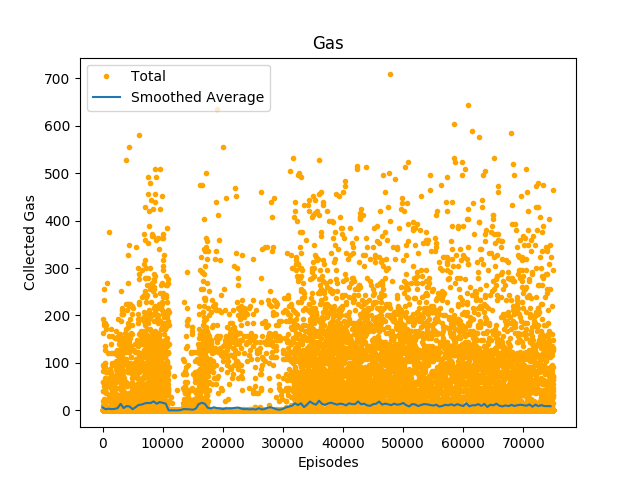
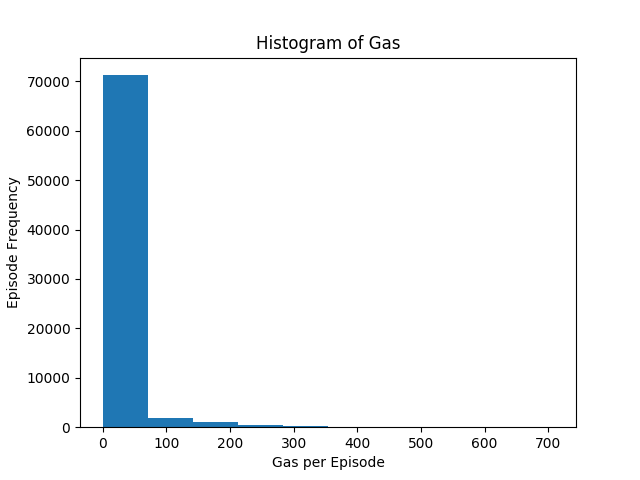
Figure 5 shows how much gas an agent collected per episode, was well as a smoothed average. The variance is even higher than for rewards or collected minerals. The smoothed average is very low and usually around 0, but there are some very high outliers. The smoothed average is oscillating between 0 and 20 gas collected per episode. This indicates that the agent has not learned how to collect gas and that the higher amounts of collected gas are the product of the random exploration. Looking at figure 6, the histogram of collected gas, strengthens this assumption: over 70000 episodes collected between 0 and 70.8 gas.
Table 3 shows the top 10 episodes in terms of collected gas. This table again highlights the rather random nature of the agent's gas collection. Even though collecting gas is higher valued than collecting minerals, the rewards of the top episodes for collected gas can not compete with the top episodes for collected minerals in terms of gained rewards, with the exception of episodes that also have a high amount of collected minerals, especially again episode 19972.
Analysis of Actions
| Action | Occurrences |
|---|---|
Harvest_Gather_screen | 53.57% |
no_op | 18.073% |
select_point | 5.2032% |
move_camera | 5.1394% |
select_idle_worker | 3.6681% |
Move_minimap | 3.3873% |
Move_screen | 3.3578% |
Build_Refinery_screen | 2.2372% |
Build_SupplyDepot_screen | 1.8124% |
Build_CommandCenter_screen | 0.80255% |
Rally_Workers_screen | 0.75193% |
Rally_Workers_minimap | 0.74176% |
Harvest_Return_quick | 0.55428% |
Morph_SupplyDepot_Lower_quick | 0.36859% |
Morph_SupplyDepot_Raise_quick | 0.33171% |
| Action | Occurrences |
|---|---|
move_camera | 5.1196% |
no_op | 5.1023% |
select_point | 5.0814% |
select_idle_worker | 3.6396% |
Harvest_Gather_screen | 3.4297% |
Move_minimap | 3.3873% |
Move_screen | 3.3578% |
Build_Refinery_screen | 2.2372% |
Build_SupplyDepot_screen | 1.8124% |
Build_CommandCenter_screen | 0.80255% |
Rally_Workers_screen | 0.75193% |
Rally_Workers_minimap | 0.74176% |
Harvest_Return_quick | 0.55428% |
Morph_SupplyDepot_Lower_quick | 0.36859% |
Morph_SupplyDepot_Raise_quick | 0.33171% |
| Action | Occurrences |
|---|---|
Harvest_Gather_screen | 50.141% |
no_op | 12.971% |
select_point | 0.12185% |
select_idle_worker | 0.02849% |
move_camera | 0.019841% |
In order to keep the file size of the logfiles reasonable only the actions for the top 10 episodes in terms of collected minerals and collected gas and the last 10 episodes where kept. For 16 agent instances this makes a maximum of 480 episodes. In my case 468 episodes were analysed with a total of 393120 actions.
Table 4 shows the frequency of all actions, table 5 shows how many of them were random and table 6 shows how many of them were not random. Especially table 6 shows that the agent learned the relation between performing the action Harvester_Gather_screen and getting a high reward and therefore tried to perform this action over 50% of the time. It also learned that sometimes doing nothing is also beneficial for achieving this goal, so no_op is the second most frequent performed action. The actions for selecting: select_point and select_idle_worker were also learned from the agent, but only performed in very few cases. Taking a look at the action logs shows that the agent needed to perform a random select action before it was able to send worker units harvesting. This means that the agent did not learn the rule that it has to first select worker units, before it can send them to harvest. It is notable that the action select_idle_worker gets less often chosen by the agent than the action select_point, even though this action is easier to perform, since it requires no position. The agent was not able to learn the relation between building a refinery and collecting gas, since the action for building a refinery (Build_refinery_screen) only gets performed as random action.
Running the Agent on a different Map
The trained agent was also run on different maps than the one it was trained, but without much success. Since the training map did not require any exploring of the map1, the agent was not really able to perform much exploration of the map for finding new resource patches, so it was just performing the same actions as it was doing on the training map, so it lead to the same results.
Interpretation of the Results
As written above, the agent was able to learn the relation between giving the command Harvester_gather_screen and an increase in reward, but the agent was not really able to learn the rule that it has to select a worker unit before it can give the harvest command. One reason for that could be that episodes where the select_idle_worker was given early on only returned relatively small final rewards. For example the episodes 63074, 34261 and 64866 the select_idle_worker command was given quite early, but the total amount of collected minerals was rather low (except for episode 64866), also the final reward wasn't as high as one would expect. This is due to the agent ordering the worker units to harvest early on, but then gives other commands, which keeps them from harvesting. Another special case is episode 37906, it was the second best episode in terms of collected minerals and also the reward was quite high. In this episode the agent didn't give much useless commands, that kept the worker units from collecting minerals. The reason why I was only looking at the select_idle_worker command is, because there it is more likely that the agent actually selects a worker unit, for select point this can not be said, since the agent could also select a random point and so selects no unit.
The agent not learning the relation between selecting a worker unit before it can give the harvesting command also explains why the agent wasn't able to learn how to collect gas. In order to collect gas it had to also learn the relation between building a refinery at the right position, something it also didn't do.
The agent performing some select actions, and especially that those actions were performed rather early, indicate that the agent would have been able to learn this correlations, if given more time. After 75000 episodes the agent was stuck in a local minimum and the average rewards as well as the average collected minerals per episode were plateauing. It is difficult to say, how long this plateau would have lasted, but given that the agent reached a higher plateau before it is likely that the agent would have left that local minimum.
Conclusion
Running and observing the behaviour of the agent leads to the conclusion, that the state space of StarCraft II is so large, that it can not be efficiently explored by a reinforcement learning algorithm without specialised hardware, even though with the A3C algorithm a reinforcement learning algorithm that is known to have rather low resource demands was chosen.
The agent showed some "intelligent" behaviour, especially since it learned the relation between harvesting resources and an increase in reward. From the action logs of the agent however it is obvious that the agent did not learn that it had to select a worker unit before it can give the command to harvest minerals nor did it learn how to harvest gas. The data from the action logs however also suggests that the agent could learn the relation of selecting a worker unit before it can give the harvesting command, if it is trained for a longer time.
Two things that possibly could speed up this convergence process are using the single_select tensor as input as well as performing an update after n steps instead of after every episode. The former would give the agent a more direct feedback whether a select action was successful (so far this feedback is only given indirectly by whether more actions become available), while the latter would make improvements in the action policy faster available to the agent.
Another possibility would have been to give the agent more guidance in the learning process. It might would have made the agent faster in solving the task, but it would also required more intervention from my side and would override one big advantage of reinforcement learning: that the agent is able to find a solution with little to no prior knowledge build into it.
Good.. project.. congratulation...
Thanks :)
this is a bot/spammer I think)
You are rising a good point (with both of your comments), but I think that both are rather newbies than spammers.
just saying, nevermind)
U r interesting only in posting Ur articles into blockchain or making some money too?
I'm asking it 'cause U have not that much posts.
I'm interested in both, but unfortunately I have a lot of other things to do, so writing articles for Steem tends to fall a bit short.
Finishing this project is a good example: while I was doing so (in March), I didn't find time to write or post anything.
in case to increase rewards (slightly=) - just make more posts.
imho.
Yes, I'll try that. I have already quite some ideas for posts.
I guess the best thing would be if I force myself to post at least two times week or so.
Cool article, thanks to the author for his outstanding thoughts, Respect you
Thank you :)
compare this message of him with previous one in your post)
Congratulations @cpufronz! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOP