Forensic Approach to Cheaters

Golden Chopsticks or why some cheaters suck at photoshop
As I mentioned in my post double-blind violins: towards a more objective selection there are problems that arise when one lowers the entry bar for judges of quality in a system. One of them is cheating.
The surface of attack for cheating is broad, yet it can be sub-divided into two main categories: a) Fake events and b) excessive events. Here I'll cover the first category.
- [ ] How to know if an Image is photoshoped: Gold chopsticks
- [ ] Oracles
In any interaction, you can either have cooperation or not. The first bottleneck for this is communication.
The prisoner's dilemma is an example of a non-cooperative game, where what's best for oneself is not best for the collective gain. In the classic game, communication is not possible and is the main reason people are forced to choose what's best for them, by finding the dominant strategy in the game. A heuristic they rely on a FOO (first-order optimal strategy).

As the rewards for something increase, systems of reputation signaling appear to select based on skill to avoid putting noobs against advanced players as it would be a waste of time for both parties.
This creates another problem known as power creep. This is when early adopters accumulate an almost insurmountable advantage over newcomers. This is the pyramid dilemma of markets.
Skill imbalance is the main reason for cheating, but not necessary or sufficient. People cheat if they either can or want to get away with it. I'll proceed to elaborate on this and give you FOO.
Background
An image is a graphical representation of an original source for a defined period of observation. The limitations of perception and size of this representations can be extremely big by modern standards, so in order to manipulate them, we use different types of compression.
Due to the way our photoreceptors and brain process light, we perceive better changes in intensity of light (mesopic vision) than changes in color. Our resolution discernment scale goes: Scale of Grey > green 2x > blue and red x.

Also, We don't see high-frequency changes in image intensity, and this pieces of information we see as a blur due to the contrast sensitivity function.1 This means several combinations of light representation can have a similar perception effect for us. These representations are called a color space.
Depending on the medium and the part of the process - e.g. capture, manipulation (HueSaturationLightness), display (RedGreenBlue), high definition (Y'lumaCblue differenceCred difference), WEB (HEX) or printing (CyanMagentaYellowKey) - the color space is different.
Taking advantage of this we downsample the color in order to reduce the size of the image. Then we can use lossless or lossy compression.

In lossless compression, we use statistic modeling to find the frequency of redundancies in the data and change them for a representation of their position (chunking), when we uncompress it is exactly the same before compression. Examples of these formats are .BMP and .PNG. Some people argue that images for science purposes -especially if the image contains relevant edges like text- should use lossless compression.2
In lossy compression, as the name hints, we downsample the color and we also use a mathematical technique known as Discrete Cosine Transform3 (DCT) to weight and eliminate by intereference highfrequency information, then we use quantification of the image and encode it, destroys data in the process. The big advantage is it reduces size massively when compared to lossless compression and changes are almost imperceptible for most uses by humans. The most important example here is JPEG.
JPEG (Joint Photographic Experts Group) is the standard in pictures. JPEG is not the file format but the compression codec, we actually normally use the format .JFIF and more recently other derived new standards like .Exif.
Let's use an image in the format .BNP with the YCbCr color space. With YCbCr the luminance we separated the luminance from the color by a factor of 10 and thus we can eliminate x100 information without most of us noticing. Most of the time we only downsample by a factor of 2.
A cosine function is a function that goes between 1 and -1 on the Y-axis. If we represent our data in the form of many cosine waves, due to the fact we can't perceive well changes in high-frequency information, we can get rid of high frequency data and our perception of it won't change much depending on the scale.
Suppose you have an image composed of pixels in a scale of grey. By modern standards, this means it goes from 0 - 255 shades. The JPEG algorithm divides the image in 8 by 8 blocks. Each of the groups can be represented by 8 by 8 cosine waves.

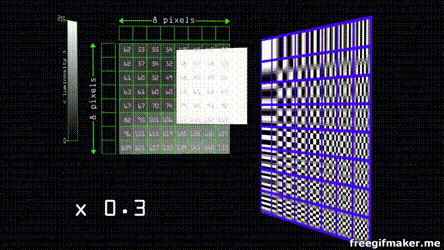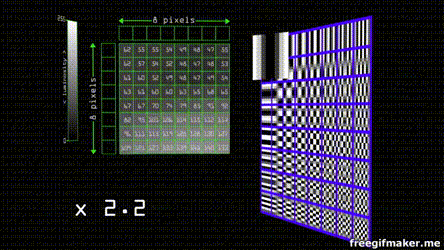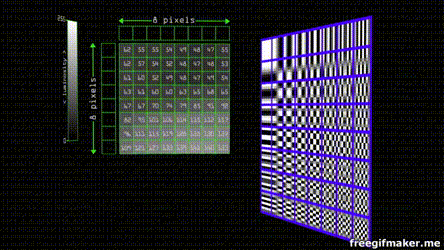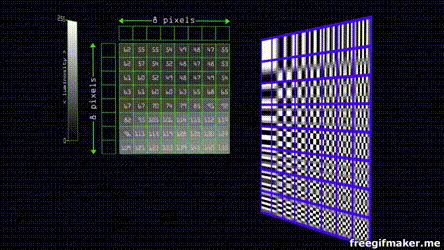
Each one of the waves has a weight that contributes to the resulting final combined wave.
Since the grayscale in our color space goes from 0 - 255, we find the center that is 128 (as the function goes from 1 to -1 and our center is zero) and after applying the cosine transform we multiply the values of weight by each one of the waves to obtain the final sum

Despite JPEG being an standard there's no concensus for the parameter that of the transform and quantization tables. Each program or camera brand has individual quantization tables. that depending on the quality divide the values depending on weight and round the result to the nearest integer , the effect is that almost all of the values get converted into 0, except for the ones on the top left that have the more weight and lower frequency information. This can be compressed even more by serialization of the entropy (Huffman coding) of most of the zeros.

So why is this important?

Some people might try to take advantage of this to create images that could pose a big threat to our perception of reality and we need to know if they are fake or if we must start fearing for our lives.
An approach to this is metadata. You have a trusted device and does some kind of encryption to the original to certify it has not been tampered with. An example to do this with your phone is with image hosting sites like izitru, that perform basic forensic analysis to pictures to determine if they are original, the problem is that they can be oversensitive with false positives and difficult to use.
The problem with this approach is that it requires specific hardware and the sites are vulnerable to being hacked like it happened to Nikon and Canon that tried to mass do this a couple of years ago and making their hardware obsolete, costly.4

Since each device has its own quantization table, if we have at least the metadata of the model for the camera we can compare the quantization on the picture to know if it has been altered. This is an actual advantage of JPEG over the .PNG format. The dimensions and the Huffman codes also work as signatures and each JPEG is accompanied by a thumbnail, that also has its own unique dimension, quantization table, and Huffman code. The particular alteration is not known but it tells you there's a breach in the chain from the original.
An act as simple as saving a file in a different program can alter the data, at each point of modification the process loses information. An analysis of the distribution of information would reveal if it has been recompressed and how many times as one just needs an alteration in a single channel of the many a picture has.5
The problem, once you have an image that is not an original, is what has changed.
FOO tools: Shadows and Reflections

The physics of how shadows are cast is hard. Even game engines have problems with this and occasionally break real-world physics by a lot. Testing if there's a mistake is actually a lot easier. Not in vain little kids and some animals get flustered and even scared by them, even our perception of color get's distorted by the extra-transformation it requires. In the image the green points and lines show congruence, the red points and lines show a modification to the shadows.6
You find a possible light source and start tracing points in the shadows, from the edges to the perspective point. There are tools that automatically check this but still need manual tweaking and are expensive.6

One might wonder if testing for a perspective projection is so easy why people that modify images don't do it? mainly because lying consistently is exhausting. It has been tested an people take shortcuts and rely on intuition to discern everyday life things.6
Most won't take the time and even if they have the artistic training they tend to overdo it because real life shadows are not necessarily aesthetic, they just are. 6
All sort of things gets into play. The lens causes all sort of spherical aberrations, color splitting due to Snell's law, vignetting due to the aperture of an image. A lot of points of failure for someone that wants and knows where to look. 6

In the case of reflections, checking for projections to an imaginary point is how you do it, but it becomes a lot harder. Especially if the surface is not flat. The orthogonal projections on a flat surface create a cube that can be traced by points correlated.6
Convex, concave or asymmetrical reflections introduce orders of magnitude more difficult problems for the cheater (physical, optical, digital and compression). Since people have not experience distrusting their perception of the world they deem themselves good at recognizing when they are cheated, remaining in obscurity not wanting to feel cheated. This is the Dunning-Kruger effect.6
More advanced, yet not that difficult skills
I'll be explaining this using the free online forensic software AMAZING tool by Jonas Wagner Forensicallybeta


As you might remember, every time we make a save a JPEG file we compress it again. This is the principle of error level analysis (ELA). Is a technique that saves the picture and compresses it at 95% and compares it to the original, so one can look for places where there are conspicuous areas where compression is not uniform. Sugesting a mix of different pictures
As a rule of thumb, you compare surface to surface and edges to edges in order to find alterations in an image. Performing ELA is no different.

Lenses have imperfections and dust, they introduce the same or more artifacts everytime they are used. They can be identified like a bullet can be traced to the barrel of a gun.
Another cool feature is the cloning detection tool. It finds patterns that are similar, possibly the result of copy-paste or the cloning tool in photoshop or similar programs.


Going from the highest quality to less tolerance down shows places that are suspicious of modification. The tool doesn't host the images, it can take some time as it's beta to show the changes depending on the resolution of the image.
After giving this tools we can bite the meat of the problem I want to discuss.
Golden Chopsticks
The particular way of communicating the results of the scientific process (test and evidence) is called peer review. Contrary to popular belief is not experts exchanging opinions based on their knowledge, but a reputation based inquiry of methods and consistency inside the provided piece of communication known as papers.
Not all science is equal and the limiting factor is the testability. Some fields like mathematics have near to 100% testability inside the paper. Some others like biology, have close to 0%.
Is closer to a legal system. A central actor, the editor (judge), gives the summary of the evidence to a couple of witnesses and asks:
Did they test this in the right way? is this an accepted method? Did they use the accepted standards of evidence? Did they gather enough evidence of the right kind? Does the math checks? Is their conclusion reasonable based on what they have? Did they go beyond and speculated too much? Is this product or is it completely unconstrained?
The editor then picks based on the different reviews and decides what to do. Accept it after some corrections or flat out reject it.
What peer review offers is a system of proof. A proof of work by the reviewers. Some rely on this as enough and start building on top of it. For others is the starting point of the paper. Just like with a legal system, the defense attorney and the prosecutor still have not made their entrance on the scene. So the groundbreaking pieces go into peer review journals that reject >90% of the submissions or open access dissemination. After getting the best peer review they can convince or fool.
An example of this going wrong is the now retracted article "Chopstick Nanorods: Tuning the Angle between Pairs with High Yield"7 in 2013, about a particular orientation in gold nanorods after being synthesized in solution and getting a 90° orientation on a surface. After being published in Nano letter A journal with good reputation, peer review and impact factor at the time.

Attention was brought to it after Mitch at Chemistry-Blog did a post on some suspicious TEM images. As you can see in the close-up, suspicious indeed... MS Paint?
Just as interesting as the fact that the writers lied, was that they lied so badly. What if they had done a better job at faking it. In fact, it didn't take long for someone to show just how much better it could have been at Chembark's blog.

I performed photoforensic basic analysis on the improved version, with good results. The ELA and noise analysis didn't help much as there's a lot of noise in TEM images and the source of the modification probably don't come from a different picture, but the luminance gradient shows the abnormal orientation of illumination, there was some clone modification and the metadata shows photoshop was used on it. A truly dedicated liar that beforehand knows this analysis is going to be performed can do an even better job. It's a cat and mouse race.
This illustrates a current string of problems. There are more and more scientists, there are more publications and papers and the pool of funds for science research is not growing at the same pace. This breeds a scenario where cheating is a viable alternative. Scientists are not experts at not being cheated just for being scientists. It also means they are not great at lying but that is changing fast.
Cases of researchers attacking the vulnerabilities in the computerized systems of publishers have made possible for them to become their own reviewers by faking their identity and creating review and citing rings.8 Alternatives like stopping the suggestion of possible reviewers by the author have been made. Others like double-blind review are far more common in the humanities where unconscious bias are a more common worry.9
The paradigm of cybersecurity is that access equals ownership. So once systems become more technical and automated there are more ways to game them by hackers. Anonymity and automation are where hackers thrive.
Oracle systems
Despite most of the important discoveries in modern history being the result of side projects that had close to no apparent immediate use or support, like the transistor. Patrons of big research (most of the time the government) need to ration the projects they consider will have a bigger impact on society.
The problem keeps on being the finite pool of money, the proposed solution to this is apparently predictions markets.
The layer of crowdsourcing can be surprisingly accurate in optimization problems.10 Most likely you can't gamble on what's gonna be the next big breakthrough in science, but you can bet on who is gonna make it or who can find the person who can make it. Finding the dark horse is the most profitable thing as the odds are against it. Of course gathering the wisdom of the crowds is an argumentum ad populum. That's what governments and private institutions are doing.
Prediction markets are no different from gambling. Some like Jaron Lanier argues that crowdsourced and open source initiatives expand opportunity at the expense of quality and stifles innovation11.
Crowdsourcing pre-print reviews seem like the way to go. By increasing the surface of attack to find mistakes. Although this opens the road for other problems like plagiarism. Identity is one of the many vectors of attack if you wanna read on plagiarism I did a post on it. Freedom and speed, or security and stability.
Some people like the former editor in chief of the British Medical Journal Richard Smith, say that Peer-Review is a sacred cow ready to be slain. Most fear that the fall of peer review will create an environment where popularity is more important than evidence. The problem seems to be what's called the asymmetry of plausible-sounding scientific bullshit, is easier to produce bullshit than to prove it wrong.12 If an author wants to, for instance, bury the reviewers they just need to introduce ambiguity in their references and now the reviewer has to deal with dozens to hundreds of papers if they want to debunk the claim. A form of spam attack.
As I mentioned early, the more math involved the more reproducibility. For most disciplines, scientists rely on basic statistic interpretation of the paper, if it rings true and impact factor of the journal.
Impact factor (IF)is a metric that measures the ratio of citations on a period of the previous two years (A) over the sum of reviews and research articles on the same period of time (B). IF=A/B 13
Other types of metrics like the eigenfactor Score, article level metrics and author influence are growing. Just like the use of other social web alternative metrics14 (Altmetric, ImpactStory, Plum Analytics, PeerEvaluation, Research Scorecard, Mendeley, Acumen)
As testing and evidence become more costly for individuals in some fields, transparency is king.
Initiatives like Retraction watch and PubPeer for tracking good and bad practices in research are important and probably will gain more relevancy as publishing continues to change.
Some things benefit from perfect open low barrier access, some others from high barrier closed ownership. Access equals ownership is a combination of all the bad and the good.
The forensic approach is one of checking transparency. Finding ways to probe at lack of it. Making the invisible visible.
You can't have security through obscurity* the same seems to apply to any other form of data reliability. Tools to make cheating practice more costly are what I have mentioned and showed here by increasing transparency. Does this mean you can avoid being cheated by others with this approach? no, but if someone wants to fake it they've gotta really put in the sweat, personally I'll make you work hard for it. Thanks for reading.
References
2 Amit Agarwal. JPEG vs PNG, image quality of bandwidth. Labnol.
4 Nikon Image Authentication System: Compromised April 28th, 2011 by Vladimir Katalov
9 Cressey, D. (2014). Journals weigh up double-blind peer review. Nature.
12 Earp BD. The unbearable asymmetry of bullshit. HealthWatch Newsletter 2016;101:4-5
13 Assessing Journal Quality: Impact factors. Boston college libraries, research guidelines
Images referenced, sourced or modified from google images, labeled for reuse
When I read the Violins post, I thought that you can't go further, but somehow you found a way to surprise me again. Thanks for your contribution!
I was about to read the full post cause you started it with photoshop in your introduction, then I scrolled down, i saw a lot of scary numbers, LOL. No, I can't take this. hahahah. peace ertwro.hahahaha
Ignore the numbers. Just go to the part where I talk about shadows, mirror reflections and a free online program to find if a picture has been photoshopped. Is super easy to use. As an artist you can maybe find it useful some day.
Woo! Long one, but a good one. I'm really glad I'm in geology- thankfully a lot less in the way of falsifying data than in, say, the biomedical fields.
It's a shame. The accepted figure for fraud is close to 2% for all scientists. 1 Of course, the least fraudulent are astrophysicists and the most fraudulent are in the biomedical field, 2/3 of the retracted papers are due to scientist misconduct (>45% alleged fraud)2 rather than to error, specially with images :'(
1 Fanelli D (2009) How Many Scientists Fabricate and Falsify Research? A Systematic Review and Meta-Analysis of Survey Data. PLoS ONE4(5): e5738.
2 Misconduct accounts for the majority of retracted scientific publications
F. Fang-R. Steen-A. Casadevall - Proceedings of the National Academy of Sciences - 2012
This is a very interesting post. I had not realized fake photo had been used to "out" fake research. In the ICO area, it might be helpful to have someone review the photos on the sites. We know so many of the ICO are fake and frauds, but at times it can be hard to put your finger on the "proof." Mainstream news could use these tools as well as the Iranian Missle launch pointed out a few years ago. Of course we also have to remember one easy way around the digital characteristics of photo editing is to print out a large photo and then take a picture of the picture. The picture will pass as real, because it was not edited on a computer.
I really like how you merge topics in a single post. The intro on image compression could have been a post on its own!
I have the chance to work in a field where experiments are always coming as pairs (or more) so that any discovery could be at least reproduced one. Consequently, it was hard to me to understand, in the beginning at least, why such things could not be done in other fields.
The lack of basic mathematical rigor is outstanding. What makes me sad the most is the lack of imagination for how to perform experiments.
A friend of mine that is an I.M. specialist recently asked me to write a paper with him, I told him yes. I made a pre-print proposal. Told him 5 different ways to test the same event and he told me they were not standard and excessively complicated -Of course but that's ok, we just need to develop the protocols from ground zero. Don't worry I'll do the heavy lifting-
He told me it was to much work for something that for the way I presented it had too many ways to be proven wrong. He said: can't you make it less mathy, more ambiguous?
-No, I'm not a philosopher.- he wanted for us to publish the pre-print as a full article without any experimentation! I had to decline any collaboration.
:'(
I am chocked. After, we should not be surprized when the general audience complains about science!
This is far too technical for me but worth the effort on your part as you can expose the wrongdoers when it comes to uploads. I just unfollowed a couple of people today that I was blithely giving upvotes for and it turns out all they did was put photos or news stories I could have got for myself! By the time I twigged what was going on I had to go to Smeeitchat to find how to delete them from my feed list. (Unfollow!) I like the idea of freedom but sometimes it is abused and the people who work hard at Steemit (good post and good curation) don't get the merit they deserve. Thanks for this post - even if most of it is above my head!
I want you to take out of this just a couple of points:
Thanks for passing by. Glad you liked it and powered through it.
Thank you. It's a kind of expose in its way and we need it where we're at right now. Happy Steeming!
Incredible post, mate.
Lots of parallels to steemit in your discussion. This is most excellent.
Is all game theory. Games are preparing us for the future.
Another tool I have heard is useful in Benford's law. Numerically, most natural data in the world starts with a 1 (31% of the time) then a 2(17% of the time) and decreases down to 9 (like 4% of the time) and this can be used to detect fraud, fake accounting, and fake data sets. I heard it was fairly useful of photographs as well.
The natural distribution of numbers. It works in hidden data like first layer steganography but you need to rearrange the data first in a way that is numerically suspicious. Distribution checking on encoded data is not among the most common or useful options. Is useful in other scenarios.
Informative and deeply educational one @ertwro when I starts reading this it I feel little lagging and lots of supporting links attached..I want to know about the content deeply I go each link attached to the area.. it’s take long time for me to cover the article.. but at the end I feel so much interesting article.. keep it up my friend.. and we are expecting more like this from you..
👍👍👍
Yeah, I'll try to include more links and work on making future articles more relatable.
Thank you
Cute Cat Cubs...

In a picture similar to this image Andreas Antonopoulos used to hide stenographically a 100mm transaction. I'll check just in case.
its favorite pic