Dla początkujących użytkowników Steem: trochę o blockchainie Steem, wynagrodzeniu kuratorskim i kategoriach.
Tytułem wstępu
Użytkownik @piotr-galas zadał pod wpisem @noisy'iego kilka pytań, na które poniżej postarałem się odpowiedzieć. Oczywiście z zastrzeżeniem, że sam mam niezbyt długi staż na tej platformie i mogę się mylić. Tym samym, proszę bardziej doświadczonych użytkowników o ewentualne sprostowania i uzupełnienia. Jednocześnie mam nadzieję, że poniższy artykuł okaże się dla kogoś przydatny.
![]()
Gdzie zapisywane są treści?
Chciałbym dowiedzieć się jak działa blockchain steem i kto przechowuje te wszytkie dane. Czy cała treść artykółów jest przechowywane w blockchainie czy tylko odpowiadające artykułom hashe?
Cała treść artykułów, wszystkie komentarze, transakcje w tokenach Steem i SBD, operacje follow i unfollow, upvote'y, flagi i głosy na witnessów są zapisywane w blockchainie Steem. W przypadku edycji artykułów czy komentarzy, zapisywana jest wyłącznie różnica między oryginałem a nową wersją. To oznacza, co wielokrotnie podkreśla @noisy, że raz zapisana w blockchainie treść zostaje tam na zawsze (tak naprawdę do końca istnienia blockchaina Steem albo internetu, co jednak z naszego punktu widzenia oznacza zapewne na zawsze). Nawet usunięcie wpisu (możliwe tylko przez 7 pierwszych dni od publikacji) tak naprawdę oznacza tylko dany wpis jakimś tam znacznikiem, by nie był wyświetlany - w blockchainie zostanie i tak.
Jeszcze odpowiadając na pytanie "kto przechowuje te wszytkie dane" - to, że te dane są zapisane w blockchainie oznacza, że są na dysku każdego komputera (węzła) obsługującego sieć blockchaina Steem. Każdy taki węzeł posiada kopię całego łańcucha bloków czyli wszystkich danych, które kiedykolwiek zostały do niego zapisane.
Rozdzielanie wynagrodzenia kuratorskiego
Nie udało mi się jeszcze znaleźć indormacji w jaki sposób 25% kwoty jest rozdzielane pomiędzy głosujących.
Jest to mocno skomplikowane i czytałem o tym ostatnio post, którego oczywiście nie mogę teraz znaleźć (pomocy?). Nie jest to jednak podział po równo, w sensie jeśli ktoś zagłosował za 0,01$ a cały wpis uzyskał 1$ to ten ktoś dostanie dokładnie jedną setną tych 25%. Wpływ na podział ma po pierwsze SP głosujących, moc poszczególnych głosów, ale także czas głosowania. Głosujący z najwyższym SP i najwyższą mocą głosu dostaną najwięcej (są udziałowcami platformy o większym wkładzie więc więcej im się należy). Ale jeśli zagłosujesz dość wcześnie nawet niewielkim głosem na post, który potem stanie się bardzo popularny, masz szansę otrzymać wynagrodzenie nawet kilka razy wyższe niż Twój wkład w upvote'a. Przy czym przez pierwsze 30 minut po opublikowaniu posta, autor dostaje część z puli przeznaczonej dla kuratorów (ta odbierana część się liniowo zmniejsza - w tej samej sekundzie co czas publikacji to będzie 100%, w piętnastej minucie 50% a tuż przed upływem 30 minut już tylko mały ułamek). Dlatego nie wszyscy rzucają się na głosowanie w pierwszych sekundach po publikacji (w szczególności boty).
Jest narzędzie do szacowania wypłaty z głosu: https://steemcalculator.github.io/ ale wydaje się obecnie nie działać.
O kategoriach (tagach)
Przypisywanie do kategorii
Jak tagować
Ostrożnie. Za świadome publikowanie do popularnego taga niezwiązanego z treścią wpisu z nadzieją na wyższe upvote'y bardzo łatwo dostać flagę. Za nieświadome tagowanie złym tagiem również, ale jeśli się taga zmieni to najczęściej flaga jest zdejmowana. Trochę zależy od społeczności, która się skupiła wokół danego taga, niektóre są bardziej tolerancyjne, niektóre mniej.
Czy jesli np napiszę post po Polsku i dodam tag np PHP to czy nie zaśmiecę wątku PHP który jest anglojęzyczny?
Tak jak pisałem wcześniej - to zależy od społeczności wokół danej kategorii. To znaczy, raczej nie zauważyłem jawnego flagowania postów w innym języku niż angielski - co nie znaczy, że takie flagowanie nie miało miejsca, po prostu ja na takie nie trafiłem. Poza tym łatwo sobie wyobrazić sytuację, gdy wkrótce przy popularyzacji Steema, liczba postów w językach innych niż angielski może zacząć przekraczać liczbę tych w języku angielskim i wtedy, dzielenie kategorii według języka będzie wręcz wymuszane (flagowaniem). Ale jeśli zakładasz, że Twoimi odbiorcami mają być Polacy to może warto rozpocząć nową kategorię np. pl-php. Ja osobiście polecam oznaczanie kategorii, w których będzie się pisać wyłącznie po polsku przedrostkiem pl-. Takie kategorie dość łatwo się wyróżniają na listach kategorii, przy sortowaniu alfabetycznym są wszystkie koło siebie i w wielu miejscach gdzie można używać filtrów, biorą one pod uwagę tylko początek nazwy (gdy wpiszesz pl wyszukają kategorie zaczynające się od pl np. pl-php ale nie znajdą php-pl).
Dla jasności wspomnę, że według moich obserwacji istnieje jeszcze drugie podejście, gdzie nazwy kategorii, które są słowami występującymi wyłącznie w języku polskim nie wymagają dodatkowego oznaczenia (np. literkami pl). Przy takim podejściu jeśli chciałbyś pisać o PHP po polsku, musiałbyś użyć przedrostka pl- lub przyrostka -pl. Natomiast przy chęci pisania o sztuce produkowania mydła ( ;-] ) mógłbyś użyć po prostu samego słowa mydlo. Mnie się taki sposób nazewnictwa mniej podoba, przede wszystkim dlatego, że chcąc znaleźć podobne treści musiałbyś wiedzieć, że taka kategoria istnieje. Drugim problemem jest weryfikacja czy rzeczywiście dane słowo występuje wyłącznie w języku polskim (czy jest gdzieś słownik ze wszystkim słowami we wszystkich językach? - wątpię). Z obowiązkowym prefiksem pl- liczba kategorii do przeszukania będzie znacznie mniejsza (i łatwiej je będzie przefiltrować).
Wyszukiwanie w kategorii
jak przeszukiwać tagi
Mam wrażenie, że jakoś stosunkowo niedawno, API programistyczne do blockchaina Steem zostało zmienione w taki sposób, że ograniczono możliwość przeglądania wpisów w kategorii tylko do tych, które zostały utworzone mniej niż 7 dni temu. Bardzo mi się to nie podoba i nie rozumiem tego podejścia no ale cóż można zrobić (wiem, wiem - napisać własny interfejs, który będzie archiwizować linki wszystkich artykułów w kategorii ;-P ). Oczywiście jeśli znasz linka do danego wpisu to chyba na każdym interfejsie możesz go wyświetlić. Tylko jak taki link znaleźć?
Na szczęście masz odpowiednie narzędzie, mianowicie https://www.asksteem.com. To taka wyszukiwarka na blockchainie Steem. W polu wyszukiwania wpisujesz coś takiego:
(tags:polish) AND linux
...i potwierdzasz Enterem. Wyszuka wpisów z kategorii #polish ze słowem linux. Nie wiem jakimi kryteriami kieruje się ta wyszukiwarka przy sortowaniu wyników - pewnie trzeba by poszukać jakiejś informacji na ten temat.
Lista wszystkich kategorii
Czy jest gdzieś lista wszytkich tagów?
Nigdy czegoś takiego nie znalazłem. Ani narzędzia wyszukiwania wszystkich kategorii. Zakładam, że raczej nie ma. Niektórzy uważają, że pod tym linkiem: https://steemit.com/tags można znaleźć listę wszystkich tagów, ale tak nie jest. To krótka lista tych najbardziej popularnych. Bardzo łatwo jest dodawać nowe kategorie, część zapewne powstaje przypadkiem (literówki) i coraz więcej treści i tagów powstaje w językach innych niż angielski, więc pewnie z tego powodu nie ma sensu budować i utrzymywać listy wszystkich kategorii.
Ja znam trzy sposoby na sprawdzenie czy dana kategoria istnieje. Pierwszy to wpisanie w polu adresu przeglądarki następującego URL:
https://steemit.com/created/nazwa-kategorii
Jeśli istnieją jakieś wpisy w tej kategorii z ostatnich 7 dni to zostaną one wyświetlone (w związku ze zmianami w API o których pisałem wyżej). Jeśli nie istnieją takie świeże wpisy, dostaniemy komunikat, że wpisów w tej kategorii nie ma. Co jest bardzo słabe ponieważ nie wiadomo czy dlatego, że nigdy nie było wpisów w tej kategorii czy dlatego, że nie ma akurat żadnych świeżych.
Druga metoda to skorzystanie z prototypu aplikacji Strimi.it. Wchodzisz na ranking kategorii:
http://strimi.it/tags-ranking
gdzie wyświetlane są te najpopularniejsze. Ale gdy zaczniesz wpisywać coś w polu filtrowania, wszystko wskazuje na to, że wyszukuje ze wszystkich kategorii. Na liście wyników pojawiają się kategorie, które mają niezerową liczbę artykułów, ale po kliknięciu w taką kategorię - nic się nie wyświetla (nie ma świeżych wpisów).
Trzecia metoda to wspomniany wcześniej serwis https://www.asksteem.com. Gdy w pole wyszukiwania wpiszesz:
tags:"pl-linux"
powinien zwrócić wszystkie artykuły z tej kategorii. To moim zdaniem najlepsza opcja. Zwracam uwagę na cudzysłowy, chyba lepiej działa z cudzysłowami gdy w nazwie występuje myślnik.
Mam nadzieję, że pomogłem. Proszę o uwagi i komentarze. Pozdrawiam.
A kto może być węzłem steem?
Każdy może uruchomić własny node Steem-a, z technicznego punktu widzenia jest to serwer na którym działa aplikacja steemd. steemd "rozumie" blockchain, jest w stanie z niego pobierać dane i zapisywać. Węzły można podzielić na 3 główne grupy:
seed node to rodzaj węzła którego głównym zadaniem jest przechowywanie aktualnej wersji blockchain-a i udostępnianie danych wszystkim zainteresowanym, w praktyce wygląda to tak, że jeśli uruchomisz steemd to aplikacja połączy się do seed node-ów i z nich pobierze aktualne dane niezbędne do działania. Listę takich node-ów możesz zobaczyć na https://github.com/steemit/steem/blob/master/doc/seednodes.txt.
exchange / api node to również ta sama aplikacja steemd ale uruchomiona z dodatkowymi pluginami, dzięki temu możemy pobierać konkretne dane o postach, użytkownikach, tagach, transakcjach, itd. Komunikacja klienta z takim węzłem odbywa się poprzez interfejs RPC (json), przykładowy request zwracający informację o koncie wygląda tak,
$ curl --data '{"jsonrpc": "2.0", "method": "get_accounts", "params": [["jamzed"]], "id": 1 }' https://gtg.steem.house:8090/rpcListę publicznie dostępnych API node-ów możesz sprawdzić na https://geo.steem.pl/ (mała autoreklama) ;-)
witness node to też steemd ale uruchomiony z pluginem witness, pozwalącym "produkować" bloki. Steem opiera się o protokół DPOS (Delegated Proof of Stake), więc do poprawnego działania całej sieci potrzebni są delegaci którzy są wybierani poprzez głosowanie. Każdy może być witnessem (opublikować publiczny klucz typu signing), ale żeby realnie produkować bloki trzeba jeszcze uzyskać odpowiednią liczbę głosów i nie chodzi tu o ich ilość, ale o moc (ilość posiadanych VESTS przez głosującego). Witnessi oprócz produkcji bloków ustalają również cenę STEEM, wysokość opłaty za utworzenie nowego konta, posiadają również kilka mechanizmów dzięki którym są w stanie "sterować" wartością SBD który zawsze powinien być w okolicy ~1 USD.
No właśnie. W tej wiedzy o węzłach brakuje mi kilku klocków. Sporo już wyjaśniłeś, ale jeszcze jedno czy dwa pytania (no dobrze kilka pytań).
steemdgada tylko z innymisteemdi koniec?Natomiast:
oraz
oraz komentarz, na który właśnie odpowiadam - myślę, że świetnie Ci idzie. :-D
Jaka jest użyteczność czystego seed node'a (poza byciem częścią sieci) dla jego właściciela? Ma choć jedno jakieś API by można było sobie lokalnie odpytywać blockchaina? Czy też steemd gada tylko z innymi steemd i koniec?
Seed node głównie służy do wymiany danych pomiędzy węzłami i jest to bardzo ważna funkcja, ponieważ zapewnia stabilne działanie sieci u jej podstaw. Żaden steemd nie uruchomi się bez podłączenia do węzłów seed.
Ja do uruchomienia seed node-a użyłem gotowego obrazu Docker z repozytorium Steemit, gdzie dwa podstawowe API (database_api, login_api) są włączone, czyli funkcje tj. get_accounts, get_account_references, lookup_account_names, lookup_accounts, get_account_count, get_conversion_requests, get_account_history, get_owner_history, get_recovery_request, będą działać.
Czy też do tego celu (by mieć jakieś API) trzeba doinstalować któryś z pluginów?
Pluginy służą do rozszerzenia funkcjonalności steemd, np. dla węzła typu witness wymagany jest plugin witness (enable-plugin = witness), jeśli chcesz uruchomić funkcjonalność API, to oprócz pluginów musisz włączyć też funkcjonalnośc public api np. database_api, login_api, account_by_key_api, network_broadcast_api, tag_api, follow_api, market_history_api, raw_block_api.
Czy możesz wskazać jakieś źródło informacji co do tego jakie zasoby są potrzebny by sobie seed node'a uruchomić? Choćby lokalnie, dla własnych testów.
Wymagania są podane w repo (chociaż wydają się być już trochę nieaktualne...). steemd jest bardzo pamięciożerny ze względu na sposób w jaki przechowuje wewnętrzne dane, oprócz miejsca na dysku dla samego blockchain-a (48GB), potrzebujesz dużo pamięci (lub bardzo szybkiego dysku) na tzw. plik shared memory, który obecnie ma już rozmiar > 16GB na seed i witness node-ach, dla węzłów typu Full API jego rozmiar to nawet > 186GB i masz teraz dwie opcje, albo zapewnić tyle pamięci by plik zmieścił się cały, albo wykorzystać dysk twardy. Moje serwery posiadaja po 32GB pamieci, obecne zuzycie pamieci RSS wynosi ~23GB.
Dlaczego plik shared memory jest taki ważny? Ponieważ to w nim są przepisane dane z blockchain-a niezbędne do działania Twojego steemd (plik ten tworzy się podczas operacji replay blockchain), czyli mówiąc w skrócie przy pierwszym uruchomieniu steemd, kiedy następuje analiza całego blockchaina. Czas operacji replay i rozmiar pliku shared_memory zależy od ilości włączonych pluginów/api, może to trwać od kilku godzin do nawet kilkudziesięciu...
Czy ewentualnie doinstalowywanie pluginów zwiększa jakoś drastycznie te wymagania?
Tak, tak jak opisałem na powyższym przykładzie, węzeł witness lub seed wymaga obecnie >16GB pamięci (zakładając, że używamy tylko pamięci i nie chcemy wchodzić na SWAP), węzeł Full API (wszystkie API włączone), >186GB.
Gdybyś chciał pobawić się z API to polecam Ci używanie serwerów publicznie dostepnych, wiele usług się na nich opiera i nawet jeśli od czasu do czasu któryś jest niedostępny to można zawsze przepiąć się na inny ;-) Pozwoli Ci to zapoznać się z Steem a ominie Cię dużo problemów związanych z samym utrzymywaniem takiego hosta ;-)
Jak na razie tak właśnie robię :-). Tylko tak mi czasem jakieś głupie pomysły przychodzą, czy by tu nie zapuścić jakiegoś skryptu, żeby przeleciał cały blockchain... w tę i z powrotem. No ale na razie wybiłeś mi to z głowy :-).
Wielkie dzięki za tak wyczerpującą odpowiedź. Wreszcie mi się we łbie wszystko ułożyło (miałem większość kawałków, ale mi je jednym kopnięciem z półobrotu poukładałeś). :-D
Ciesze sie, ze choc troche moglem cos podpowiedziec ;-) ja bym sie nie stresowal tym, ze caly blockchain pobierzesz z jakiegos serwera ;-) kolejny ciekawy projekt to sbds czyli blockchain w bazie danych ;-) sa tez publiczne instancje, gdzie mozesz klientem MySQL sie polaczyc i wyciagac z blockchaina dane przy pomocy SQL-a ;-)
Bardzo dziękuje za obszerną odpowiedź.
W tym temacie braki w mojej wiedzy są na razie największe. Ale według mnie każdy. Każdy kto ma odpowiednio silną maszynę (nie musi to być od razu jakiś superkomputer, ale sporo RAMu i szybki dysk są chyba kluczowe) i szybkie łącze. I odpowiednią wiedzę, żeby skonfigurować odpowiednio maszynę, zainstalować i skonfigurować oprogramowanie.
Ale jeśli się pytasz czy musisz mieć od kogoś pozwolenie - to nie, nie musisz. I to jest właśnie najpiękniejsze w blockchainie. Decentralizacja sieci dotyczy także jej własności - nie ma jednego właściciela, który może wydawać pozwolenia albo zakazy. Każdy kto się do sieci przyłączy, jest jej współwłaścicielem.
Natomiast inna sprawa jest z witnessami (czyli jak tu niektórzy próbują popularyzować takie tłumaczenie na polski - z delegatami). To są Ci właściciele węzłów, którzy są wybierani spośród społeczności przez głosowanie na witnessa. Ich węzły, jeśli są odpowiednio niezawodne, a oni sami zdobyli zaufanie społeczności, mogą zatwierdzać kolejne bloki w łańcuchu i zarabiać na tym kasę. Z tego co wiem, mamy już jednego polskiego witnessa @gtg i drugiego pretendującego na to stanowisko: @jamzed. Zachęcam do zapoznania się z nimi i z tym co robią dla społeczności Steem i rozważenie oddania na nich głosów.
Dziękuję.
Szczerze dodam, że widząc ile dobrego dla społeczności robią @gtg i @noisy czuję się trochę nieswojo... wydawało mi się, że rola delegata to jedynie techniczne wyzwanie, ale z tygodnia na tydzień uświadamiam sobie, że tu nie chodzi tylko o serwery i konfigurację... to coś znacznie więcej... czego ja ze swoim introwertycznym charakterem muszę się nauczyć.
Myślę, że introwertyczny charakter nie musi Ci wcale przeszkadzać. O ile dobrze oceniam to co widzę, to dość technokratyczna społeczność, gdzie ceniona są zarówno wiedza i kompetencje jak i chęć współpracy i dzielenia się wiedzą.
Mam nadzieję, że delegaci nie zdobywają tu głosów przez rzucanie gładkich słówek i sprzedawanie sztucznych uśmiechów, czyli mówienie każdemu wyborcy tego co chce usłyszeć. Dość tego mamy w prasie i telewizji. A jeśli tak jest, to tym bardziej warto szukać takich delegatów, którym bliżej do technokraty niż do polityka.
dodałbym tylko, że zarówno zdjęcia i wszelkie video zapisywane w blockchainie nie są. Obecnie zapisywane są tylko linki do zdjęć/filmów.
Bardzo słuszna uwaga. :-) Dla mnie to coś dość oczywiste, ale niestety nie pomyślałem, że dla innych to wcale nie musi być oczywiste. Dzięki.
Bardzo dobry post. Długo zastanawiałem się jakiego formatu tagów używać i być może przejdę na proponowany "pl-tag". W przypadku polskich słów problem nie istnieje, np. "motoryzacja", ale może utrzymywanie jednej konwencji opłaci się na przyszłość. Jeśli nauczymy się wszyscy, że polskie tagi mają przedrostek "pl", to wszystkim będzie się żyło lepiej. Pytanie tylko, czy każdy się zastosuje do takiej konwencji? Może czas na polski portal oparty o steem, który będzie wyświetlał treści tylko spod tagu #polish i automatycznie dodawał prefiksy? ;)
To bardzo ciekawy pomysł. W zasadzie nie powinno to być takie trudne do zrobienia (chyba). Może wystarczy zrobić jakąś prostą modyfikację kodu condensera (czyli aplikacji na której chodzi steemit.com). Oczywiście, łatwo się pisze, ale...
Wystarczy, że zastosuje się większość. W takiej sytuacji jeśli ktoś będzie chciał dalej budować i rozwijać swoją własną kategorię, która się nie będzie wpisywać w ten schemat, to ma do tego oczywiście prawo ale będzie się musiał pogodzić z tym, że trudniej go znaleźć bo większość polskich użytkowników nie będzie się spodziewać polskich treści poza tagami z przedrostkiem
pl-.Na razie proponuję wpisywać #polish dla dla artykułów #pl-artykuly, potem się zobaczy :)
Aż chce się zadawać pytania czytając takie odpowiedzi. Wyjasniłeś wszystkie moje wątpliwości. Również Twoja dyskusja z @jamzed jest mocno pouczająca. W temacie wynagrodzenia kuratorskiego chciałbym dodać, że szukając odpowiedzi na pytanie znalazłem https://steemstats.com, gdzie można podejrzeć dane dotyczące wagi głosów. Z tego co rozumiem $ są przydzielane według Vote Weight, a ta zależy od tego co napisałeś, czyli SP oraz momentu w którym oddamy głos. Poniżej screen ze wspomnianej strony.
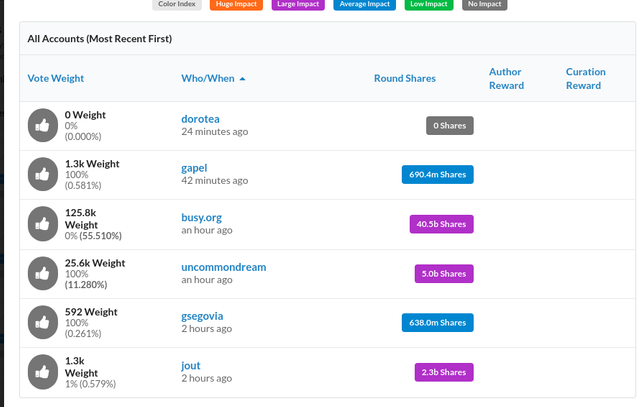
Czytając Twoją odpowiedz przyszło mi do glowy, że fajnie byłoby gdzieś zebrać tego typu cenne informacje. Moja propozycja to założenie repozytorium na githubie z plikiem readme. Coś w rodzaju https://github.com/bbatsov/rails-style-guide , gdzie każdy może zrobić wpis na zasadzie pull requesta.
Bardzo ciekawy pomysł. Pomyślę nad tym.
https://steemstats.com/ - dawno tam nie zaglądałem. Kiedyś strasznie ta strona muliła, coś się musiało zmienić bo dziś śmiga aż przyjemnie używać.
wiem, ze stary post, ale trafilam teraz i dziekuje.
bardzo pomocne informacje!
Bardzo dobry wpis, wszystko dobrze wyjaśnione.
Dzięki Tobie i ja znalazłem odpowiedzi na nurtujące mnie pytania :) Dzięki :)
Widzę, że nie tylko ja ubolewam nad tą dziwną zmianą co do 7 dni w widoku postów. Kiedyś dało się prześledzić historię i dosłownie policzyć wszystkie posty od początku istnienia taga. Teraz tak naprawdę tagi stają się bezużyteczne już po kilku godzinach od publikacji.
Trochę mi trudno sobie wyobrazić, żeby to była zmiana na stałe. Może to jakiś okres przejściowy i za chwilę pojawi się odpowiednia opcja. Jeśli nie, to bardzo nietrafiony pomysł. Na pewno powstaną narzędzia, które ułatwią takie prześledzenie starszych postów, no ale to już nie to samo, gdy trzeba korzystać z kolejnej zewnętrznej aplikacji do tak podstawowej potrzeby.
Utrudnione przeglądanie starych treści to wielka wada steemita
Congratulations! This post has been upvoted from the communal account, @minnowsupport, by alcik from the Minnow Support Project. It's a witness project run by aggroed, ausbitbank, teamsteem, theprophet0, someguy123, neoxian, followbtcnews/crimsonclad, and netuoso. The goal is to help Steemit grow by supporting Minnows and creating a social network. Please find us in the Peace, Abundance, and Liberty Network (PALnet) Discord Channel. It's a completely public and open space to all members of the Steemit community who voluntarily choose to be there.
If you would like to delegate to the Minnow Support Project you can do so by clicking on the following links: 50SP, 100SP, 250SP, 500SP, 1000SP, 5000SP. Be sure to leave at least 50SP undelegated on your account.
przydatne przydatne, dzieki.