So, You Want to Operate an OriginTrail Node?
Practice Makes Perfect
This is an axiomatic expression, but it's doubly true in the case of OriginTrail's testnet participation. While the OriginTrail team has consistently demonstrated a high level of professional and technical capability, the testnet deployment will have bugs. In fact, the known existence of bugs is entirely the motivation for the testnet. This is ubiquitously true for any software organization.
I am just reminding everyone that, without your participation in the testnet, 1.) you won't have had any prior experience before taking the leap and staking your tokens on the live mainnet (yikes!), 2.) the OriginTrail team will have to wait that much longer to identify and fix bugs, and 3.) the likelihood of overlooking/missing avoidable mistakes that may otherwise stay under the radar is increased.
There are simply too many unknowns at the moment to specify exactly which types of specifications will be required to run your node personally. Hobby nodes may be relatively limited in their capacity, while professional node operations may be profitable on the margins. In any case, it is conceivable to under-serve or over-serve your agreements from a computational and internet bandwidth capacity. It is my hope that, OriginTrail will have a statistical description concerning explicit node component requirements after testnet is complete.
Fine, You're Going to Run a Node During Testnet and Beyond. Now What?
If you're like me, even despite being somewhat 'experienced' in the crypto space, or with IT and/or programming generally, you may not get a really good feeling about how to actually make it happen. That's probably normal for most people. Let me first say that, I believe OriginTrail is fully aware that the node setup and operation needs to be practicable by a very wide range of people, many of whom may not have any associated experience whatsoever. As such, I fully suspect the team will be operating from that knowledge, and will follow up with tutorials and explanations in conjunction with delivering an intuitive user interface. It's quite possible OriginTrail may even dedicate a community channel to testnet onboarding support. We shall see.
However, there are some components of node setup that likely won't be covered, as they are not truly integral to OriginTrail's successful delivery of the testnet, and any team-originated recommendations concerning best practices regarding the node operators' choices would run the risk of explicit or implicit endorsement. Remember, one of the guiding principles of the OriginTrail project is decentralization. In the spirit of decentralization, hopefully there are myriad node setups supporting the OriginTrail Decentralized Network (ODN) (a.k.a. decentralization).
So, I figured I would take some time to share my thoughts on running a node, discuss some hardware and internet connection options, outline qualitative risks, put some perspective on different failure mechanisms, and bring up other sundry considerations.
Let's Start at the Top
The diagram below demonstrates the most basic explanation of what a node operator will be concerned with, from a setup perspective. The node operator is required to have:
- Hardware - A computer with sufficient computing power and memory capacity to hold and serve the ODN data.
- Internet Connection - A networking bridge to connect the hardware to the ODN
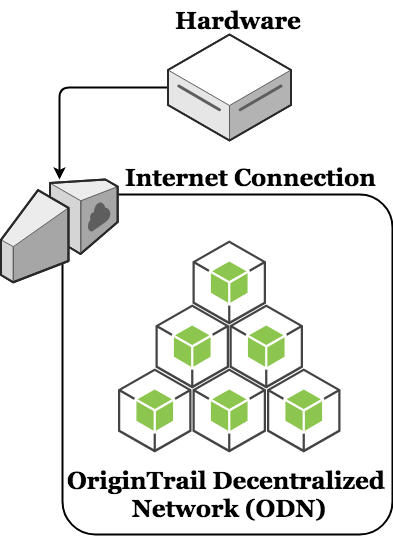
That's it.
The rest of this article will discuss the options associated with each of those two components, the initial and fixed costs associated, and the risks associated with running each.
Hardware
There are really only two flavors of hardware. There is hardware that you can purchase and own, and there is hardware that someone will rent to you (cloud). Refer to the diagram below for a pictorial explanation of your choices ('VPC' is Amazon's Virtual Private Cloud, which provides cloud compute and storage services).
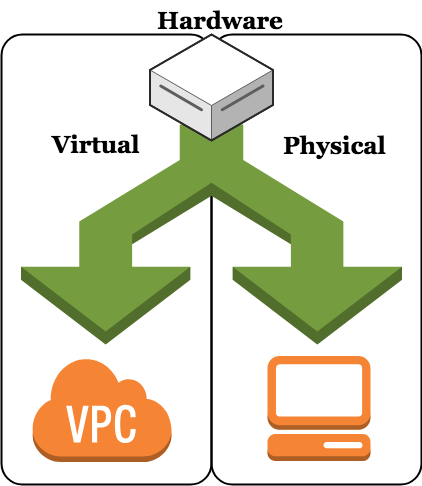
As there are various acceptable and interchangeable terms concerning how to define these hardware options, I have used the following scheme. 'Physical' refers to any equipment that is purchased, owned, and maintained by the node operator, like a desktop or a laptop. 'Virtual' refers to any cloud computing services vendors, whether direct or third-party, that offer hardware rentals.
- Physical - Desktops, laptops, Raspberry Pis, etc. .
- Virtual - Any of several cloud computing service options
So, basically, you can either buy your own computer, or you can rent one from a cloud computing services company.
Hardware Right-sizing
Play around with this to build your own idea. Testnet is your consequence-free (except any associated fees incurred as a result of cloud services or physical components purchase) opportunity to figure out what you need. Personally, I would lean toward a conservative approach for now. Run the node on your personal computer, or buy a baseline package from a cloud services provider. Through participation, node operators should be able to better define the requirements of meeting their node operation aspirations.
Internet Connection
The naming convention employed for hardware is precisely the same as the one used here.
Again, you can pay a local internet service provider, or you can use the cloud to provide the internet connection for you.
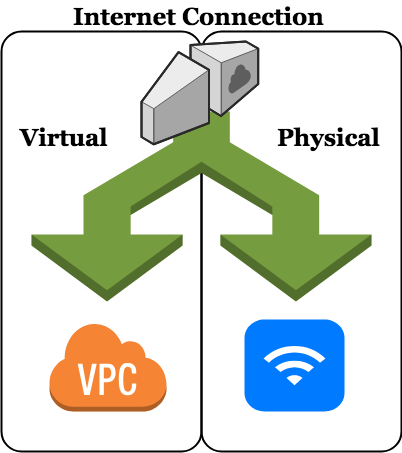
Internet Connection Right-sizing
Again, start with what you have already, or use the basic cloud service package. However, especially for Physical deployments, you should be mindful of what sort of up time your connection exhibits. This is important!
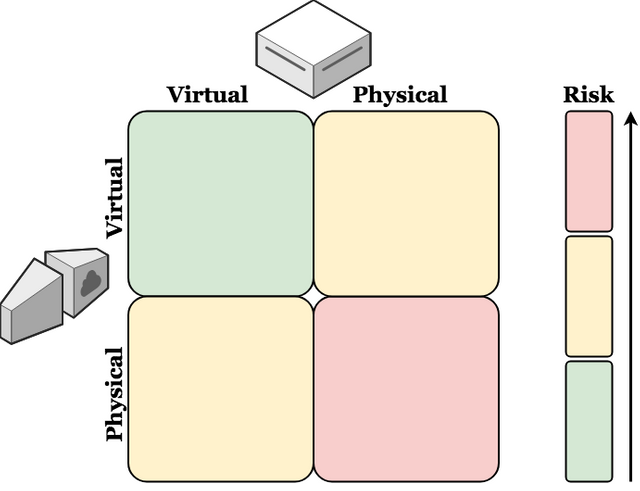
Risks
The risks associated with Physical deployment, for both hardware and internet connection, are greater than those associated with Virtual deployment. This is due to the fact that, your internet service may be spotty at times, you may experience a localized power outage, or your equipment may fail. In any case, it is very unlikely - without nearly immediate rectification - that you will be able to re-establish connection and continue to honor the agreements you are currently serving sufficiently well. Imagine having to order a new computer; we're talking hours, if not days, of down time.
Intermittent Cloud Computing Down Time
Cloud computing is not without down time. There are cases of entire region power failure, which resulted in multiple hours of continuous down time. However, these incidents are both exceedingly rare and avoidable with regionally-distributed redundancy methods.
The figure below demonstrates typical cloud service down times (not to scale). In general, if a failure is experienced, the failure is almost immediately rectified, when using cloud services. Very often, up times of 99.999% of the time are stated. The failures below represent the general down times that contribute to the 0.001% of the time down. Almost certainly these types of up times will meet the conditions in any agreement.
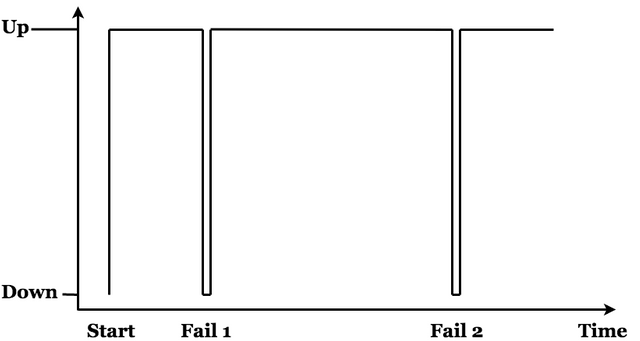
Sustained Down Time Associated with Physical Deployment Component Failure
If a component of a Physical deployment fails, it is likely going to manifest as sustained down time. As such, these types of failures are likely the most risk-imposing types of failures.
At one point, the original version of Token Demand Model exhibit a read-write frequency (Velocity) of 30 times per month per stakeholder. This, in effect, suggests the OriginTrail team expects that stakeholders will, on average, perform a read-write function once per day. So, even with 100 stakeholders checking daily, it is reasonable to assume read-write operations occurring at an average of 864 seconds. Let's just call it 15 minutes. Every 15 minutes, on average, someone will ping the data (per the model, which was a first-order approximation). This means, you may fail 4 calls, if you experience down time of an hour. At this point, I suspect you are getting into danger of losing stake (total guess!, but you get the point). The Figure below is to be understood relative to the previous figure for cloud services failures.
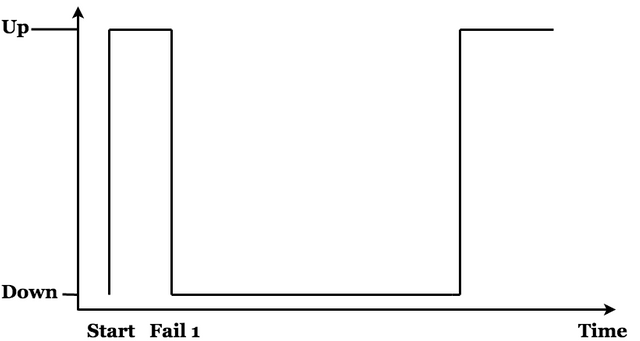
Final Word on Risk
For the average node operator, Physical deployments are likely to exhibit the greatest risk, while cloud services represent the least risk. In the coming weeks, if the community is interested, I will further detail regional redundancy methods to safeguard against even the most unlikely failure modes associated with cloud services.
Costs
In the long run, the costs associated with Physical deployment are likely to be less than Virtual deployment. Initially, however, Physical deployment will be more expensive, even if you bought the equipment you intend to use long ago.
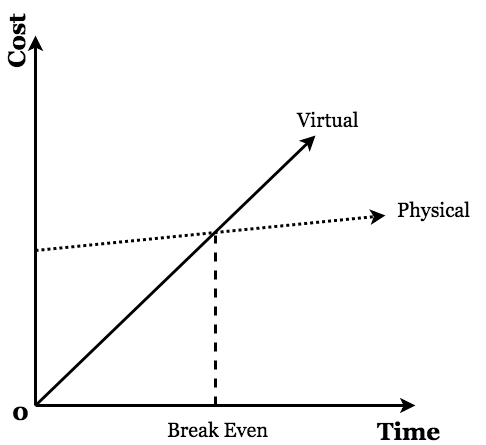
The y-intercept (initial cost for Physical deployment) will vary, as will the slopes (monthly costs) associated with both the Physical and Virtual deployments. Generally speaking, however, this type of analysis can be performed by those interested node operators. The takeaway is that, it is less expensive (pending device failure and/or loss of stake) to employ Physical deployments.
Some Options
Having gone over some of the considerations regarding purchasing a cloud computing service or operating a node on equipment you personally own and maintain, let's move into a more practical conversation. Let's go over which services are available to you.
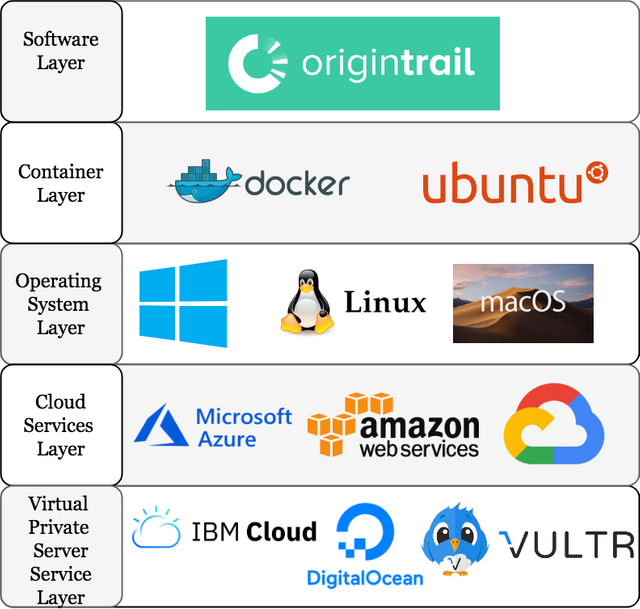
Software Layer
Node operators will be required to download the OriginTrail testnet software, after release. This is obvious, everyone knew this, moving on.
User Interface
While I do expect the user interface may evolve over time, you should expect to see something like the user interface shown below. Hopefully, for anyone intimidated by a command line interface, this will calm you some.
Container Layer
Containerized software packages refer to those packages that are entirely internally self-sufficient, independent of the operating system. Of course, the node operator must download and compile a package to run these containerized software packages, but don't worry. These are open source, readily-available, and currently supported all over the internet. This is likely how the OriginTrail software will be deployed, in a container. The reason I say this is that, Microsoft Windows, while not necessarily ideally-suited for bare bones application powering (like running a node), is the most familiar operating system for the majority of interested node operators.
Operating System Layer
The operating system layer is my first swipe at representing those operating systems that can support Docker containers. There may be others. I don't know. I am hopeful it doesn't matter beyond these.
Cloud Services Layer
The cloud services layer represents some of the cloud service providers available. There has been a lot of talk of Vultr and Digital Ocean in the OriginTrail community, and I understand why. However, the cloud services layer is not that type of service. Rather, these are places to spin up instances (run the software) on rented equipment. These options may be more cost-effective, if you know how to effectively use them. However, these options do require a bit more cloud computing savvy that Vultr and Digital Ocean, which are aimed at minimizing user knowledge.
Virtual Private Servers (VPS) Services Layer
This is likely the things you have heard about being viable candidates within the OriginTrail community (or others), and they are viable options. As I stated, these options may impose a bit more cost and exhibit less tailor-fitting, but they are intended to be simple and straight-forward. These are absolutely good choices for inexperienced users, though potentially more costly.
Last Thoughts on Options
As an exercise left to the reader, I recommend comparing prices and so on for any service of interest. The entities I have listed here do not represent all possibilities, but merely a handful I am familiar with.
Conclusion
I hope this is a conversation starter. I have tried to be as generic and inclusive as possible. However, I am prepared to dive as deep as you guys want to go. The main purpose was to make everyone feel comfortable running a node and asking the right questions to get up and running!
Folks, I hope you learned something here - at least enough to ask pointed questions. If you have questions, let's start a dialogue. I am here to answer questions, and will get to the bottom of any question, if I don't know it. I intend this to be a place where, in anticipation of testnet participation and into mainnet, anyone can get assistance on how to get their rig up and running. Seriously, take me up on this!
I suppose you are setting up one tomorrow? Would you please document the steps and make a new post like a quickstart guide?
Follow me on Steemit, or refer to the Origintrail Reddit. I am simply waiting for testnet release to produce documentation.
Upvote this: https://steemit.com/free/@bible.com/4qcr2i
Upvote this: https://steemit.com/free/@bible.com/4qcr2i# Upvote this: https://steemit.com/free/@bible.com/4qcr2i
OriginTrail's Mainnet will go live on December 7th and it is the perfect time to operate a node! Here's an informative video regarding about the OriginTrail!