오픈소스 작명 센스: 아파치 플룸(Apache Flume)
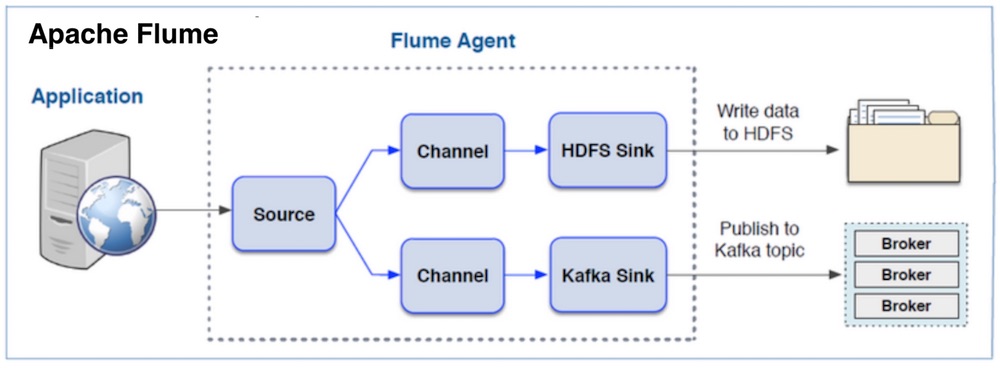
Flume에 대한 전체적인 개요를 정리한 문서입니다. Flume을 아직 잘 모르시는 분들에게 전체적인 Flume 이미지를 제공하는 목적으로 작성하였습니다.
Flume이란?
Apache Flume은 오픈소스 프로젝트로 개발된 로그 데이터를 수집 기술입니다. 여러 서버에서 생산된 대용량 로그 데이터를 효과적으로 수집하여, HDFS과 같은 원격 목적지에 데이터를 전송하는 기능을 제공합니다. 구조가 단순하고 유연하여 다양한 유형의 스트리밍 데이터 플로우(Streaming Data Flow) 아키텍처를 구성할 수 있습니다.
Apache Flume 프로젝트는 공식 홈페이지는 https://flume.apache.org/ 입니다.
로그 수집에 Flume을 사용함으로써 신뢰성, 규모 확장성 및 기능 확장성을 확보할 수 있습니다. Flume을 사용하면 장애시에도 수집된 로그 유실을 방지할 수 있으며, Scale-up/Scale-out 방식의 확장을 모두 지원합니다. 마지막으로 새로운 기능을 쉽게 커스터마이징 할 수 있습니다. Flume의 기본 구성은 <그림 1>과 같습니다.
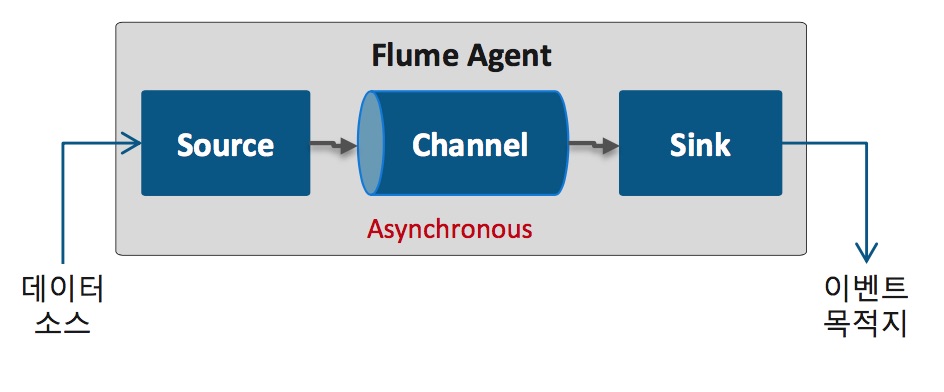
- 그림 1: Flume 구성
작명 끝판왕: Flume
오픈소스 프로젝트 이름에는 생각보다 많은 의미가 담겨 있습니다. 오픈소스 프로젝트 이름이 시스템 전체의 특징을 직관적으로 설명하기도 합니다. Flume이 이런 대표적인 사례입니다.
Flume이라는 단어의 본래 의미를 아시는 분은 거의 없으실 것 같습니다. 이 단어는 토목분야에서 사용되는 전문 용어입니다. Flume은 모르겠지만 "후룸라이드"는 대부분 아실 겁니다. 맞습니다. "후룸라이드"는 누구나 한 번쯤은 타봤을, 거의 모든 놀이 공원에 있는 대표적인 놀이 기구입니다.<그림 2 참조>
- 그림 2. 친숙한 놀이 기구: 후룸라이드
"후룸라이드"는 통나무를 운반하는 수로인 프룸에서 영감을 얻어 만든 놀이기구 입니다. Flume의 사전적 의미는 다음과 같습니다.
Flume: 토목용어, 수로 측벽과 밑판이 구조적으로 한 몸으로 되어 토압과 수압을 지지하는 형식의 일반적인 개수로. (출처: 네이버 토목 용어 사전)
후룸라이드를 알고 있다고 해도, Flume의 정의만으로 실제 모습을 상상하기는 어려울 것 같습니다. 그리고 "개방형수로(개수로)"가 왜 분산형 로그 수집 프로젝트의 이름이 되었는지 연관 짓기도 어려운 것 같습니다.
벌목 현장의 Flume
<그림 3>은 전통적인 통나무 벌목 현장입니다. 산에서 통나무를 벌목한 다음, 나무꾼이 통나무를 직접 산 아래로 들고 운반해야 한다면 정말 지옥일 겁니다. 그리고 굉장히 비효율적일 겁니다. 이러한 이유로 옛날에 통나무 벌목 현장에서는 통나무를 강으로 운반하는 특수한 형태의 수로를 만들어 사용했습니다. <그림 4>와 같이 벌목 현장에서 통나무를 산 아래로 운반하는 용도로 만든 개방형 수로가 플룸(Flume)입니다. 이 플룸을 놀이 공원에서 간단하게 만들어 사람이 탈 수 있도록 만든 것이 "후룸라이드"입니다.

- 그림 3. 통나무 벌목 현장, 사람이 직접 나무를 운반한다고?
벌목한 나무를 효율적으로 산 아래로 나르기 위해서 플룸이라는 반개방형 수로를 만들어 사용했습니다.<그림 4-A, B 참조>. 일반적으로 강을 둘러싸는 큰 산을 중심으로 여러 벌목장이 만들어지고, 각 벌목장은 벌목에 앞서 통나무를 강으로 운반할 플룸이 만듭니다. 그다음에 각 벌목장에서는 벌목한 통나무를 플룸에 태워 강으로 이동 시킵니다. Flume은 각 벌목장에서 자른 통나무는 강에 전달합니다. 강에 모든 벌목장의 통나무 모이게 됩니다. 강에 목제가 모이면, 배나 뗏목을 이용하여 통나무를 강 하구 목제 공장으로 운반합니다. <그림 4-C, D 참조>

- 그림 4. 플룸, 통나무 운반 수로
통나무가 영어로 뭘까요?
여기서 간단한 퀴즈를 내겠습니다. 통나무가 영어로 뭘까요?
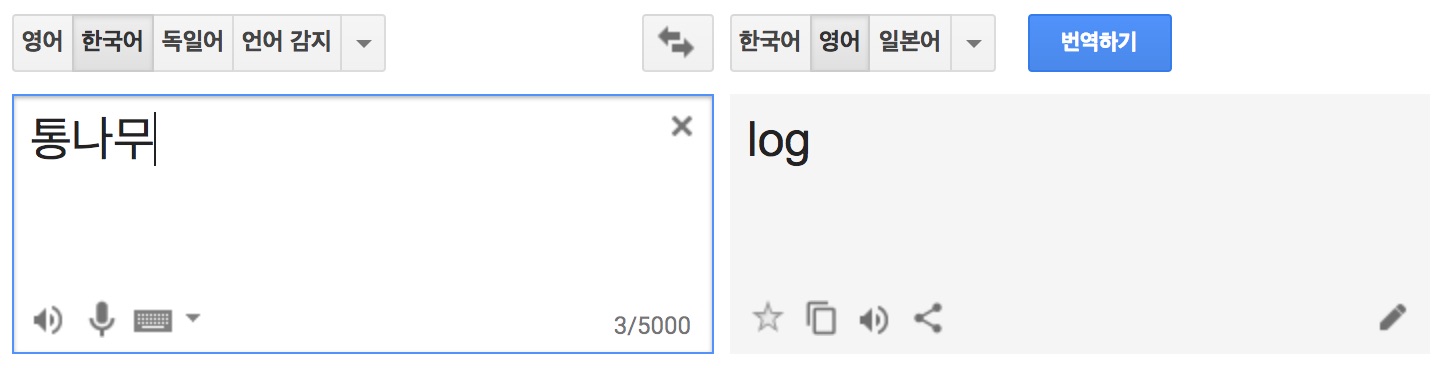
- 그림 5. 통나무, 영어로 log
통나무는 영어로 로그입니다. 따라서 벌목장의 플룸은 다음과 같이 표현할 수 있습니다.
산속 여러 벌목장에서 벌목한 "로그"(통나무)를 강으로 보내는 수로이다.
Apache Flume과 벌목장 플룸
Apache Flume은 로그(통나무)의 이중적인 의미에서 착안한 멋진 비유입니다. 통나무를 운반하는 수로의 이미지로 여러 서버로부터 로그를 수집하고 모으는 스트리밍 로그 수집기 기술을 설명하는, 딱 맞는 이름입니다.
Apache Flume과 벌목장 플룸을 다음과 같이 표현으로 설명할 수 있습니다.
| 기술적 표현 | 일상적 표현 | |
|---|---|---|
| 1 | Apache Flume이란 | 전통적인 벌목장의 플룸이란 |
| 2 | 여러 서버에 | 여러 벌목장에 |
| 3 | 설치되는 소프트웨어로 | 설치되는 통나무 운반용 수로(플룸)로 |
| 4 | 수집한 로그를 | 벌목한 통나무(로그)를 |
| 5 | 원격지의 Data Lake로 | 산 아래 강으로 |
| 6 | 전송하는 비동기 채널입니다. | 운반하는 수로입니다. |
- Apache Flume이란 여러 서버에 설치되는 소프트웨어로 수집한 로그를 원격지의 Data Lake로 전송하는 비동기 채널입니다.
- 전통적인 벌목장의 플룸이란 여러 벌목장에 설치되는 통나무 운반용 수로(플룸)로 벌목한 통나무(로그)를 산 아래 강으로 운반하는 수로입니다.
벌목장에서 나무를 운반하는 과정과 서버에서 로그를 수집하는 과정이 굉장히 유사합니다. 그리고 로그와 통나무가 같은 영어로 표현되기에 개념전달에 좋은 이름입니다.
벌목장의 플룸의 이미지로 부터 우리는 다음과 같은 Apache Flume의 기술적인 특징을 유추할 수 있습니다.
- 분산환경에서 로그를 모으는 소프트웨어다. (벌목장과 강이 멀리 떨어진..)
- 여러곳에 위치하는 로그를 한 곳으로 모을 수 있다.
- 로그를 배치로 한꺼번에 보내는 것이 아니라 스트리밍하게 지속적으로 보낸다.
- 비동기 방식으로 처리한다.
- 로그를 수집하는 역할과 로그를 전송하는 역할은 개별적으로 움직인다. (Source와 Sink는 개별적인 Thread임)
실제 이렇게 유추한 특징은 Apache Flume의 기술적 특성과 정확하게 일치합니다.
Apache Flume의 실체
Flume은 자바로 작성된 유연한 로그 수집하는 툴입니다. Flume은 <그림 6>과 같이 한 개의 자바 프로세스로 실행됩니다.
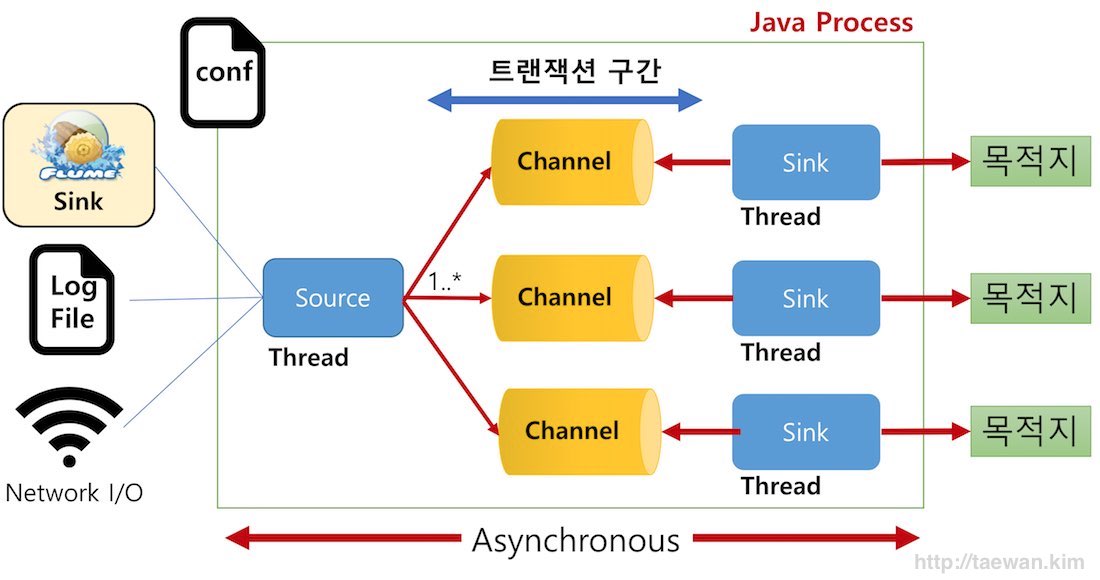
- 그림 6. Flume 구성요소 상세
Flum의 핵심 구성 요소는 Source, Channel, Sink입니다. Source와 Sink는 개별적인 쓰레드로 동작합니다. Flume 구성 요소는 다음과 같은 역할을 담당합니다.
- Source: 외부 이벤트가 생성되어 수집되는 영역
- 1개 구성, 복수 Channel 지정
- Channel: Source와 Sink 간의 버퍼 구간
- 채널 별로 1개 Sink 지정
- Sink: 수집된 로그/이벤트를 목적지에 전달
- Interceptor: 수집된 로그/이벤트 가공
Flume의 구성 요소는 다음과 같은 방식으로 동작합니다.
- 수집 대상 데이터(로그/이벤트) 생성
- 수집 대상 로그/이벤트를 Source에 수신
- Source는 수신한 메시지를 Channel에 전달
- Sink는 Channel로부터 메시지를 가져와서 목적지에 데이터 전달/저장
각 구성 요소는 다음 그림과 같이 다양한 구현 컴포넌트를 제공합니다. 일반적으로 별도의 추가 개발 없이 로그/이벤트 수집 환경을 구성할 수 있습니다.
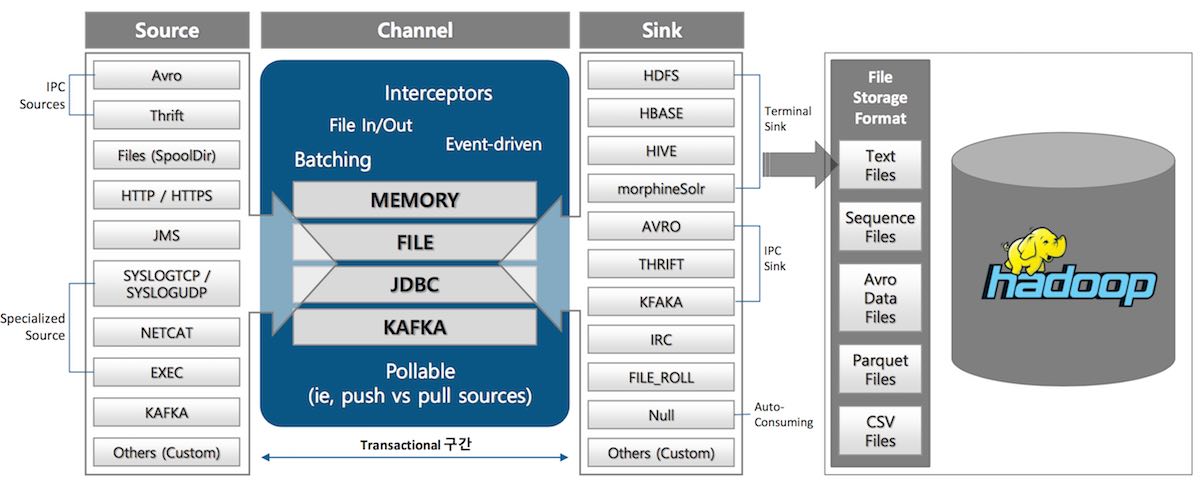
- 그림 7. Flume 구성 요소의 구현 컴포넌트
Flume 설치
Flume 설치 파일은 다음 URL에서 다운로드 할 수 있습니다. 2018.04 현재 최신버전은 1.8.0입니다. 설치 파일은 gz파일 형태로 배포됩니다.
- 그림 8. Flume 다운로드
설치는 압축 파일을 푸는 것으로 완료됩니다.
$ cd /usr/local/lib
$ sudo tar -zxvf apache-flume-1.8.0-bin.tar.gz
$ sudo mv apache-flume-1.8.0 flume
Flume 설치 디렉터리 /usr/local/lib/flume로 가정합니다. 이 디렉터리는 아래에서 {FLUME_HOME}으로 참조하겠습니다.
Flume 기본 설정과 실행 방법
Flume으로 서버로그를 Hadoop에 수집하는 예제를 소개합니다. Flume은 에이전트 노드와 컬렉트 노드에 설치되었음을 가정합니다.
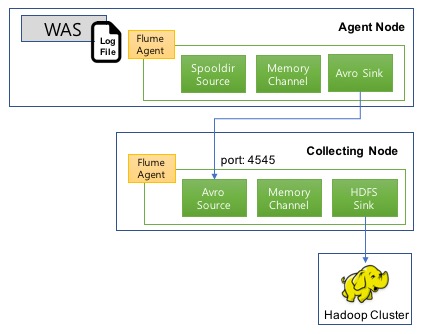
- 그림 9. Flume 설정 및 실행 예제
- Agent Node
- 로그가 발생하는 서버
- WAS 로그가 저장되는 디렉터리를 spooling 하여 로그 메모리 채널에 전송
- Avro Sink가 채널의 로그를 Collecting node로 전송
- port: 4545
- Collecting node
- Avro Source : Server A로부터 Avro통신을 통해 로그 수집하여 메모리 채널에 전달
- HDFS Sink : 수집된 이벤트를 HDFS에 저장
Agent 노드 Flume 설정 및 실행
로그를 수집하는 에이전트 노드에 다음과 같은 Flume 설정을 추가합니다. 파일명은 flume.conf입니다. 다음 예제는 /data/waslogs에 추가되는 로그 파일을 컬렉트 노드에 전송하는 설정입니다. 전송 포맷은 avro입니다.
이 설정 파일은 /usr/local/lib/flume/conf에 하는 것으로 가정합니다.
agentDataSource.sources = logsrc
agentDataSource.channels = logChannel
agentDataSource.sinks = avroSink
# Source : 지정된 디렉터리에 추가되는 파일 로그 전송, 전송후 파일명 변경
agentDataSource.sources.logsrc.type = spooldir
agentDataSource.sources.logsrc.channels = logChannel
agentDataSource.sources.logsrc.spoolDir = /data/waslogs
# Sink : Avro
agentDataSource.sinks.avroSink.type = avro
agentDataSource.sinks.avroSink.channel = logChannel
agentDataSource.sinks.avroSink.hostname = 142.3.3.1
agentDataSource.sinks.avroSink.port = 4545
# Channel : 메모리 채널
agentDataSource.channels.logChannel.type = memory
agentDataSource.channels.logChannel.capacity = 100
################################################
에이전트 노드의 flume은 다음과 같은 명령으로 실행됩니다.
cd /usr/local/lib/flume
./bin/flume-ng agent --conf-file ./conf/flume.conf --name agent01
Collecting 노드 Flume 설정 및 실행
다음은 컬렉트 노드의 flume 설정입니다. avro 포멧으로 유입되는 로그를 수집항 hadoop에 저장하는 구성입니다.
파일명은 flume.conf입니다. 이 설정 파일은 /usr/local/lib/flume/conf에 하는 것으로 가정합니다.
agentDataCollector.sources = targetSource
agentDataCollector.channels = targetChannel
agentDataCollector.sinks = targetSink
# Source : Avro
agentDataCollector.sources.targetSource.type = avro
agentDataCollector.sources.targetSource.channels = targetChannel
agentDataCollector.sources.targetSource.bind = 142.3.3.1
agentDataCollector.sources.targetSource.port = 4545
# Sink : HDFS
agentDataCollector.sinks.targetSink.type = hdfs
agentDataCollector.sinks.targetSink.channel = memoryChannel
agentDataCollector.sinks.targetSink.hdfs.path = hdfs://142.3.3.5:9000/data/stats/%Y-%m-%d/%H
agentDataCollector.sinks.targetSink.hdfs.fileType = DataStream
agentDataCollector.sinks.targetSink.writeFormat = Text
agentDataCollector.sinks.targetSink.hdfs.filePrefix = access_log
agentDataCollector.sinks.targetSink.hdfs.fileSuffix = .log
agentDataCollector.sinks.targetSink.hdfs.threadsPoolSize = 10
agentDataCollector.sinks.targetSink.hdfs.rollInterval = 30
agentDataCollector.sinks.targetSink.hdfs.round = false
local_agent.sinks.localHdfsSink.hdfs.roundValue = 5
local_agent.sinks.localHdfsSink.hdfs.roundUnit = minute
# Channel : Memory
agentDataCollector.channels.targetChannel.type = memory
agentDataCollector.channels.targetChannel.capacity = 100
에이전트 노드의 flume은 다음과 같은 명령으로 실행됩니다.
cd /usr/local/lib/flume
./bin/flume-ng agent --conf-file ./conf/flume.conf --name agent02
Flume의 유연한 구성 그리고 Kafka 결합
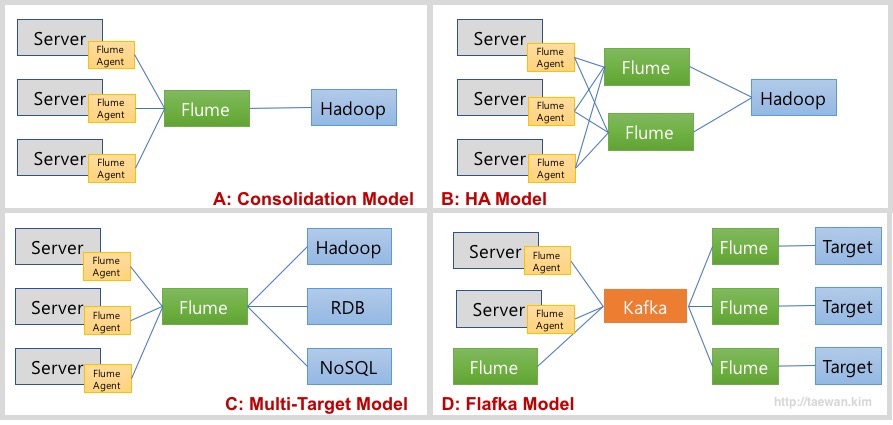
<그림 7>에서 확인할 수 있는 것처럼 Flume은 다양한 Source와 Sink 타입을 제공합니다. 이런 구현체를 이용하여 다양한 형태의 Data Flow를 디자인할 수 있습니다. <그림 10>은 일반적인 Flume 데이터 흐름 모델입니다.
- 그림 10. Flume 데이터 흐름 모델
<그림 8>의 각 모델을 정리하면 다음과 같습니다.
- A 모델: Consolidation Model
- 여러 서버로부터 로그를 통합하여 수집하고 저장하는 모델
- 각 서버에 Flume Agent가 설치되어 로그를 통합 Flume에 저장
- 통합 Flume은 지정된 목적지에 저장
- B 모델: HA 모델
- A 모델에서 통합 Flume 장애의 SPOF(단일 장애 포인트)에 대한 보완
- 고가용성을 위해서 통합 Flume을 이중화
- C 모델: Multi-Target Model
- A 모델으 목적지를 복수로 지정
- D 모델: Flafka Model
- Flume이 Kafka의 Producer와 Consumer 역할 수행
- 통합 Flume을 Kafka로 대체하여 고가용성 및 확장성, 유연성을 확보
- Flume을 이용하여 Kafka 개발 요소 제거
Flume의 가장 큰 취약점은 데이터의 안정성입니다. Flume은 Channel로 메모리와 파일 그리고 JDBC를 제공합니다. 메모리 타입은 처리 성능은 좋지만, Flume 장애 발생 시 데이터가 유실의 문제가 있습니다. 반면 파일 타입을 사용하면 데이터 안정성은 향상되지만, 성능이 크게 떨어집니다. 그리고 고가용성 모드로 관리하기 어렵다는 것입니다. 이러한 문제는 Flume과 Kafka를 결합함으로써 해결할 수 있습니다. 최근에 로그/이벤트 수집 환경을 구성 시 Flume만으로 구성하는 경우는 거의 없습니다. <그림 10-D>와 같이 Flafka Model을 사용합니다.
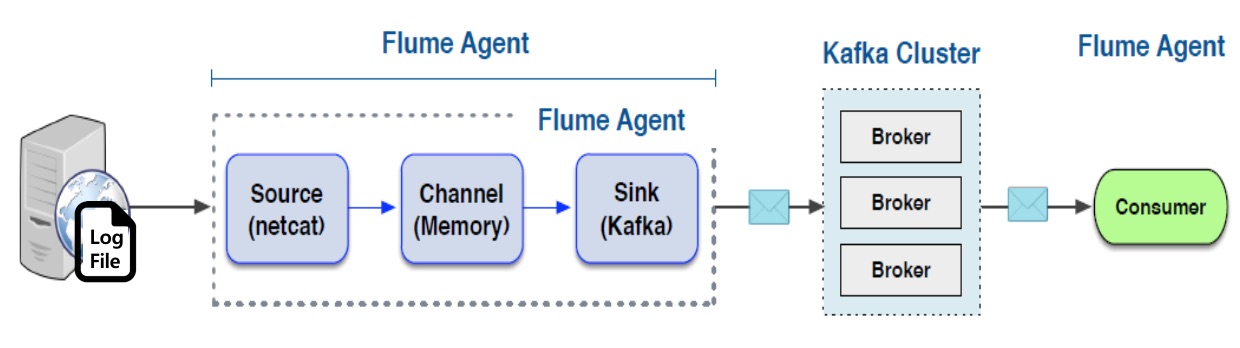
- 그림 11. Flafka = Flume + Kafka
Flume의 장점은 다양한 소스와 목적지에 대한 컴포넌트가 이미 구현되어 있다는 것입니다. 일반적으로 Flume 설치 및 설정만으로 작업을 완료할 수 있습니다. (물론 기능 확장 가능합니다.) Flume의 단점은 데이터를 저장하는 부분에서 장애가 발생할 경우, 데이터 유실의 가능성이 있고 확장 구성이 복잡하다는 것입니다. Kafka의 장점은 저장된 데이터를 안전하게 관리할 수 있고, 구성이 간단하고 확장성이 좋다는 것입니다. Kafka의 단점은 데이터 수집기(producer)와 데이터 처리기(Consumer)를 대부분 사용자가 구현해야 한다는 것입니다.
이 구 컴포넌트를 함께 사용하면 각자의 취약점을 보완하고 강점을 부각할 수 있습니다. Kafka의 확장성과 관리 편의성 그리고 데이터 안정성을 확보하면서, Flume 컴포넌트 구성을 통해서 사용 편의성을 높일 수 있습니다.
Flume 모니터링
Flume을 모니터링하는 방법은 기본적으로 3가지가 있습니다.
- Ganglia
- JMX
- JSON Reporting
flume 실행 시 -Dflume.monitoring.type=ganglia 옵션을 추가하여 Ganglia에서 모니터링이 가능합니다.
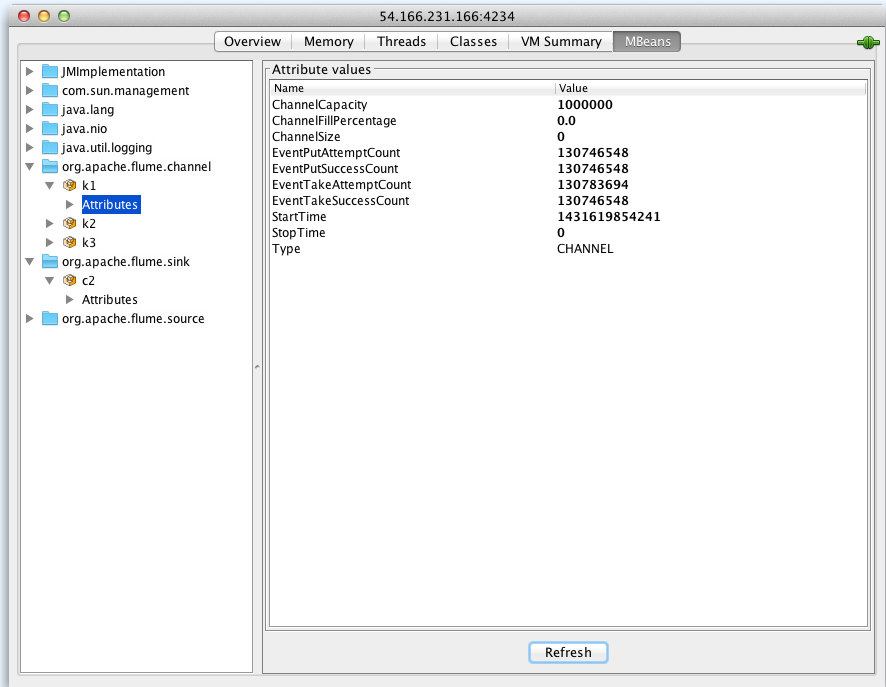
flume은 자바로 개발되어 있기에 JMX로 모니터링 가능합니다. JMX로 모니터링하기 위해서는 환경 변수로 다음과 같은 JAVA_OPTS 옵션을 추가하는 방법을 추천합니다.
export JAVA_OPTS=”-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=5445 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false”
JMX 사용시 <그림 12>과 같은 형태로 Flume 상태를 모니터링할 수 있습니다.
- 그림 12. JMX 모니터링 UI
Flume은 JSON 리포팅 기능을 제공합니다. 이 기능을 상용하기 위해서는
flume 실행 시 -Dflume.monitoring.type=http 옵션을 추가하여 Ganglia에서 모니터링이 가능합니다.
리포팅 기본 포트는 41414이며 변경 가능합니다. http://<모니터링 대상 Flum IP>:41414/metrics 호출하면 아래와 같은 정보가 출력됩니다.
{
"SINK.avroSink":{
"BatchCompleteCount":"133",
"ConnectionFailedCount":"0",
"EventDrainAttemptCount":"13300",
"ConnectionCreatedCount":"1",
"Type":"SINK",
"BatchEmptyCount":"0",
"ConnectionClosedCount":"0",
"EventDrainSuccessCount":"13300",
"StopTime":"0",
"StartTime":"1398215901251",
"BatchUnderflowCount":"0"
},
"SOURCE.otvSource":{
"OpenConnectionCount":"0",
"Type":"SOURCE",
"AppendBatchAcceptedCount":"133",
"AppendBatchReceivedCount":"133",
"EventAcceptedCount":"13300",
"AppendReceivedCount":"0",
"StopTime":"0",
"StartTime":"1398215901332",
"EventReceivedCount":"13300",
"AppendAcceptedCount":"0"
},
"CHANNEL.otvChannel":{
"EventPutSuccessCount":"13300",
"ChannelFillPercentage":"0.0",
"Type":"CHANNEL",
"EventPutAttemptCount":"13300",
"ChannelSize":"0",
"StopTime":"0",
"StartTime":"1398215901247",
"EventTakeSuccessCount":"13300",
"ChannelCapacity":"100",
"EventTakeAttemptCount":"13301"
}
}
원본
본 원서의 원본은 다음과 같습니다.
Will you follow me? 😊 @a-0-0
작명 센스 진짜 쩌네요. 통나무(log)를 모으는 플륨(flume)이라니...^^