2-5 퍼셉트론 개념에 입각한 훈민정음 자음(“+1”) 모음(“-1”) 구별 TensorFlow Softmax 예제
퍼셉트론 코딩에 대한 글을 연재하면서 여러 번 적절한 예제가 있느냐 없느냐는 점을 찾아 보았다. 비록 간단 하지만 조도센서 1개 짜리 N=1, 조도센서 2개 짜리 N=2 에 대한 실현 가능한 예제를 제시했으며 결론적으로 Rosenblatt의 목적이 지금의 MNIST 문자 인식과 대동소이하다는 점을 지적하곤 했다.
아울러 Anderson 교수와 함께 Iris 데이터를 수집하여 분석한 Fisher 교수 또한 마찬가지이다. 단 이들의 분석은 문자 인식과는 달리 통계학적인 클러스트링(clustering)분석으로 보는 것이 좋을 듯하다. 기본적으로 iris 데이터 세트는 4가지 파라메터를 측정하여 구성하는데 (x, y) 평면상에 점을 찍어 작도해 볼 수는 없지만 상상 속에서 점을 찍고 몇 개의 그룹으로 나누어 분류가 가능할 것이다. 이는 문자 인식과는 다른 분야로 볼 수 있다.
한편 퍼셉트론 책을 쓴 민스키 교수와 페파트 교수 조차도 퍼셉트론의 가장 중요한 역할인 머신 러닝에 의한 이미지 인식 문제 자체에 대한 지적 얘기는 전혀 없는 듯하다. 앞으로도 퍼셉트론의 머신 러닝에 대한 글을 올리겠지만 가장 중요한 것은 현실세계에서 만들어 보여 줄 수 있는 예제 즉 문자인식이라든지 아니면 클러스터링 문제가 있느냐 없느냐의 문제일 것이다. 적절히 설명할 수 있는 예제가 없다면 그것은 쳐다 볼 필요가 없으며 시간 낭비일 듯하다.
Rosenblatt의 퍼셉트론을 설명함에 적절한 예제 부족난을 조금이라도 해결하기 위해서 훈민정음 자음 모음을 구별하는 문제를 생각해 보자. 훈민정음의 자음과 모음을 대상으로 비트맵 데이타를 만들고 자음에 대해서는 라벨 값 +1을 모음에 대해서는 라벨 값 –1을 부여하기로 한다. 즉 퍼셉트론에 자음과 모음의 픽셀 이미지 여러 개를 보여 주고 학습을 시킨 후 퍼셉트론에 물어 볼 테스트 예제를 준비하도록 하자.
Rosenblatt 퍼셉트론 논의에서 아직까지 cost 함수 문제와 웨이트 업데이트 알고리듬이 완전히 이해가 된 것은 아니므로 이 부분에 대한 Solver로서 언제나 강력한 도구로 쓸 수 있는 Softmax 와 Cross Entropy를 사용해서 문제를 풀도록 하자. 즉 Rosenblatt 의 개념이 잘 맞는지 확인을 해보는 정도로 해두자.
훈민정음의 4개의 자음 “ㄱ”, “ㄴ”, “ㄷ”, “ㅁ” 과 5개의 모음 “ㅏ”, “ㅣ”, “ㅡ”, “ㅗ”, “ㅜ”에 대한 이미지 구성은 3X3 매트릭스로 가능하다. 더욱 많은 자음과 모음을 분류(calssification)하려면 적어도 5X5 또는 그 이상으로 해상도를 높여야 할 것이다.
지난번에 작성했던 자음 데이터를 바탕으로 하는 x_data는 그대로 이용 가능하다. 모음 데이터는 추가로 생성하기로 한다.
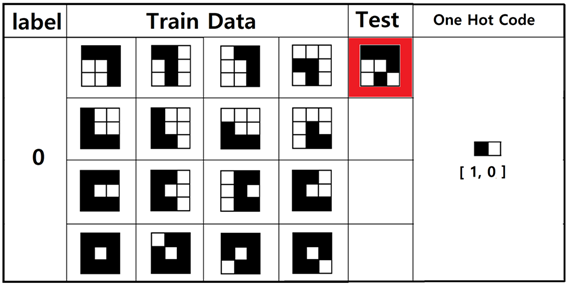
첫 번째 “ㄱ”에 대한 입력 데이터를 작성해 보자.
검은색은 0 흰색은 1로 코딩한다.
“ㄱ”⟶ [ 0, 0, 0, 1, 1, 0, 1, 1, 0 ],
[ 0, 0, 1, 1, 0, 1, 1, 0, 1 ].
[ 1, 0, 0, 1, 1, 0, 1, 1, 0 ],
[ 1, 1, 1, 0, 0, 1, 1, 0, 1 ]
“ㄴ“⟶ [ 0, 1, 1, 0, 1, 1, 0, 0, 0 ],
[ 0, 1, 1, 0, 1, 1, 0, 0, 1 ],
[ 1, 1, 1, 0, 1, 1, 0, 0, 0 ],
[ 1, 1, 1, 1, 0, 1, 1, 0, 0 ]
“ㄷ”⟶ [ 0, 0, 0, 0, 1, 1, 0, 0, 0 ],
[ 0, 0, 1, 0, 1, 1, 0, 0, 1 ],
[ 1, 0, 0, 1, 0, 1, 1, 0, 0 ],
[ 0, 0, 1, 0, 1, 1, 0, 0, 0 ]
“ㅁ”⟶ [ 0, 0, 0, 0, 1, 0, 0, 0, 0 ],
[ 1, 0, 0, 0, 1, 0, 0, 0, 0 ],
[ 0, 0, 0, 0, 1, 0, 1, 0, 0 ],
[ 0, 0, 0, 0, 1, 0, 0, 0, 1 ]
이 데이터들은 TensorFlow 코드에서 x_data로 입력하고 one hot code는 y_data로 입력한다.
자음 데이터에 추가하여 모음 데이터를 만들어 보도록 하자.
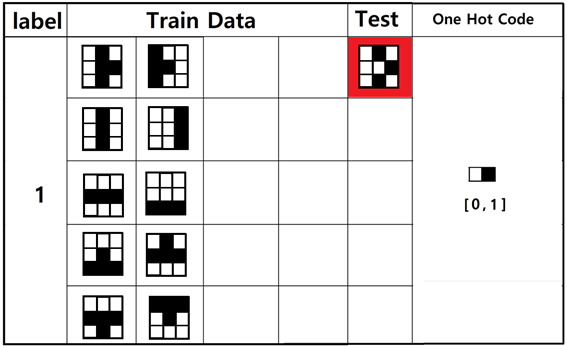
첫 번째 “ㅏ”에 대한 입력 데이터를 작성해 보자.
검은색은 0 흰색은 1로 코딩한다.
“ㅏ”⟶ [ 1, 0, 1, 1, 0, 0, 1, 0, 1 ],
[ 0, 1, 1, 0, 0, 1, 0, 1, 1 ].
“ㅣ“⟶ [ 1, 0, 1, 1, 0, 1, 1, 0, 1 ],
[ 1, 1, 0, 1, 1, 0, 1, 1, 0 ],
“ㅡ”⟶ [ 1, 1, 1, 0, 0, 0, 1, 1, 1 ],
[ 1, 1, 1, 1, 1, 1, 0, 0, 0 ],
“ㅗ”⟶ [ 1, 1, 1, 1, 0, 1, 0, 0, 0 ],
[ 1, 0, 1, 0, 0, 0, 1, 1, 1 ],
“ㅜ”⟶ [ 1, 1, 1, 0, 0, 0, 1, 0, 1 ],
[ 0, 0, 0, 1, 0, 1, 1, 1, 1 ]
Session에서 사용할 마지막 컬럼의 Test 용 데이터를 2개 코딩 한다. 하나는 자음 후보이고 또 다른 하나는 모음 후보이다.
“ㄱ”⟶ [ 0, 0, 0, 1, 1, 0, 1, 0, 1 ]
“ㅏ”⟶ [ 1, 0, 1, 1, 0, 0, 1, 0, 1 ]
X의 샘플수는 자음과 모음 합해서 9개이지만 None으로 하고 각 샘플의 데이터 수는 9 이다.
one hot code를 저장하는 Y는 샘플수에 해당하는 9개이지만 None으로 두고 각각의 one hot code 데이터 수는 2 이다.
클라스의 수는 라벨의 수에 해당하는 2이다.
웨이트 W는 X의 데이타수 9와 클라스의 수 2에 맞춰 배열을 선언한다.
바이아스 b는 클라스의 수 2로 두자.
다음의 결과는 테스트용 데이터에 대한 softmax 명령에 의한 계산 결과로서 one hot code의 1 위치에 대응하는 지점의 가장 확률값이 높은 hypothesis 값을 보여준다. 그 뒤의 브라켓 속의 값을 살펴보면 학습결과에 맞춰 정확히 인식했음을 알 수 있다.

주의할 점은 iteration 횟수가 지나치게 적으면 softmax 확률분포에 의해 계산한 hypothesis의 값이 줄어 들 수 있다. iteration 횟수 8000회 일 때에는 이 확률 값이 거의 99%에 달한다.
이 예제를 통해서 과연 퍼셉트론이 어떻게 응용될 수 있는지 이해 증진에 도움이 되었으면 한다.
아래의 코드를 복사해서 실행할 경우 혹 indentation 이 잘못되어 에러가 검출되면 2018년 8월 10일의 indentation 위치 AS 내용을 참조하기 바란다.
#softmax_classifier_9data_hunmin_Rosenblatt_01.py
from matplotlib import pyplot as plt
import numpy as np
import tensorflow as tf
tf.set_random_seed(777) # for reproducibility
def gen_image(arr):
t_d = np.reshape(arr, (3, 3))
two_d = (np.reshape(arr, (3, 3)) * 255).astype(np.uint8)
print(two_d)
plt.imshow(two_d, interpolation='nearest')
plt.savefig('batch.png')
return plt
x_data = [[ 0, 0, 0, 1, 1, 0, 1, 1, 0 ],
[ 0, 0, 1, 1, 0, 1, 1, 0, 1 ],
[ 1, 0, 0, 1, 1, 0, 1, 1, 0 ],
[ 1, 1, 1, 0, 0, 1, 1, 0, 1 ],
[ 0, 1, 1, 0, 1, 1, 0, 0, 0 ],
[ 0, 1, 1, 0, 1, 1, 0, 0, 1 ],
[ 1, 1, 1, 0, 1, 1, 0, 0, 0 ],
[ 1, 1, 1, 1, 0, 1, 1, 0, 0 ],
[ 0, 0, 0, 0, 1, 1, 0, 0, 0 ],
[ 0, 0, 1, 0, 1, 1, 0, 0, 1 ],
[ 1, 0, 0, 1, 0, 1, 1, 0, 0 ],
[ 0, 0, 1, 0, 1, 1, 0, 0, 0 ],
[ 0, 0, 0, 0, 1, 0, 0, 0, 0 ],
[ 1, 0, 0, 0, 1, 0, 0, 0, 0 ],
[ 0, 0, 0, 0, 1, 0, 1, 0, 0 ],
[ 0, 0, 0, 0, 1, 0, 0, 0, 1 ],
[ 1, 0, 1, 1, 0, 0, 1, 0, 1 ],
[ 0, 1, 1, 0, 0, 1, 0, 1, 1 ],
[ 1, 0, 1, 1, 0, 1, 1, 0, 1 ],
[ 1, 1, 0, 1, 1, 0, 1, 1, 0 ],
[ 1, 1, 1, 0, 0, 0, 1, 1, 1 ],
[ 1, 1, 1, 1, 1, 1, 0, 0, 0 ],
[ 1, 1, 1, 1, 0, 1, 0, 0, 0 ],
[ 1, 0, 1, 0, 0, 0, 1, 1, 1 ],
[ 1, 1, 1, 0, 0, 0, 1, 0, 1 ],
[ 0, 0, 0, 1, 0, 1, 1, 1, 1 ]
]
y_data = [ [1, 0], [1, 0],[1, 0], [1, 0],[1, 0], [1, 0],[1, 0], [1, 0],
[1, 0], [1, 0],[1, 0], [1, 0],[1, 0], [1, 0],[1, 0], [1, 0],
[0, 1], [0, 1],[0, 1], [0, 1],[0, 1], [0, 1],[0, 1], [0, 1],
[0, 1], [0, 1]
]
X = tf.placeholder("float", [None, 9])
Y = tf.placeholder("float", [None, 2])
nb_classes = 2
W = tf.Variable(tf.random_normal([9, nb_classes]), name='weight')
b = tf.Variable(tf.random_normal([nb_classes]), name='bias')
#tf.nn.softmax computes softmax activations
#softmax = exp(logits) / reduce_sum(exp(logits), dim)
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
#Cross entropy cost/loss
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
#Launch graph
with tf.Session() as sess:
for idx in range(16):
output = x_data[idx]
gen_image(output).show()
sess.run(tf.global_variables_initializer())
for step in range(8001):
sess.run(optimizer, feed_dict={X: x_data, Y: y_data})
if step % 20 == 0:
print(step, sess.run(cost, feed_dict={X: x_data, Y: y_data}))
print('--------------')
#Testing & One-hot encoding
a = sess.run(hypothesis, feed_dict={X: [[ 0, 0, 0, 1, 1, 0, 1, 0, 1 ]]})
print(a, sess.run(tf.argmax(a, 1)))
print('--------------')
bb = sess.run(hypothesis, feed_dict={X: [[ 1, 0, 1, 1, 0, 0, 1, 0, 1 ]]})
print(bb, sess.run(tf.argmax(bb, 1)))
print('--------------')
all = sess.run(hypothesis, feed_dict={
X: [[ 0, 0, 0, 1, 1, 0, 1, 0, 1 ],[ 1, 0, 1, 1, 0, 0, 1, 0, 1 ]]})
print(all, sess.run(tf.argmax(all, 1)))
Congratulations @codingart! You have completed the following achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
간만에 콜라보래이션
[골든티켓x짱짱맨x weee] 18차 현타토끼 이모티콘 증정 !
https://steemit.com/goldenticket/@goldenticket/x-x-weee-18
참여하세요!