1-7 3종류 이상의 데이터 처리를 위한 Muticlass logistic regression 알고리듬
Logistic regression 하면 항상 “0”과 “1”의 2가지 라벨 처리 문제를 다루지만 보다 일반화하여 3가지 이상의 데이터를 처리하는 logistic regression 기법이 있으며 이름하여 Multiclass logistic regression 이라한다. 보통 3가지 이상의 데이터들을 분류하려면 Softmax 기법을 생각하지만 Multiclass 에 대해서도 2종류의 라벨만을 처리할 수 있는 logistic regression기법 확장이 가능하다.
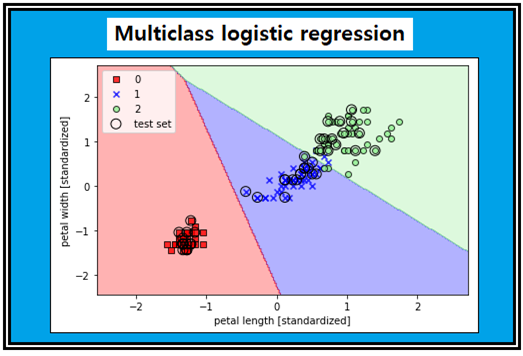
머신 러닝 입문한지 거의 2년이 되었지만 이런 기법이 있다는 사실을 전혀 모르고 있었는데 Python Machine Learning을 공부하다 보니 자연스럽게 의문이 제기되었다. 이 책 3장 초입부에서 2가지 라벨 처리문제를 logistic regression 기법으로 다룬 후 나오는 71페이지의 “Training a logistic regression model with scilit-learn”장에서 Iris flowers data set 3종류를 class Logistic regression() 루틴으로 처리한 작도 결과를 보여 주고 있다. 글을 읽어 보면 저자들도 그 자세한 내용은 모르는 듯하며 단지 예제 문제를 푼 결과와 중요한 점만을 설명할 따름이다.
머신 러닝을 배워가는 입장에서 다양하게 여러 가지 기법들을 알게 되었지만 3개 이상의 라벨문제를 Logistic regression 으로 처리한다는 사실은 필자에게는 서프라이즈(Surprize)로 느껴졌다. 아무래도 Softmax에 관해서는 통계역학적인 발상부터 검토를 해보았지만 머신 러닝에 이런 내용이 있다는 사실이 믿기지 않았지만 한편으로는 과연 Softmax와는 어떤 차이점이 있을까하는 강한 호기심이 느껴지는 부분이다.
정식화(Formulation) 내용이 많이 어렵게 느껴지지만 간단하게 짚어 보고 넘어가도록 하자.

퍼셉트론이나 Adaline class 루틴을 실행하게 되면 맨 처음에는 random 하게 설정된 웨이트 벡터 값들로부터 시작이 될 것이며 “+”든 “-” 든 스칼라 값이 계산되며 Logistic regression 함수를 사용하여 함수 g(z) 이 계산된다. 그 값이 0.5 이상이면 라벨 값 “1”을 부여하고 0.5 미만이면 라벨 값 “0”을 부여하는 것이 Logistic regression 의 핵심이다.
하지만 Iris flowers data set만 해도 setosa, versicolor 및 virginica 3종류의 데이터를 가진다. 즉 라벨 값이 “0”, “1”, “2” 가 되어야 한다.
샘플 데이터가 특정 라벨 값을 가지게 될 확률
전체 샘플 수 N =150인 일련의 Iris flowers data set 벡터 X를 고려해보자. X는 4개의 변수로 표현이 가능하다. 즉 꽃잎(petal)의 길이와 폭, 꽃받침(sepal)의 길이와 폭 데이터로 구성이 된다는 점이다. 150개 샘플로 구성되는 전체 X 벡터 중에서 그 중 하나의 i번째 샘플을

Logistic regression을 위한 Pivoting
logistic regression 은 2개의 라벨 값을 다루기에 적합한 머신 러닝 기법이므로 Iris flowers 데이터처럼 3개의 라벨 값을 가지는 경우에 하나의 라벨 값을 가지는 데이터를 Pivoting 하도록 하자. Pivoting 이라 함은 하나를 선정 후 나머지 중에서 하나씩 대응시켜 1:1 문제로 귀착시킨다는 의미이다. 즉 Iris flowers 데이터에서 Pivot 데이터를 하나 정하면 나머지 2종류의 데이터를 대상으로 하나씩 Pivot 과 매치시켜 2회에 걸쳐 각각 독립적으로 Logistic regression을 한다는 의미이다.
K개의 라벨 값 중 K 값을 가지는 경우를 Pivot 으로 설정하고 라벨 값이 1∼(K-1)까지 중에서 하나씩 대상으로 선정해 매치시키는데 이들 간의 확률 값의 자연로그 값을 취하여 linear predictor function f(k,i)로 두자. 이미 Logistic regression에서 Cross Entropy 설정 시에 확률 함수의 로그 값을 취하는 사례를 참조하자.

이 마지막 공식은 Logistic regression 과 유사하지만 웨이팅 벡터가 아닌 귀납적이면서도 경험적인 값으로 볼 수 있는 (MAP:maximum a posteriori probability)로 대체되어 있음에 유의하자. 그 결정 과정은 regularization기법 적용을 통해서 이루어지지만 결국 퍼셉트론이나 경사하강법에서의 웨이트 업데이팅 기법과 유사한 과정을 통해서 계산이 가능할 것이다.
이 알고리듬을 바탕으로 커버 그림의 결과를 얻을 수 있는 class LogisticRegression() 사용 예제를 살펴보기로 하자.
짱짱맨 호출에 응답하여 보팅하였습니다.
Congratulations @codingart! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @steemitboard: