[재배학 해설] 위대한 한 걸음, 인간 게놈프로젝트(human genome project)-3. 게놈 모자이크
완성 된 인간 게놈은 모자이크이므로, 어떤 개인도 대표하지 않는다. 출처: 위키백과
인간 게놈 프로젝트는 누구의 게놈을 사용했을까?
자연스러운 궁금증입니다. 나와 성별도 다르고 인종도 다른 호모 사피엔스 사피엔스 중 하나의 게놈으로 염기서열을 밝혔다면, 나와 다른 형질일텐데, 인간을 대표할 수 있을까? 그래서 조금 더 생각해 보겠습니다.
의학이나 생리학에서 다루는 생명체의 작동 메커니즘을 보면 개개인의 특성과는 상관 없이 공통된 부분이 있습니다. 생명현상에 작용하는 효소나 우리 몸을 구성하는 단백질의 성분과 구성은 같습니다. 우리 몸을 구성하는 레고블록은 다른 사람과 다를바 없습니다. 따라서 개인마다 유전자가 발현되는 정도의 차이에 따라 형질이 결정될 뿐, 해당 효소나 구조단백질의 모양 즉, 각 단백질을 구성하는 아미노산의 배열은 동일합니다. 당연히 각 단백질을 구성하는 mRNA나 DNA의 염기서열 또한 같다고 볼 수 있습니다. 따라서 어떤 개인의 게놈을 이용한다 하더라도, 아니면 여러 사람의 게놈을 이용하여 분석한다 하더라도 게놈지도에서는 큰 차이가 나지 않을 것임을 유추할 수 있습니다. 인간의 염색체 모양은 모두 동일하다는게 힌트입니다.
녹말을 분해하는 효소 어떻게 생겼을까?
Alpha-amylase 1 is an enzyme that in humans is encoded by the AMY1A gene. This gene is found in many organisms, see Alpha-Amylase. 출처: https://en.wikipedia.org/wiki/AMY1A
'알파 아밀레이즈 1'은 녹말을 분해하는 효소인데, 인간의 침샘에서 나옵니다. 이 효소의 설계도는 AMY1A 유전자입니다.
출처: 위키백과
'알파 아밀레이즈 1' 효소입니다.
알파 아밀레이즈 1의 아미노산 서열
1 mklfwllfti gfcwaqyssn tqqgrtsivh lfewrwvdia lecerylapk gfggvqvspp
61 nenvaihnpf rpwweryqpv syklctrsgn edefrnmvtr cnnvgvriyv davinhmcgn
121 avsagtsstc gsyfnpgsrd fpavpysgwd fndgkcktgs gdienyndat qvrdcrlsgl
181 ldlalgkdyv rskiaeymnh lidigvagfr idaskhmwpg dikaildklh nlnsnwfpeg
241 skpfiyqevi dlggepikss dyfgngrvte fkygaklgtv irkwngekms ylknwgegwg
301 fmpsdralvf vdnhdnqrgh gaggasiltf wdarlykmav gfmlahpygf trvmssyrwp
361 ryfengkdvn dwvgppndng vtkevtinpd ttcgndwvce hrwrqirnmv nfrnvvdgqp
421 ftnwydngsn qvafgrgnrg fivfnnddwt fsltlqtglp agtycdvisg dkingnctgi
481 kiyvsddgka hfsisnsaed pfiaihaesk l
알파 아밀레이즈 1의 아미노산 순서입니다. 알파벳 1글자가 1개의 아미노산을 뜻합니다.
참고: 아미노산의 기호
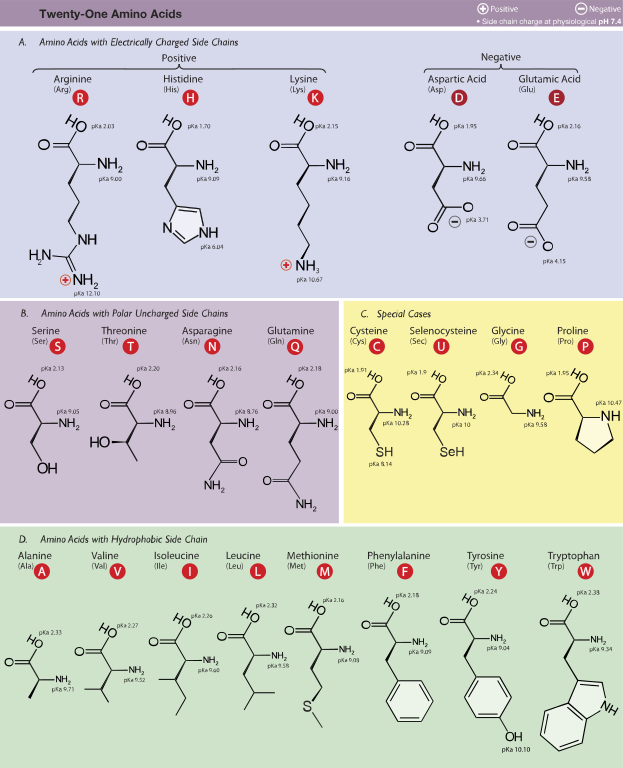
출처: 위키백과
한 글자의 알파벳으로 표시합니다. 붉은색 동그라미 안의 알파벳이 해당 아미노산에 대한 기호입니다.
알파 아밀레이즈 1을 암호화하고 있는 유전자는 어디에 있을까?

출처: 위키백과
이 효소의 정보를 암호화하고 있는 유전자 AMY1A gene은 인간의 1번 염색체에 있습니다.
1번 염색체의 103,655,290 bp(base pare, 염기쌍, 유전자 길이의 단위)에서 시작하여 103,664,554 bp까지 이어집니다.
AMY1A 유전자의 염기서열(sequence)
1 tggcttggtg agtctgtgtg gtcagcagtc tctgatccgt gcagggtatt aatgtgtcag
61 ggctgagtgt tctgagattt atctagaggc tgggaagggc tcctgaacca gttgtttccg
121 tcttgtcggt ctgtcagggt tggaaagtcc aagccatagg acccagtttc ctttcttagc
181 ttacgttatc taccagagca ccgtgggctg ttacttgcct tgagttggaa gcggttcgca
241 tttataccgg aatataaata gtttctggaa aggacactga caacttcaaa gcaaaatgaa
301 gctcttttgg ttgcttttca ccattgggtt ctgctgggct cagtattcct caaatacaca
361 acaaggacga acatctattg ttcatctgtt tgaatggcga tgggttgata ttgctcttga
421 atgtgagcga tatttagctc ccaagggatt tggaggggtt caggtctctc caccaaatga
481 aaatgttgcc attcacaacc ctttcagacc ttggtgggaa agataccaac cagttagcta
541 taaattatgc acaagatctg gaaatgaaga tgaatttaga aacatggtga ctagatgcaa
601 caatgttggg gttcgtattt atgtggatgc tgtaattaat catatgtgtg gtaatgctgt
661 gagtgcagga acaagcagta cctgtggaag ttacttcaac cctggaagta gggactttcc
721 agcagtccca tattctggat gggattttaa tgatggtaaa tgtaaaactg gaagtggaga
781 tatcgagaac tataatgatg ctactcaggt cagagattgt cgtctgtctg gtcttctcga
841 tcttgcactg gggaaggatt atgtgcgttc taagattgcc gaatatatga accatctcat
901 tgacattggt gttgcagggt tcagaattga tgcttccaag cacatgtggc ctggagacat
961 aaaggcaatt ttggacaaac tgcataatct aaacagtaac tggttcccgg aaggtagtaa
1021 acctttcatt taccaggagg taattgatct gggtggtgag ccaattaaaa gcagtgacta
1081 ctttggtaat ggccgggtga cagaattcaa gtatggtgca aaactcggca cagttattcg
1141 caagtggaat ggagagaaga tgtcttactt aaagaactgg ggagaaggtt ggggtttcat
1201 gccttctgac agagcgcttg tctttgtgga taaccatgac aatcaacgag gacatggcgc
1261 tggaggagcc tctatactta ccttctggga tgctaggctg tacaaaatgg cagttggatt
1321 tatgcttgct catccttatg gatttacacg agtaatgtca agctaccgtt ggccaagata
1381 ttttgaaaat ggaaaagatg ttaatgattg ggttgggcca ccaaatgata atggagtaac
1441 taaagaagtt actattaatc cagacactac ttgtggcaat gactgggtct gtgaacatcg
1501 atggcgccaa ataaggaaca tggttaattt ccgcaatgta gtggatggcc agccttttac
1561 aaactggtat gataatggga gcaaccaagt ggcttttggg agaggaaaca gaggattcat
1621 tgttttcaac aatgatgact ggacattttc tttaactttg caaactggtc ttcctgctgg
1681 cacatactgt gatgtcattt ctggagataa aattaatggc aactgcacag gcattaaaat
1741 ctacgtttct gatgatggca aagctcattt ttctattagt aactctgctg aagatccatt
1801 tattgcaatt catgctgaat ctaaattgta aaatttaaaa ttaaatgcaa atccgcaaag
1861 ca
AMY1A 유전자의 염기서열(sequence)은 이렇게 생겼습니다.
인간 게놈 모자이크
위 사례에서 보듯이 인간이 이용하는 효소나 구조단백질의 아미노산 배열은 같기때문에, 누구의 게놈을 이용하든 인간이 평생동안 만드는 효소와 단백질에 대한 정보가 빠지지 않으리란 것은 알 수 있습니다. 다만 아프리카 사람들의 말라리아 내성 유전자 같은 것들은 지역에 따라 가지고 있을 수도 있고, 없는 곳도 있습니다. 하지만 기본적인 생명을 유지하는데 필요한 단백질에 대한 정보는 인간 게놈 모자이크 안에 다 들어있을 것입니다.
간단하게 인간 게놈프로젝트에 대한 내용을 마무리지을까 합니다. 우리나라가 처음부터 참여하지 못했던 안타까움이나, 중간에 셀레라 지노믹스가 획기적인 DNA 시퀀싱 기술과 자금력으로 프로젝트를 앞질러 끝내버린 일, 게놈지도는 완성되고 십수년이 지나도록 획기적인 연구결과가 나오지 않는 등의 이야기는 재배학 해설이 아닌 다른 기회가 닿을 때 포스팅하겠습니다.
사실 게놈의 염기서열 중 많은 부분은 단백질에 대한 정보가 들어있지 않습니다. 단백질을 만들려고 DNA 일부를 복사하여 mRNA를 만들 때, 일단 순서대로 복사한 DNA 사본의 중간 중간을 잘라서 버릴 부분은 버리고 이어붙여 가공하여 mRNA가 만들어집니다. 자세한 내용은 다음시간을 기약하겠습니다.
향문사 재배학을 해설하고 있습니다. 80P에 해당하는 내용입니다.
새로운 한주 화이팅!!!
가즈아!
감사합니다!!
항상 흥미롭게 보고 있습니다. 감사드립니다 :)
관심 가져주셔서 정말 감사합니다. 글이 댓글 달기 애매한 면이 있는 것 같아 아쉬운 마음이 많이 드는데, 귀중한 댓글 고맙습니다^^
4월1일 밤늦게 스파가 회수되어 지금에서야 다시 임대해 드렸어요. 미숙하게 운영한것 죄송합니다. 일주일간 사용하세요.
아, 회수 신청을 하면 일주일 후에 들어오는 것인가봅니다. 스팀은 정말 많은것을 고려하여 만든 정교한 시스템인것 같습니다. 시스템 자체에 대해 공부하고 배워야 하는게, 파도 파도 더 나오는 느낌입니다.
덕분에 일주일 잘 쉬었습니다^^. 미안한 마음 안가지셔도 됩니다. 일주일간 잘 사용하겠습니다!!
FOLLOW⇆BACK⇉@a-0-0