How to do bad statistics, and how NOT to do it, Part II (DaVinci)
Two weeks ago, I've wrote the post to explain why it's fundamentally wrong to use Average as relevant parameter.
It's about 20-25 "screens" long, everything is explained in details, link.
Surprisingly, I need to explain it even further.
Grab some coffee, it will be a long post. Again.
Data were taken from the Official Utopian Review Sheet
Date: 14. Feb - 21. Feb 2019
Number of translations: 25, not perfect for everything but more than enough to prove the point
How the scores are given?
The official Questionnaire consists of 6 questions:
- Accuracy
- Number of Mistakes
- How consistent the translation is
- Quality of post itself
- Legibility of translated text
- Number of translated words
What is the distribution of ranks for each category?
This is very much expected, strong grouping around the recommended score "Very Good"
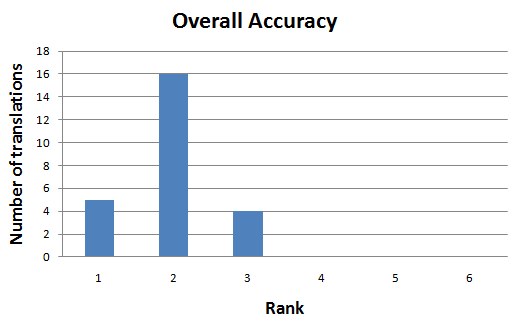
This is the catch that I already explained in my previous post. Distribution can't be normal distribution when you have "the wall" on one side, in this case: No Errors and 1 Error. Teams GER, ITA and ESP had 3 translations (in total) with the Ranks 3 or 4.

How consistent the translations were? One may think that there are two questions, but this is a classical case of underlying factors. Accuracy is correlated with Errors and with Consistency. Very intuitive, just as tall people have long legs and arms as well.
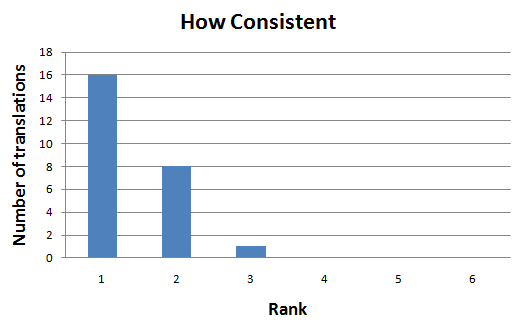
Of course, no surprise for Legibility. It's also correlated
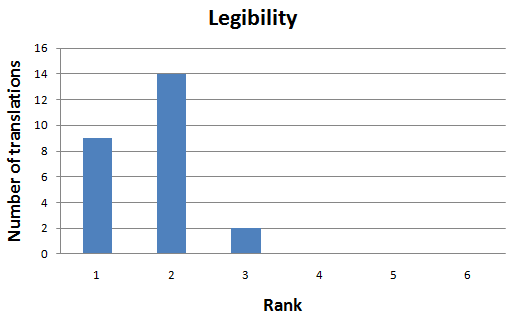
As you can see, we have 4 questions related to "quality" in our questionnaire. In reality, it's a single question.
The only post that was not almost perfectly correlated, was this post. Everything was excellent - but there were 6 mistakes (Rank 4).
Rank 3 or 4 in the Error Category usually means Rank 2 or 3 in Accuracy. I guess there were only typos in this post.
Maybe we should change something concerning the typos @imcesca , @silviu93?
I personally don't like this system where everything is a mistake, and maybe this case is the perfect example how to lose a lot of points for no real reason.
Quality of post is telling us something interesting: there are two grouping points: Very Good and Sufficient.
Sufficient was only given by the teams: Dutch and Serbia
@alexs1320 , @scienceangel , @misslasvegas , @altrosa - maybe we are too harsh to our teams?
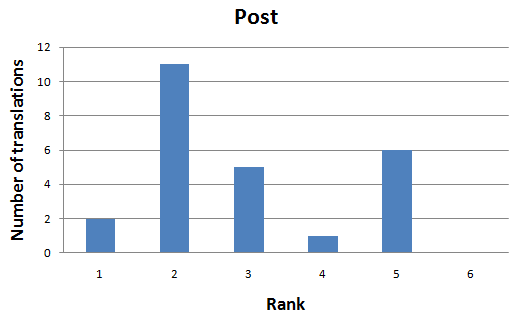
Word Count, only Serbian team is occasionally translating 2000+ due to Cyrillic/Latin translations - nothing unusual here.
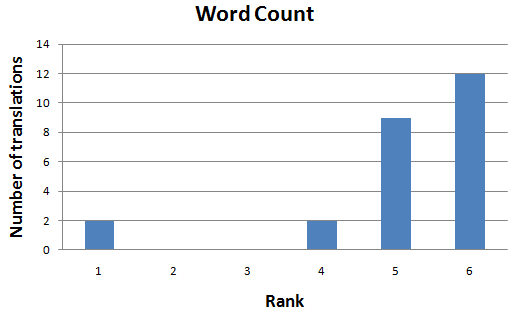
Short conclusion, there is nothing wrong with Ranks (not Points, Ranks)
Ranks vs Points
The system of translating Ranks into the Points is a bit odd:
- 0 negative point for Rank 1 (Excellent)
- a lot of negative points for Ranks 2-3
This is how 25 scores look like when we calculate the sum of all 4 "quality parameters":
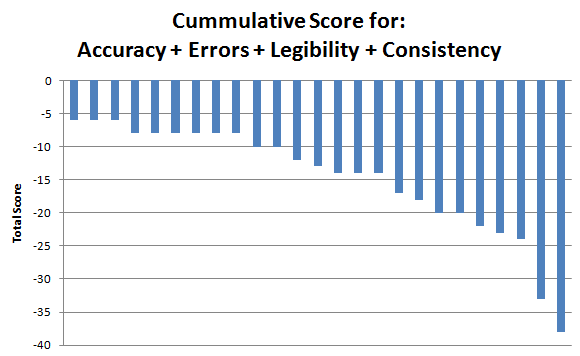
Pay attention! This is not a histogram, this is a bar plot!
I know it's a bit stupid to make a histogram with only 25 cases, but anyway...
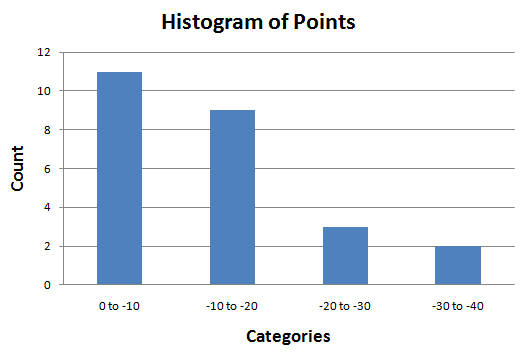
There is "a wall" on the left side of distribution for several questions, this is the result that was expected:
The lowest 5 scores were given in: Spanish Team (2x, different translations, different moderators), Italian, German and Arabic.
How word count is distorting the reality
Besides the average score is irrelevant, without the normalization to the word count - it's double irrelevant.
Here is why:
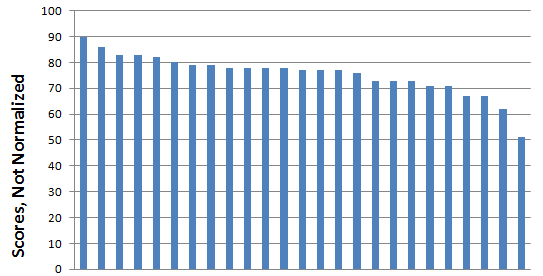
And the same scores normalized to 2000+ words:
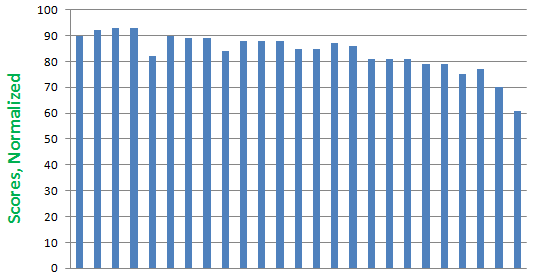
Why is this important? Because the differences become smaller, of course:
- Not-Normalized: Average 75.6 , Deviation 8.0 , Median 77.0
- Normalized: Average 83.7 , Deviation 7.5 , Median 85.0
*I know it's wrong to do Average and Deviation, but people like those two parameters for some reason
(Not)Surprisingly, everything is fine once the points are normalized.
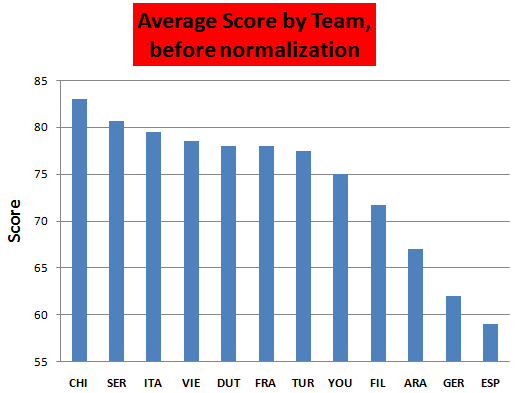
Let's do average scores for teams (*there are at least 3 reasons why this is pointless, but anyway, it's a norm to do it)
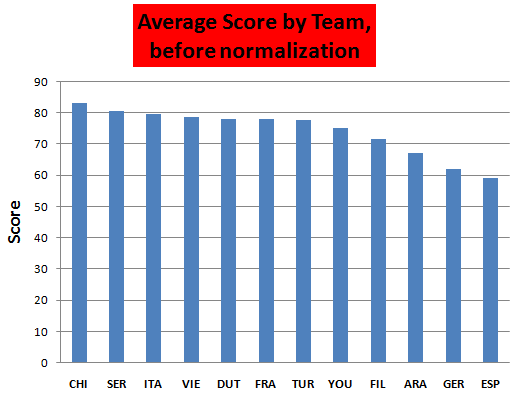
Let's make it more dramatic. Such an inequality :D
Now, let's normalize the scores to the word count:
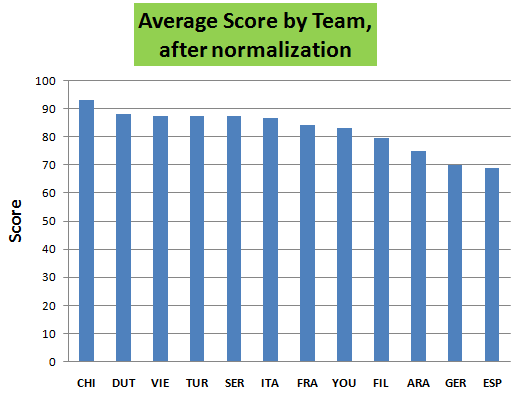
As you can see, the perfect equality.
Several translations contained a lot of errors and that's basically it...
In Conclusion
- Always normalize the data
- Don't consider points if the relation to ranks is not linear-ish
- Don't use average if the distribution is not normal distribution
- There is no need to have multiple questions if the answers are highly correlated
The only question that is "controversial" is the distribution of ranks for "quality of post".
Duch and Serbs, maybe we are too harsh:
The difference is only 3 points, so - who cares.
There was also 1 post with all Excellent scores, except the Rank 4 in Errors, a bit unusual.
There are lots of visuals to relate here. I can see you put a lot of effort in practice, and I appreciate that.
I missed the first post of the series. However, I glance through to get more info.
Your view about the questionnaire isn't a bad one. The questionnaire isn't perfect, and that is why we always try to improve it whenever we can. As you have said, most of those questions are centered around quality, but I think some of those questions are different.
Don't forget, suggestions for improvement are always welcome!
There are a few analysis/visuals I don't understand in the post. I think it would have been clearer, if you have added more texts to give a more detailed explanation.
With the information in the post, I think this post is also about the translation post by silviu95 and the review given to it. The mistake does not look nice, and such shouldn't persist.
As you have said, 'we all are doing a good job''. Thank you!
Please note that while the CM hasn't changed the footer, I am not scoring #iamutopian posts based on the questionnaire. They have their own metric, and that will be the case until we go live with the new guidelines and new questionnaire, which will be comprehensive enough to reflect these types of posts.
To view those questions and the relevant answers related to your post, click here.
Chat with us on Discord.
[utopian-moderator]
Concerning the questionnaire, I had a very radical solution - but it wasn't accepted.
The basic premise is that translation must be as good as possible.
Clients must get the top quality, no discussion about that.
As all the translations will be perfect when finished - all the translations are equal. Scores will be equal.
As the consequence... Moderators are forced to get the best translators, in order to facilitate their own work.
The level of quality is going up, there are no sparks between translators and moderators as they are collaborators and not rivals. There is no bad blood between the teams concerning the scores *(as all scores are equal). Of course, if translators are bad - they will be replaced.
In the current system, there are several things which are not very logical:
Or... We can see that all the parameters concerning quality are telling us that the translation is "so-so", but there is only one error. Ho-how... If it's bad - make it better. Imagine having 200-300 strings, 1 mistake and the quality is "meh... so-so". It's not very logical to me.
I also can't understand how some people are constantly making 10 mistakes per 1000 words. My answer is already 300 words long. Imagine 3-4 errors, made while writing in the native language. How is it possible - I don't understand.
Your idea is good, regarding the quality of translations. However, I believe that, within a group of professional, there are people that will be superior. Thus, there is no how the quality of work would be equal.
Some people have years of experience in translation, while some aren't. Yet, anyone can get better if the chance is given. As I have mentioned in my comment above, things are not really perfect now, but it would be better to look for a less strict way.
Also, anyone that provides way less quality could be replaced since we want good translations. We shouldn't nurture poor works.
Thank you for your review, @tykee! Keep up the good work!
Very interesting post, thank you.
Regarding the post by @silviu93 that you singled out, you are very correct in your assumption that something didn’t match.
That something mostly had to do with me traveling to Austria and surprisingly not being able to (1) use international roaming and (2) find some decent WiFi that allowed me to review/notify my team of my predicament until the post was 6 days old. When I finally managed to find some network, it was the spa’s WiFi, which meant I had very limited time to actually use my phone. After completing the review I rushed through the scoring, actually assuming the post would miss its payout. I have now checked back on the post and was surprised to see I was wrong on the last account (and I’m glad for Silviu on that account, since he’s been rather unlucky with payouts lately).
Nevertheless, your assumption was correct: most of the mistakes pertaining that translation batch were missed spaces or extra commas (which is probably the most common mistake in the Italian team: we don’t use the Oxford comma in Italian, but it’s easy to forget to take it off when the string is a simple list of words left in English). In general, though, I do agree with you that 6 mistakes should affect the other scores, too.
I also agree on the fact that 5 out of 6 questions basically judge the same exact thing when a translation is well made. And frankly, I have never reviewed translations that were not well made, which I believe it’s the whole point of this project. I have never seen this as a learning environment but rather as a collection of already-skilled individuals. Sure, some of the translators have gotten better with time than they were at the beginning: practice will do that for everything and everyone. But the whole point in recruiting them was that they were already good at this.
I don’t particularly hate the new questionnaire and I actually like it more than its predecessor. But I find it redundant and in some aspects inadequate (why the gap in mistakes count? why give up on the major/minor mistake breakdown?). I had repeatedly voiced my opinion in writing back when we were brainstorming, both in comments and posts, but was unable to participate in the vocal chat due to work engagements. It seems like the only thing that mattered, in the end, was the vocal chat though, and whatever opinion wasn’t voiced over there didn’t really matter. So I’ve just given up on the issue and simply use what tools I’ve been given.
Don't worry, it's maybe 10 points = 2-3 $ = a good coffee :)
Hey, @alexs1320!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Thanks for this! I want to study a good book on statistics, or a udemy class but now is not the time. So your expert delivery is appreciated in the meantime. I have been traveling for work a lot but hopefully I will put some time on the EM420 this weekend before I leave again for 2 weeks.
Hi @alexs1320!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
omg