Good, Bad and Ugly - Statistics. How not to do it?
After 9 years of work in the field of applicative math, mainly with biologists and chemists, I've learned that there are three basic categories of people:
- those who know statistics - and do it for themselves
- those who know that they don't know - they call me
- those who don't know but they still prefer DIY method - they are wasting their time and tears
When you don't know - that's ok
When you don't know that you don't know - it's dangerous
How to do pointless statistics
A few days ago, my team and I were accused for achieving too high average scores for our translations.
THE FIRST RULE OF AVERAGE - CHECK YOUR DISTRIBUTION!
This is a common pitfall for those who are not specialists.
You think that "average" is always telling you the truth, but it's far from truth.
If your data are looking like this - it's perfectly fine to use average:
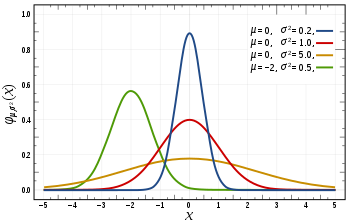
This is so-called "normal distribution". Your IQ, your height, weight are distributed just like that.
In reality, you can also encounter something like this:
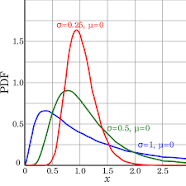
In this case, your average will be shifted and it will tell you absolutely nothing. In this case, you should "trim" the extreme values of you should try to find if it's possible to decompose this curve into the sum of individual distributions. Or, if you are lazy, you could use median instead of average.
Median means: 50% of cases will have the value lower than this, and 50% will have the value higher than this.
For example, this is how music records, sports statistics, scientific papers align.
Or... You can encounter distributions with two distinct peaks. In that case, the average value is telling you nothing.
How many legs people have? On average, 1.978 *(I guess). The correct answer is 2.
Distribution of DaVinci Scores:
I took all the relevant data from the Utopian Review Sheet.
The rest was done in Excel.
Let's examine the distribution of scores after the new system was introduced:
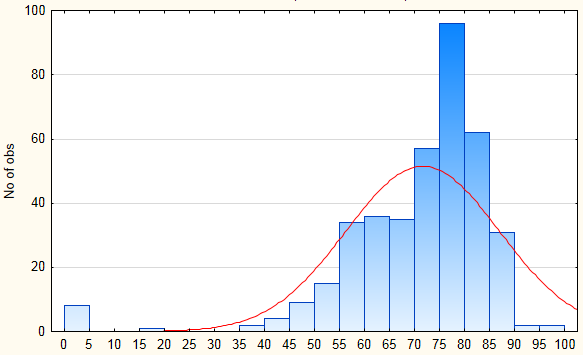
This distribution is obviously not normal. Not that "normal", normal... :D
Let's remove those extremely small values and draw one more histogram:
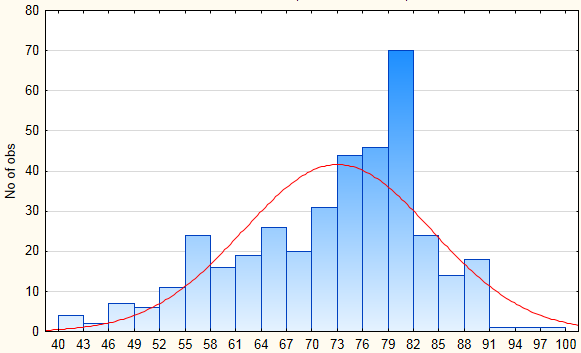
As you can see, the majority of scores will be around 80 points.
Also, take a look at the region of 60 - there is a peak forming there.
Why are some authors constantly getting 60? Quality? Problems with translators? Problems with Moderators?
What does it mean?
The majority of translations is Very Good or Excellent - APPLAUSE TO ALL OF US!!!
At this point I'll make some predictions:
- teams with members who are not consistent will have a significantly lower average score
- median values will be much more similar
- teams who are submitting 2000+ words will have 1-2 points higher average score
- but very similar median score
I'm typing this in real time, my tables and Figures will be ugly, but you will see the point
The workflow:
- I will extract all the individuals and check their distribution of scores
- for every individua I will apply: countif, averageif, min(if, max(if and median(if
It's a very standard and easy approach and here is what I found:
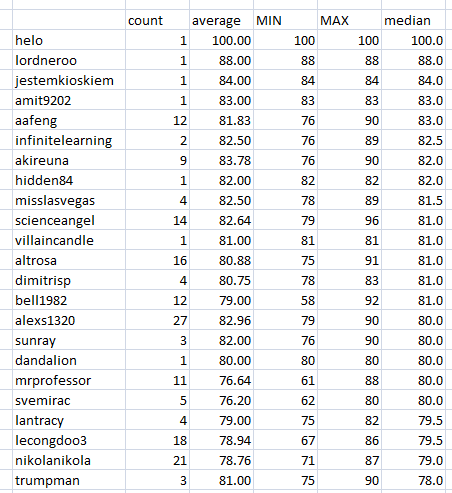
The most experienced contributors:
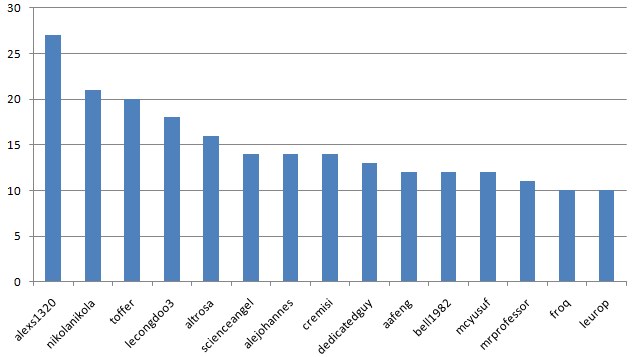
I'm No.1 followed by that competitive, sporty young man @nikolanikola .
The average will be affected by the lowest achieved score, because from the most common score, 80, there is only 10 points to gain, but 50 to lose!
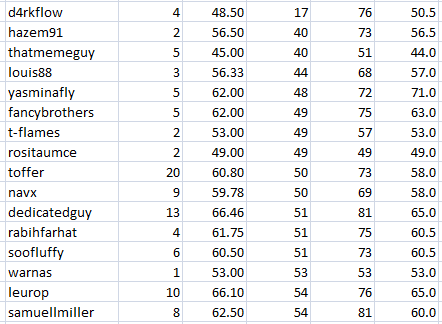
Some of the translators in this group are struggling, although they are working a lot.
Talk to them, to their Moderators - find the problem.
I'm stressing this because many of them were also struggling in the "old system".
And here is the proof. All the people with the highest average score are those who never failed.
Why do you see 2 members of the Serbian Team on this list? It's because we are submitting 2000+ words relatively often.
2000 vs 1000 words = +10 points
Multiply that with the frequency of 2000+ words and you will see that normalized to 1000 words, the results should be about 2 points lower.
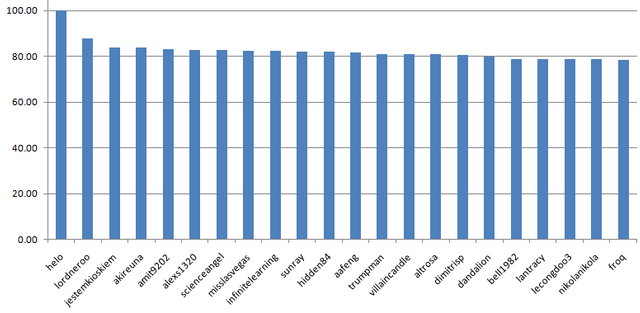
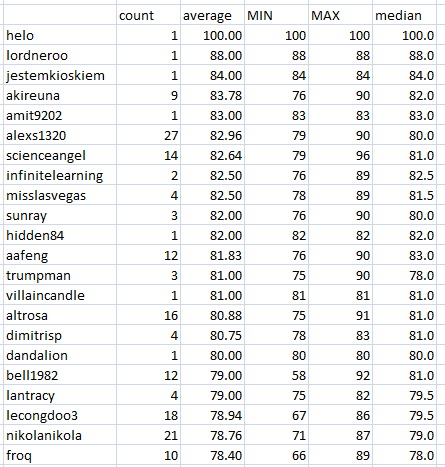
Median is FLAT (Earth is not):
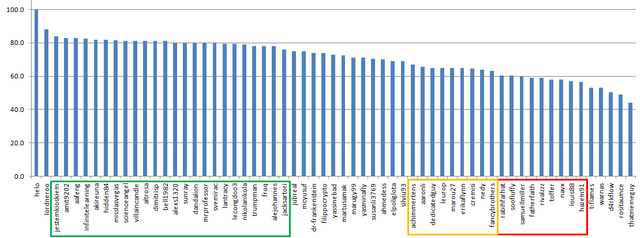
21 author is in +-3 points around 80
You can also see the pattern at 60 points where the people are struggling:
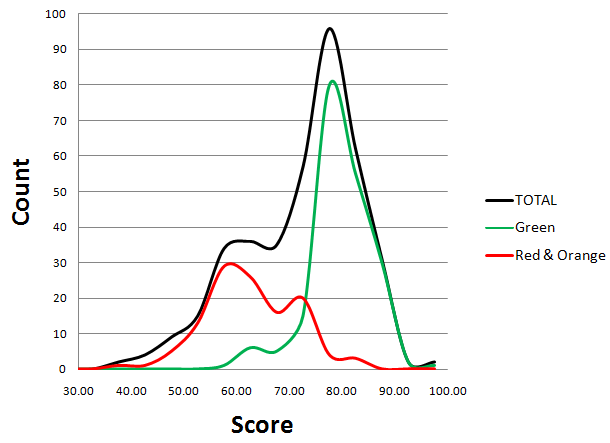
Now, let's decompose the "histogram curve" into 2 sub-histograms, formed by "green" , "orange" , and "red" users:
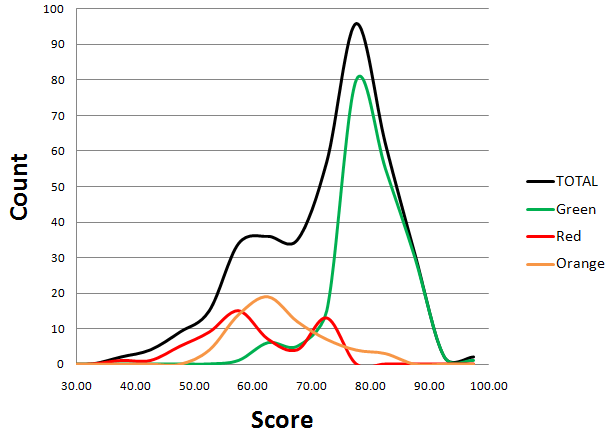
This version is even better:
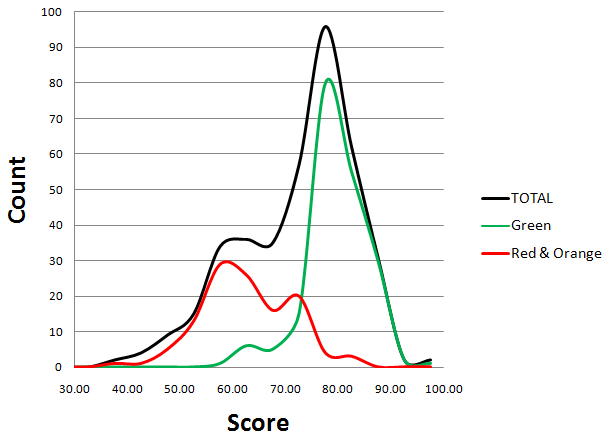
Now we can see 4 or 5 distinguishable peaks. If you want to understand why, read the Appendix (Update).
CONCLUSION
- There are two groups of authors, those scoring about 80 points and those scoring about 60 points
- Median value is basically the same within the two groups
- There is no bias, there are two levels of quality
MODERATORS
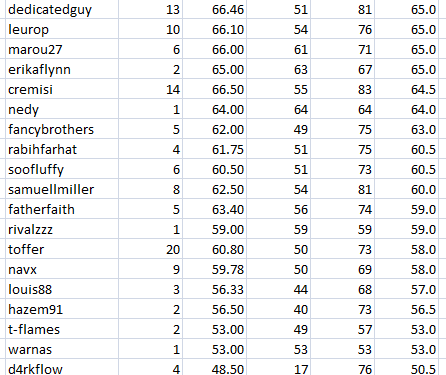
Let's see who has the most experience:
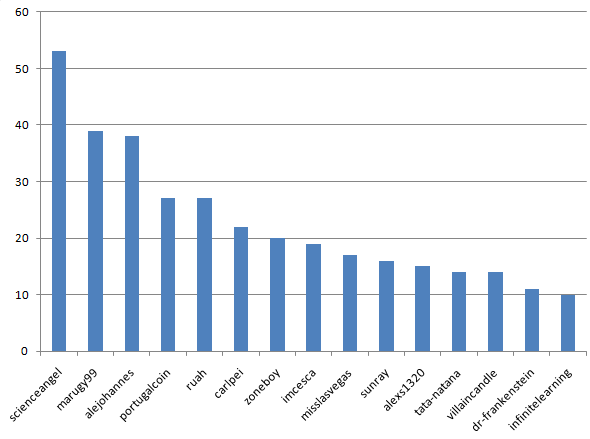
@scienceangel with two maniacs @alexs1320 @nikolanikola and @svemirac
Who was struggling the most with the own team, by minimal scores:
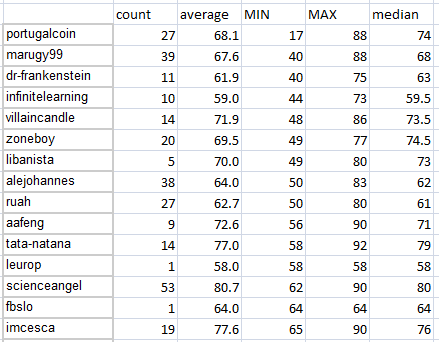
Of course, the average score will be affected in that case:
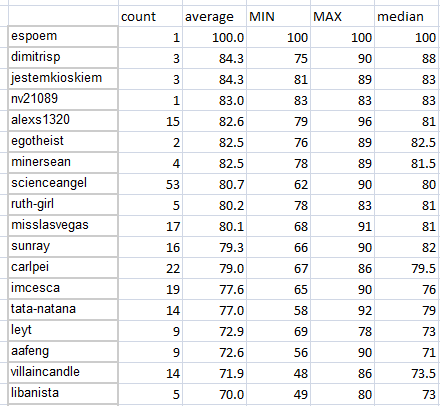
However, the median will be...
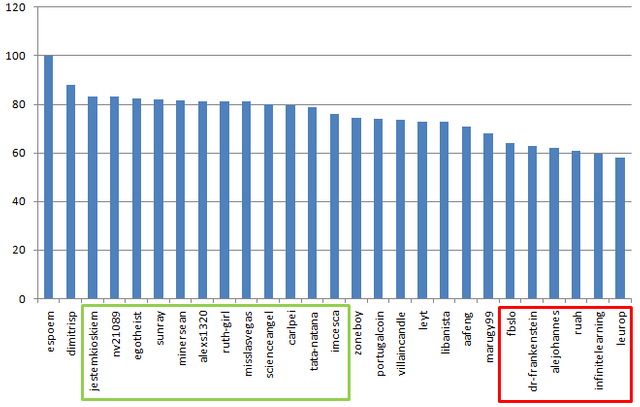
FLAT, AGAIN!
Watch closely what happen if I replace median with average:
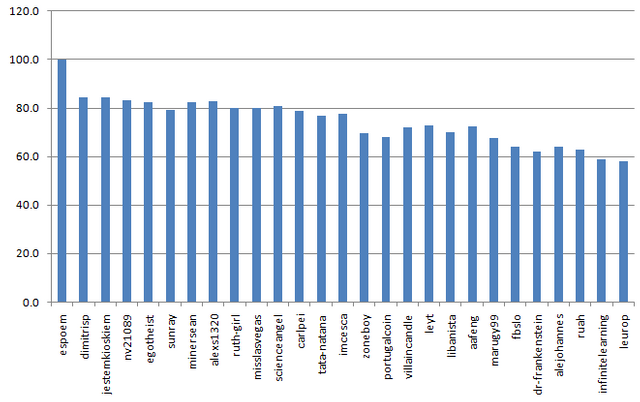
It's a completely wrong method
General Conclusion
There are three distinguishable groups of translators (and consequently Moderators):
- Group of consistent authors, scoring 80 points
- Group of authors who are struggling, scoring about 60-65 points
- Group of authors who are more-less consistent, but can occasionally score below the expectations
What should we do with this?
I think that we should have more translations worth 80 points.
We should foster high-quality contributions and encourage the members to work better.
If there are two distinguishabe groups out quality will be inconsisten and the whole project would be compromised
(*you see... :D )
Update
For those who are not involved in the project, like @chappertron , I will make a "simulation".
Let's examine the hypothetical score:
- accuracy - excellent
- consistency - excellent
- legibility - excellent
- sufficient post, 1000 words
Number of errors:
- No Errors: 86
- 1 Error: 78 (-8 points, -8 points per error)
- 3 Errors: 72 (-6 points, -3 points per new error)
- 6 Errors: 67 (-5 points, -1.67 points per new error)
- 10 Errors: 63 (-4 points, -1 point per new error)
Given values are responsible for those 4.5 peaks I mentioned:
Errors are giving peaks - all other options are just making those peaks "wider / broaded".
This is why we don't have and can't have "smooth" distribution of scores.
Why is the "error of innocence" this expensive, 8 points - I don't know.
How is it possible that you can almost double the errors and lose only 4 points - I don't know.
Hypothetical situation No.2: everything is done perfectly well. The project is 20.000 words long.
This is how it can be "sold":
- 10 x 2000 words = 10 x 100 = 1000 points
- 11 x 1800 words = 11 x 98 = 1078 points
- 11 x 1600 words = 12 x 96 = 1152 points
- 14 x 1400 words = 14 x 94 = 1316 points
- 16 x 1200 words = 16 x 92 = 1472 points
- 20 x 1000 words = 20 x 90 = 1800 points
How is it possible that you can earn between 1000 and 1800 points for the same task - I don't know.
Hi, @alexs1320. Thanks for sharing this. This was a mixed bag for me and I had a hard time understanding some of the analysis. I was surprised to read that your team was "accused." I am not sure but I believe that the DaVinci team don't mean it that way. I appreciate that you have given a thorough analysis of how the scores are being distributed even though some of the charts and tables are quite unclear to me.
While going through the tables, and, the chart, I had noticed that you included users or moderators that has nothing to do with the DaVinci or translation moderation team which makes me wonder how you have collected your data.
With that said, I'd like to invite you to join moderator's private call on Utopian server where we can discuss this issues at length and try to figure out together how we could improve the moderation process in the team.
Please note that this post is not scored based on the questionnaire. #iamutopian post have there own metric, and that will be the case until we go live with the new guidelines and new questionnaire, which will be comprehensive enough to reflect these types of posts.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Chat with us on Discord.
[utopian-moderator]
Hello!
There were a few minor sparks, so I wanted to clarify everything using proper statistical methods and demonstrable facts. Problem without a problem...
Data were collected from the official DaVinci Sheet, for the period: September 2018 - February 2019. The idea was to cover the "old rules" (as control) and cross-compare with the "new rules" (about 350 contributions). I can send you corresponding Excel file.
What I see as the problem is the strange rule, which is a sophism:
Thank you for your review, @knowledges! Keep up the good work!
Hey there,
very cool article. Resteem!
But one thing: Is it really ok to trim a distribution to get a normal distribution? Of course, if you want to perform a t-test a normal distribution is a prerequisite. But for all the "other" distributions many different tools and approaches exist.
Have a nice weekend
Cheers
Chapper
Great Question!
You are right, it's not a good thing to do, unless...
You know that occasionally you can find your results where those should not appear.
In the case of DaVinci, there is a strong cut-off for translations with many errors.
It could happen *(several times in 300+ translations) that some contributions are very, very bad and thus heavily penalized.
With that in mind, it would be fine to simply forget that value.
In the analogy with a sharp-shooter:
It's fine... Who knows what happened, a bad round, mosquito... :)
We can forget that one
However, if we see something like this:
It's a mistake that should be fixed
Did someone mention shooting??? ❤❤❤
I prefer using a silhouette though, it allows you to focus on the head... and to miss it.
Wow... Italians, people who turn everything they touch into art
Perfect!
100% Agree.
Have a nice Weekend!
Chapper
Hi @alexs1320!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Hey, @alexs1320!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!