Artificial Intelligence Basics - Reinforcement Learning, Inverse Reinforcement Learning and Cooperative Inverse Reinforcement Learning
Series introduction
Another anticipated series is here. I was often times talking about the discussions and presentations I have been attending ever since I finished the bachelor’s degree. I have taken a little break from active steeming the previous month in order to restart my body after the injury I suffered at the start of this season, therefore I haven’t been reporting what I’ve learned across those discussions. It’s time to make up for it. Without further ado, let me introduce “Artificial intelligence basics” series.
All the topics that will be covered in this series are going to be obtained from an “AI Safety Reading Group” that I visit whenever I have time. This group is led by a guy that I got to know through “Less Wrong” group (check this video time 10:23 – 11:45 if you don’t know what Less Wrong is). He wants to pursue his career in AI and meanwhile he presents the problems AI currently has to his friends from technical faculties…and me. The funniest part is when they all speak in “math language” and then they combine all their strengths to somehow translate it to me:D.
I am no mathematician therefore I won’t ever share formulas or functions here. I’ll try to explain everything in natural language. The aim of the series is to spread the awareness about Artificial intelligence, for I couldn’t contribute to the professionals in any way apart from asking good questions from time to time. I think that since increasing implementation of AIs is inevitable, it’s important to understand at least the basic concepts of what it can and can’t do.
Reinforcement Learning
First of all it’s important to grasp, what is the difference between casual bot and AI. Casual scripts (bots) are always deterministic. They function in a way where human being sets precisely what should happen given certain circumstances and what shouldn’t happen given certain circumstances. The bot then only follows the rules and associated certain actions with certain prerequisites. An example could be a voting bot on Steem. You tell it at what time should it vote on article, what is the maximum current potential payout of the article for it to be eligible for the vote, potentially whose articles will and whose won’t be voted on.
Reinforcement learning is a method, through which agents (robots, the AIs) learn for themselves what should be done if certain circumstances occur. Let me explain how this is done on the simplest example.
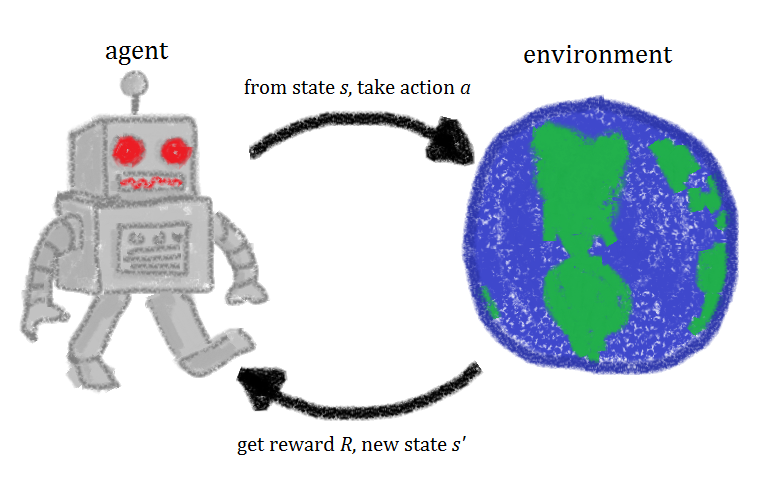
The agent knows the environment in which it’s operating, the actions it can take and the state it currently is in. It also knows positive and negative rewards that can be acquired in the environment. Whenever it takes an action, it receives feedback in form of a) no reward, b) positive reward c) negative reward. According to the reward it reassess the state it currently is in. That’s it! Those are all the rules it has.
I’ll try to make the situation less abstract on my carefully created and edited super model.
The following table is the known environment. It is fully observable (the agent knows how the whole environment looks like and where the rewards are located. The agent can take “one step per round” and only horizontally or vertically. There is only one positive reward in the whole environment.

There is nothing extraordinary to happen. The agent will always go for the reward in two rounds in this example. That’s the optimal behaviour for the agent.
But what if the environment is only partially observable?

Then “exploration” comes into play. The method through which the observation is going to be done can differ along with the applied decision making models. Nevertheless, the agent will not simply go for the reward, for it doesn’t know whether there isn’t better reward in the “fog of war”. If there wouldn’t be any other reward, the same actions would be taken as in the example one, for the agent always seeks the most rewards in the fewest steps.
But the last sentence can become much trickier than it would seem from the first glimpse. Now imagine, that the table is only part of the partially observable environment. It would look like this

Now imagine a “bait situation”. Ever since some kind of “art of war” was discovered, enemies often tried to bait the opposition to undesirable situation. Imagine the +1 reward as a very carefully positioned short-termed reward by "the opposition" (can actually be very neutral entity). When the agent would pick up the +1 reward, following changes would occur to the state of the environment. Also take into account that -50 reward results in "death" or "game over".

You guessed it right. The agent is fucked because it followed the short-term interest. This doesn’t “break” the algorithm or anything like that. It is a “machine learning” problem. The agent will learn and won’t take the bait next time. So when I said “the agent always seeks the most rewards in the fewest steps” I didn’t mean that it will blindly seek the rewards. It will learn from its mistakes and seek the “bigger picture” because long-term interest is more profitable if the “game over” doesn’t occur.
Inverse Reinforcement Learning
The problem with RL is that the humans have to manually create the reward functions. This leads to humans tweaking the reward functions until the desired agent’s behaviour is finally incentivized. Rl most of the times lacks the natural incentive. [2]
As the name (IRL) implies, it switches the input with the outcome that we search for. In the RL the input for the agent is the reward function and it then searches for the optimal behaviour, whereas in IRL the agent is given the optimal policy (often times “gathered” by observation of human professionals) and it then searches for the reward function that would incentivizes it to reach the optimal behaviour. [2]
IRL is especially useful when we want the AI to do a human’s task. Clutch thing is that even if the environment where the reward functions were obtained changes, the reward function still remains relevant, unlike “optimal behaviour” that changes with the environment. [2]
Cooperative Inverse Reinforcement Learning
CIRL is then used when we want the AI to cooperate with a human being. In this model, the AI knows that it is in a shared environment with the human being and its goal is to maximize the human’s reward function. That is a different than if the AI just took the human’s reward function for its own. For example if a human being wanted coffee in the morning, we wouldn’t want the AI to want coffee too! We want the Ai to anticipate that we will want coffee and provide it to the human to maximize his effectivity. In this model the human knows the reward function, and the Ai does not. Essential part of this model is the human guiding the AI I order for it to truly maximize the human’s reward function. [3]
Conclusion
In the article I presented 3 reinforcement learning models, where every one of them has its unique use cases.
Casual RL is particularly useful if we do not know the optimal behaviour, but do know the environment. It is then very good for uncovering the optimal behaviour emphasizing the long-term point of view.
IRL is then very useful if we do not know how to form the reward function, but when we do know what the optimal behaviour should be. It’s therefore good for situations when we want the Ai to mimic human professionals.
Finally CIRL is used if we don’t want the Ai to take our reward function for its own, but when we want the AI to maximize our reward function and cooperate with us.
Sources

I myself have recently starting learning learning, to apply it to few particle physics problems I am after. I find your article very interesting, well written, and it is a bit sad no one but bots commented it.
Please consider joining us on the steemstem discord server. A steemstem comment with the links should appear in no time... yes, I know, another bot (:p).
Thanks for the support! It’s much appreciated. I still believe that maybe in time more human beings than bots will engage on my articles. I have already joined the discord, it’s just that I’m not really active on them since there are too many discord servers and too little time to engage on them...I prefer the on-chain interaction:).
Which learning models have you been studying?
I really started with the basics. I am following the Caltech course by Y. Abu-Mostafa, but am progressing very slowly as I am doing too many things at the same time. I want to go to the neutral network part, but understanding everything in all details. Not just downloading tensorflow and playing with it as a black blox if you see what I mean.
Congratulations! Your post has been selected as a daily Steemit truffle! It is listed on rank 2 of all contributions awarded today. You can find the TOP DAILY TRUFFLE PICKS HERE.
I upvoted your contribution because to my mind your post is at least 13 SBD worth and should receive 201 votes. It's now up to the lovely Steemit community to make this come true.
I am
TrufflePig, an Artificial Intelligence Bot that helps minnows and content curators using Machine Learning. If you are curious how I select content, you can find an explanation here!Have a nice day and sincerely yours,

TrufflePigHi @fingersik!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your UA account score is currently 4.666 which ranks you at #1498 across all Steem accounts.
Your rank has not changed in the last three days.
In our last Algorithmic Curation Round, consisting of 361 contributions, your post is ranked at #315.
Evaluation of your UA score:
Feel free to join our @steem-ua Discord server
@fingersik You have received a 100% upvote from @steemmentor because this post did not use any bidbots and you have not used bidbots in the last 30 days!
Upvoting this comment will help keep this service running.
This post has been voted on by the steemstem curation team and voting trail.
There is more to SteemSTEM than just writing posts, check here for some more tips on being a community member. You can also join our discord here to get to know the rest of the community!
Hi @fingersik!
Your post was upvoted by utopian.io in cooperation with steemstem - supporting knowledge, innovation and technological advancement on the Steem Blockchain.
Contribute to Open Source with utopian.io
Learn how to contribute on our website and join the new open source economy.
Want to chat? Join the Utopian Community on Discord https://discord.gg/h52nFrV