Biology The Study of Life: Part 10 (Genetic Code)

Introduction
This informative series of posts will explore modern biology; the fundamental principles of how living systems work. This material will always be presented at the level of a first-year college biology course, without assuming any prior background in biology or science. It also presents material in a conceptual format. Emphasizing the importance of broad, unifying principles, facts and details in the context of developing an overarching framework. Finally, the series takes a historical approach wherever possible. Explaining how key experiments and observations led to our current state of knowledge and introducing many of the people responsible for creating the modern science of biology.
This post turns the discussion to the second major property necessary for DNA to function as an information-bearing molecule, namely, the physical basis of the genetic code itself.
The post describes how differences in the structure of DNA and protein molecules impose a limitation on how the former can encode information about the latter, and it shows how this limitation suggests an inherent structure for the code. The post then discusses the clever combination of experimental work and puzzle-solving that was used to crack the code and describes the code’s defining properties.
A cryptoquote puzzle is an example of a simple substitution code.
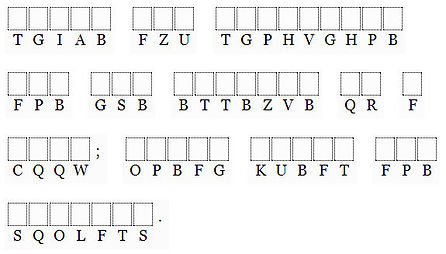
All the original letters have been substituted, but the substitutions are always the same, for example, W is always substituted for A and so on. Solving the puzzle involves figuring out the appropriate substitutions.
A code used for protein synthesis must be more complex, for two reasons.
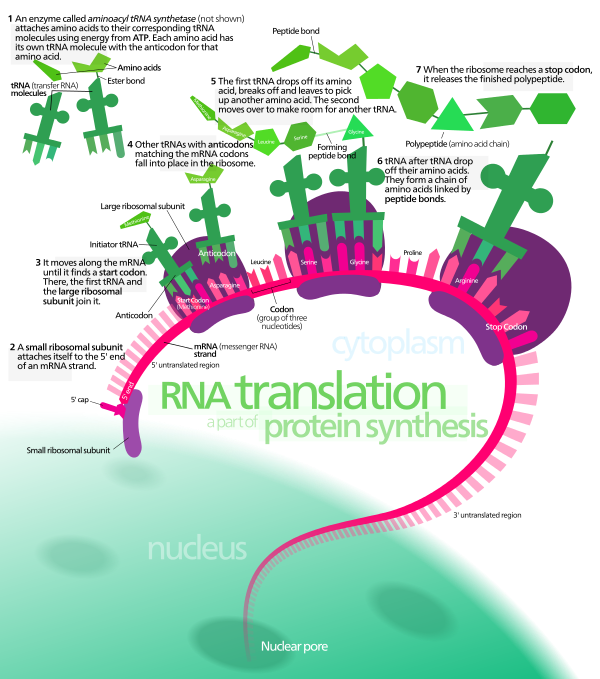
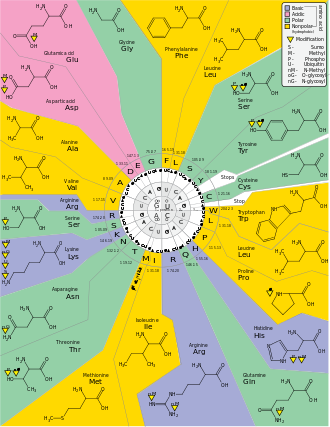
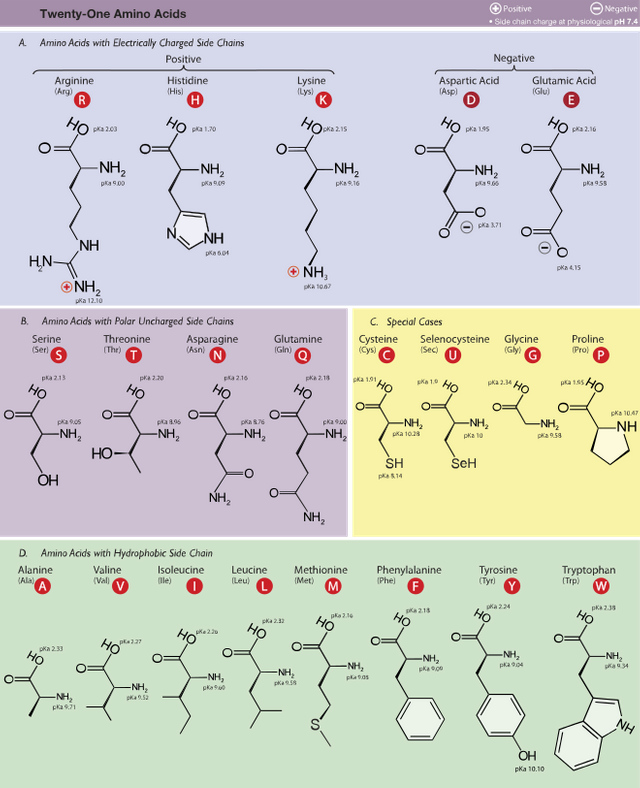
DNA and proteins are different kinds of molecules, and any code that substitutes nucleotides for amino acids must have an inherently predictable chemical correspondence. Because DNA and proteins have quite different biochemical properties, a direct correspondence is unlikely. Francis Crick was the first to suggest that there must be an adapter molecule that could attach specific amino acids at one end and recognize nucleotide sequences at the other end. Transfer RNA (tRNA) are small, specialized segments of RNA that perform this function. The DNA code cannot be a simple substitution code because DNA has only 4 variable elements, while proteins have 20. This means that sequences of more than one nucleotide must code for single amino acids.
How many nucleotide base “letters” are required to provide an adequate code for amino acid “words”?
A two-letter code would yield 16 possible words (4 x 4 = 16), which is not enough to unambiguously code for 20 different amino acids; a four letter code would yield 256 possible combinations (4 x 4 x 4 x 4 = 256), which is far more than needed. A three-letter code yields 64 combinations (4 x 4 x 4 = 64) and would appear to be the most likely candidate for the number of nucleotides required to code unambiguously for amino acids.
Francis Crick and his colleagues proved that a three-letter code is correct.
First, they used acridines to delete or add single base pairs from DNA molecules. Each addition or deletion offset the code by one unit, essentially turning it into meaningless gibberish. Crick and his partners found that the deletion or addition of three base pairs brought the code back into register, similar to deleting a word in a sentence made of three-letter words.
The genetic code is a triplet code, with unique combinations of three nucleotide bases referred to as codons.
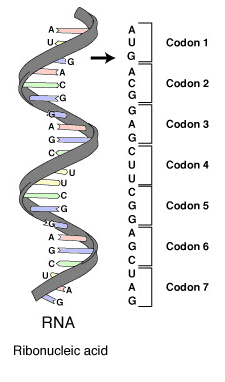
Many experiments have verified this conclusion, but how did molecular biologists eventually discover which codons specified which amino acids? The solution to this problem came from the development in the 1960s of the ability to synthesize artificial DNA sequences in the laboratory, then to use these synthetic sequences as templates for protein synthesis. Scientists started by polymerizing a single base, such as uracil, then forming proteins from those sequences. The only possible conclusion is that the protein formed (phenylalanine) is coded for by UUU. Decoding mixed codons involved adding different proportions of nucleotides to a synthesis reaction. By calculating the proportions of the resulting codon combinations and comparing these results to the proportions of amino acids produced, scientists eventually filled in the amino acid definitions for all 64 possible combinations of three nucleotide bases. Techniques developed later permit more precise codon synthesis, but work with these methods only confirmed the original codon definitions
A brief look at the codon “dictionary” illustrates several important features.
First, 61 of the 64 possible codons code for a particular amino acid. Because there are only 20 kinds of amino acids used in proteins, some amino acids are coded for by more than one codon. This redundancy mostly involves variation in the last nucleotide in a codon. The triplet code is unambiguous, however; each codon codes for only a single amino acid. Three codons do not code for any amino acid but, instead, serve solely as “stop” signals. One codon (AUG) serves a dual function; it codes for methionine and serves as a “start” signal, indicating where an RNA transcript should begin. All mRNA begins with AUG, which provides an unambiguous marker of the first nucleotide base in a sequence of codons. Without this codon, offsets in transcription by 1 or 2 bases would yield an entirely different set of codons and, thus, an incorrect protein structure. All polypeptides, therefore, begin with methionine, but it is often stripped off by an enzyme after the protein is produced.
The genetic code is universal.
With only a few minor exceptions, particular codons specify the same amino acids in all organisms. The universality of the genetic code is essential for the modern revolution in biotechnology. Because all organisms share the same code, we can perform genetic engineering by transferring DNA from one organism to another. Common examples of genetic engineering include insulin-producing bacteria, plants with built-in pesticides, and gene therapy. The universality of the genetic code also suggests that the code and its fundamental mechanisms arose very early in the history of life on Earth. This, in turn, suggests that all life derived from a single, common, primitive ancestor. Exceptions to the genetic code are rare, minor, and usually involve (1) assigning one of the stop codons to an amino acid or (2) an ancient divergence, such as the development of mitochondria or chloroplasts. The way DNA encodes information about proteins would be different if there were more kinds of nucleotides than four. It is essential that the genetic code be “unambiguous” but not a problem that it is “redundant”.
END PART 10
BIOLOGY THE STUDY OF LIFE:
PART 1 INTRODUCTION
PART 2 WHAT IS LIFE
PART 3 ORIGIN OF LIFE
PART 4 CELL TO ORGANISM
PART 5 PROTEINS
PART 6 CODE OF LIFE
PART 7 DOUBLE HELIX
PART 8 REPLICATING DNA
PART 9 CENTRAL DOGMA
PART 10 GENETIC CODE

 or
or  @pjheinz
@pjheinzImage Credits:
ALL IMAGES UNLESS NOTED - Wikipedia
These are all fantastic revision for me. It is frightening how quickly you can forget stuff. Thank you:)