Automating Multi-Lingual and Multi-Speaker Closed-Captioning and Transcripting Workflow with srt2vtt
As some in the STEEMIT community are aware, I recently released srt2vtt on github (built in JAVA) to help simplify and automate many of the tasks involved in creating multi-lingual closed-caption scripts and transcripts for the Bitshares and Beyond Bitcoin hangouts. This tool (and the associated knowledge acquired, as outlined in this post) may also be invaluable for any number of other STEEMIT-related projects, including MSPWaves radio.
Given the way our captioning "workflow" seemed to be spiraling out of control, I was forced to take a step back, tune out all the outside "noise", and remember what exactly we were trying to solve here. I had to find my way back to "the big picture", if you will...
YouTube already does a pretty amazing job with the automated "artificial intelligence (AI) / machine-learning (ML)" captions they create. You can even automagically download translated captions in any number of languages, then download the corresponding caption file for further and more precise editing. But one thing YouTube can't do is identify each individual speaker. And that's really where things became dramatically more complicated.
For example, if you want to edit the video or audio to remove certain phrases, or the "ums" and "you knows" or even the "cough, coughs", the correct way to do it would be to edit and clean up the audio file containing all the speakers before submitting it for captioning! This would also greatly simplify multi-lingual translations because they too would not include all these undesired audio "artifacts". However, we're captioning at the individual speaker level (ie. one audio file per speaker).
Why not just use a multi-track audio/video editor?!
So, for example if we have 8 speakers, we'd have 8 separate audio tracks, and artifacts would have to be removed from all eight tracks simultaneously! How could we possibly do that?! Well, actually, it's not that hard, and may be one of the best overlooked solutions so far... Lay out all 8 tracks in a multitrack audio/video editor, cut unwanted segments over all 8 tracks simultaneously, then export all 8 clean tracks separately. There are any number of editors that should easily be able to achieve this, including the excellent FOSS multitrack audio editors Ardor and Audacity (update: srt2vtt can now also convert caption files to the audacity label format).
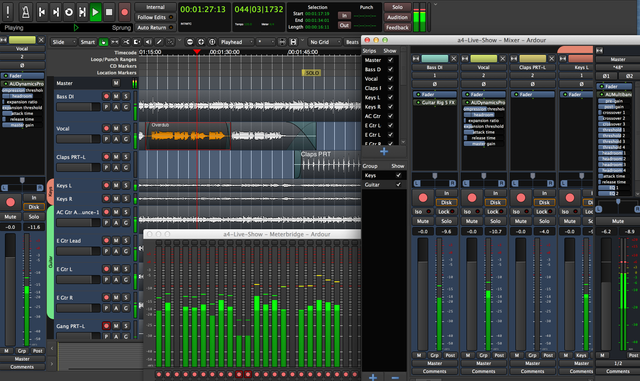
However, if we still choose to perform additional editing afterwards, that means all the caption files would also have to be realigned as well, and for each language. And even if we had word-by-word alignment (which we do, btw! more on that later...) it would obviously not apply to the translations. Anyone who's ever watched just about any 'ole Japanese kung fu movie knows this very well!
But hold on, that all sounds just a bit too easy...
Yeah well, it seems we're not the type of people to choose the logically "easy path". And that easy path would be to focus on getting the best combined audio and transcript right from the start, and find a way to identify each speaker after-the-fact (or at least find a way to reconstruct the data later).
Or we could try using a multitrack audio editor from the getgo, but I digress...
Another way we could accomplish this would be to create separate transcripts for each speaker that can be lined up and used as markers to identify each speaker in the combined final transcript, ughhh.
We could also try one of the following "Speaker Diarization" solutions that can go through audio and identify which speaker is most likely speaking at a given time. However, these can also be a bit tricky to use, and generally require a bit of modeling so the algorithms are familiar with each speaker's voice by feeding an audio sample of each speaker:
- LIUM Speaker Diarization Framework (Java)
- VoiceID: speaker recognition/identification system written in Python, based on the LIUM Speaker Diarization framework (helps automate the process somewhat)
- Microsoft "Speaker Recognition" SASS (software as a service)
The issue of "accuracy" still remains. However, this area is definitely worth further research to see if one of these solutions could dramatically streamline the entire workflow (besides trying to use a multitrack audio editor, of course)!
In the meantime...
It seems, for now at least, the more complicated way of generating captions is the way to go (unless perhaps my idea of using a multitrack audio editor catches on). That is to say, more precise captions could be generated by uploading each speaker's unedited audio track separately to YouTube, then downloading each AI-generated caption file and recombining them into a single audio and caption track, along with who was currently speaking (extracted as the filename, ie. @officialfuzzy.srt). This could easily be achieved by srt2vtt via the following commands:
- "srt2vtt @host.srt @spkr1.srt @spkr2.srt titles.srt ... o:output.vtt output.htm"
the first caption file would be the "host", a "titles" file could be included to add "segment" headers, and "output.vtt" would contain the combined caption-file of all speakers ready for re-upload to YouTube, and "output.htm" would contain the combined transcript that could be easily incorporated into a STEEMIT post.
That worked great at first, until as I had suspected, there were still issues with creating "cleaner transcripts", as automated captioning does not include the usual punctuation. The person creating the transcript would still have to go through and add punctuation and paragraph markers and such. But perhaps we could simplify that process a bit further as well.
After much searching and testing, we decided that the punctuator project (a bidirectional recurrent neural network model with attention mechanism for restoring missing punctuation in unsegmented text), while not perfect, made a good option for an automated AI cleanup solution. So I added the ability to automatically submit each caption segment to the punctuator "service" by adding the normalize keyword on the srt2vtt command-line:
- "srt2vtt @host.srt *.srt *.vtt o:output.vtt output.htm normalize"
*.srt also lets you use a wildcard to select all the remaining SubRIP or WebVTT files (yes, both can now be used as input files, more on this later!) in a particular directory
Next of course, the issue of editing the combined audio and caption files came up. Why can't we easily edit audio files and keep the captions aligned at the same time?! Well, a FOSS project called Hyperaudio lets you pretty much do exactly that. However it's more about recombining video into new clips rather than cutting and splicing, though it still seems like a very interesting solution to me. Nonetheless, the discussion kept going back to why we can't have word-by-word alignment, with the ability to "easily" cut out any unwanted words (instead of multitrack editing the original audio files in unison before captioning?! oops, sorry, I said it again! lol).
Well, for one thing, many of those sounds tend to be including along with other captions (ie. "so this is [cough cough] what I said"). So even with word-by-word alignment, it's likely the cough will either be part of the "is" or "what" caption, or a new caption would have to be added with a reference to "cut" a specified time range from the audio. And this doesn't even address the multi-lingual issues! Wow, I'm starting to feel like the three stooges here, combined into one... Each time a suggestion is made to "simplify" the process, it seems to become exponentially more complex! Ah, but let's not linger on those pesky little details...
Regardless, I added the ability to easily designate in the combined caption file a way to set "cut", "splice", and "end" points. One of my favorite FOSS caption editors is Subtitle Edit. It also lets you split captions and tries to separate the text between the two new captions. Unfortunately, it doesn't do a very good job at it, and it would have probably been better if it just kept all the text on one side or the other (hence, again the "need" for word-by-word caption alignment).
So technically any good caption editor can be used. You could even edit the caption file in your favorite text editor too if you'd prefer. In this case, you see how easy it is to set a cut and splice point in Subtitle Edit. Note that "cut", "splice", and "end" should each be preceded by a pound, to differentiate between a possible word-by-word caption file:
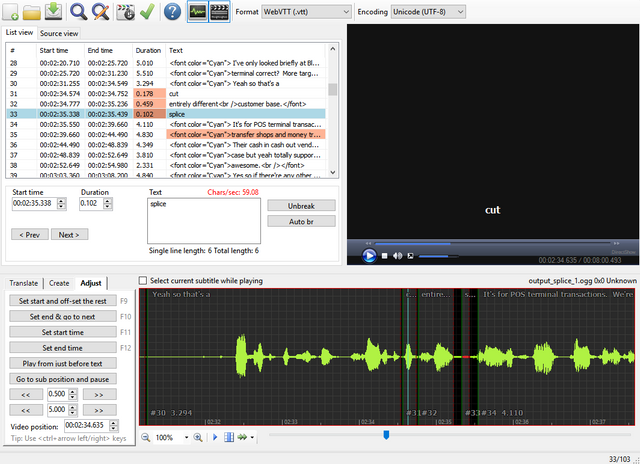
Then, upon running the following command, srt2vtt will automatically generate cut and/or splice points, and correctly time-realign the caption files accordingly, as well as generate a batch file for the user to run that will execute the appropriate commands to complete the task via ffmpeg, another excellent FOSS tool (a complete, cross-platform solution to record, convert and stream audio and video):
- "srt2vtt splice edited.vtt m:media.{mp4|ogg|...} ffmpeg=/ffmpeg/bin/"
After executing this, along with the generated batch file (ie.media.batormedia.sh), all "(pound)cut/splice/end" tags will be removed, and you'll be left with a set of new files to work with:
media_cut.mp4
media_cut.vtt
media_splice_0.mp4 <-- first "segment"
media_splice_0.vtt
media_splice_1.mp4 <-- second "segment"
media_splice_1.vtt
media_splice_2.mp4 <-- third "segment"
media_splice_2.vtt
So now what?!
Now that we've sort of come full circle, how about that word-by-word alignment issue?! Well, after much research and once again trying many different solutions, I found one that seemed to work quite well, and another one that was staring us in the face. It turns out that YouTube itself generates word-by-word aligned captions! However, you must export them via the WebVTT format (which captured the details in a sort of proprietary VTT format), which srt2vtt can now also accept as an input format along with the SubRIP (.srt) format.
If srt2vtt identifes YouTube's word-by-word aligned format, it will automatically splice them down to a "one word per caption" format. Now, some of you may be wondering how do you recreate those into phrases again?! Ah yes, there's that complexity issue again, and another srt2vtt option I'll soon cover! lol
However, the interesting thing with the YouTube word aligned captions is that they still seem slightly off, perhaps to make them more "fluid" while following the captions on screen. Another interesting issue I found was that while I could download these precise timings in a WebVTT file, if I uploaded the exact same file back to YouTube, it no longer worked correctly!
For example, any color annotations were removed, and while YouTube's automated captions literally follow word for word when spoken, when uploaded back the captions kept overlapping. And if I tried uploading each word as a separate caption, YouTube would do just that: show a single word at a time, so you couldn't really see what's coming next (hence srt2vtt's "group" feature). You can see for yourselves from this test upload I used for playing around. Just change the "Subtitles/CC" setting to the various options I made available (they show up as alternate languages) and you'll see what I mean:
So, of course there is also a "group" feature now in srt2vtt:
- "srt2vtt group aligned.vtt --> outputs aligned_grouped.vtt
And, for perhaps an even better word-by-word alignment, I came across the amazing Gentle project (based on Kaldi which may also work for speaker recognition). So I incorporated the ability to convert Gentle's "word-by-word alignment" JSON output file (that even includes the position of each phoneme!) into a WebVTT caption file:
- "srt2vtt align gentle.json" --> outputs gentle.vtt
And finally, you need some sort of "raw" text to submit to Gentle, so I added one more feature that lets you extract all the individual captions into a sort of raw transcript that can be submitted to Gentle or any other parser for testing:
- "srt2vtt raw {group} transcript.{srt|vtt}" --> outputs transcript.txt
In conclusion...
I hope you all found some interesting bits in this post, as well as how easy it is for an idea to get a bit "out of hand"! There's a great quote by Tom Cargill of Bell Labs:
The first 90 percent of the code accounts for the first 90 percent of the development time. The remaining 10 percent of the code accounts for the other 90 percent of the development time.
I also seem to recall another saying, that reaching for that last 10% towards "perfection" will also consume 90% of your time (and perhaps your sanity as well). Sometimes you do have to accept a modicum of "good enough for now", lest we all go mad somewhere along the way!
And sometimes it's also highly productive to tune out all the proverbial "noise" around you, step above what's developing into an "overly complex" workflow, and get back to the "big picture" of what you're really trying to solve in the first place...
As such, I'll leave you with the current list of srt2vtt features built along this interesting and "lesson-reaffirming" journey:
srt2vtt @host.srt @spkr1.srt @spkr2.srt titles.srt ... o:output.vtt output.htm
srt2vtt @host.srt *.srt *.vtt o:output.vtt output.htm {normalize}
inputs can be SRT or VTT, "normalize" submits each phrase of transcript to AI puncuator
srt2vtt splice edited.vtt m:media.{mp4|ogg|...} ffmpeg=/ffmpeg/bin/
use captions: "#cut", "#splice", and "#end" to mark end of media
srt2vtt group aligned.vtt
regroups aligned WebVTT into phrases
srt2vtt align gentle.json
converts gentle (AI alignment) json format to WebVTT format
Note: YouTube WebVTT format also contains word-aligned captions for multiple languages
srt2vtt raw {group} transcript.{srt|vtt}
outputs raw version of transcript (text only) for alignment, etc.
srt2vtt audacity transcript.{srt|vtt}
outputs audacity-compatible text labels from captions file
YouTube "Force Caption" Tag: "yt:cc=on" <-- you can force-enable YouTube captions with this tag!
Oh yeah, and also be sure to play around with some of those cool multi-track audio/video editors too while you're at it! lol
And finally, you can also find additional transcription/captioning-related insights in @nutela's recent post: Research into the next killer app for the blockchain.
Great Blog just started following!
thank you kindly sir! :)
This is insane - but cool that you got this all hammered out! Does this pretty much ease the workflow of transcribing the Whaletank audios?
guess time will tell, we'll see how it goes over in tomorrow's hangouts! lol
Wow! I didn't know that!
The story gets murkier by the minute. Besides of YouTube timing issue, are you sure you're not complicating it yourself? ;)
My intended workflow which has to be tested:
So this should be it or you might point out what I'm missing?
It's important to know the difference between Speech-To-Text and aligning words. Of which the latter should be much easier because you're just guessing which word will be next instead of guessing what word is being spoken or if it is just noise.
Also note that when speaker IDs are inserted into the text that we should not try to align those since they are actually not there.
did you watch the sample YouTube video in my post? Try changing between "English" captions and "English (auto-generated)" to see the difference in display and timings (both of which were excellent for most use cases I would envision, at least with this particular audio sample).
YouTube's captioning before speaker IDs are added, Gentile simply skips over them. But of course, as I explained, using word-by-word captioning may be mostly unnecessary if all audio tracks are simultaneously "corrected" as follows:
1a. Load all tracks into a multitrack audio editor, cut noise/"utterances" over all clips simultaneously, export individual edited tracks
...
Sure I agree that multitrack cleaning is the way to go but SteemPowerPics didn't know how even when I showed it should be possible...
I'm not sure about the speaker IDs, if the speakerIDs are like words/names are in the transcript how can you skip them? With [something] like square brackets?
Kind of missed that part but replace step 3 with anything which works according to your needs right?
Also
srt2vtt @host.srt *.srt *.vtt o:output.vtt output.htm {normalize} inputs can be SRT or VTT, "normalize" submits each phrase of transcript to AI puncuatorIs - I think, not going to get good results because you're feeding the punctuator just parts of a sentence. Which brings me to the next item: caption standards. Captions for each speaker should start with a sentence.
Well we can let that be for now to not get crazy before we start building this!
But in essence well spoken speakers should start their answers or lines with a meaningful sentence anyway.
However even the best speaker will need time to think about an answer and thus fill the void with words or utterances. Maybe a good Machine Learning package could mark such parts and delete those for us automagically... So then the whole process could be fully automated.
captions are submitted after the initial transcript is created, which means the text submitted is the entire stream of text between one speaker and the next...
ie. <speaker1: this whole block of text will be sent as a single block for additional punctuation>
<speaker2: this whole block of text will be sent next>
Well, if you want to go that far, there are some programs I've used that can remove such extraneous "noise", and do quite an amazing job at it. The best ones, however, tend to be quite expensive, and they generally mute/muffle based on a noise print, as opposed to outright cutting text.
For longer words, or even filler phrases, that also starts to enter much more subjective territory. Either way, it still makes the case for pre-filtering the audio tracks before processing to remove as much of this extraneous "noise" as possible. It seems you may have also missed that aspect of my post....
Why don't you remove all the extraneous noise and filler words using a multitrack audio editor over all tracks simultaneously before running through text-to-speech?
Well it just makes no sense prefiltering when with Speech-to-Text you could see where the actual words are in time and filter the noise out accordingly. That's what you can see in the YouTube web app but it doesn't let you edit the audio unfortunately. But if any mulitrack editor could have the words alongside it like YT web app does that would be excellent.
just wanted to add these few links we discussed for reference:
Link: How to Use Truncate Silence and Sound Smarter with Audacity
Link: Howto Truncate Silence in Audacity
Link: Deep Learning 'ahem' detector (github project)
not sure I understand this, but exporting YouTube caption via WebVTT gaves me the individual timings of each word shown in the auto-captioning. The multitrack editing (cutting across all tracks) phase would take place BEFORE any captioning takes place, and you would have already removed any of those undesirable "artifacts".
Interestingly though you might be able to do it that way too in reverse, get combined transcript and convert into audacity labels.. http://wiki.audacityteam.org/wiki/Movie_subtitles_(*.SRT)
Even if all the artifacts aren't there, maybe it makes it easier to find some of them to cut out.
btw, also added a feature to
srt2vttthat converts caption files to the audacity label format:outputs audacity-compatible text labels from captions file
Great work... Congrats! You're such an asset to the community.
Congratulations! This post has been upvoted from the communal account, @minnowsupport, by alexpmorris from the Minnow Support Project. It's a witness project run by aggroed, ausbitbank, teamsteem, theprophet0, someguy123, neoxian, followbtcnews/crimsonclad, and netuoso. The goal is to help Steemit grow by supporting Minnows and creating a social network. Please find us in the Peace, Abundance, and Liberty Network (PALnet) Discord Channel. It's a completely public and open space to all members of the Steemit community who voluntarily choose to be there.
i like ur post, plz also upvote my post
Many thanks for the information, @alexpmorris I'm new to this and I really find your blog very entertaining. follow me
Very nice info dude
কি কস .কিছুই তো বুজিনা