Fireplug - Efficient and Robust Middleware for Geo-Replicated Graph Databases.
Hi everyone, today I want to introduce you to a project I have been developing in the context of my Master thesis and which I am still improving during my P.h.D. Basically, what has been holding me back from publishing on Steem in the last month.
Overview:
Fireplug is an efficient middleware for Graph Databases.
Fireplug operates as a Middleware between different Graph Database implementations. It basically lets you operate on Neo4j, OrientDB, Sparksee, and Titan at the same time.
At the moment it supports the above-named Graph Databases, but, it is planned to extend it to support JanusGraph (Titan successor) and maybe others in the future.
Features:
Currently, Fireplug has a bunch of features which we'll be extending over the future.
Graph Database Support:
For each of them, it supports full CRUD (Create, Read, Update, Delete) for the 4 named Graph Databases.

For this reason, I created an interface which sums up the basic functionalities of all graph databases.
One of our future projects is extending this to more graph specific operations like graph algorithms as shortest path, for graph processing which will increase the size of this interface.
Fault tolerance:
Additionally, Fireplug is tolerant to Crash and Byzantine faults (Arbitrary errors and also malicious attacks).
We achieve this by creating a wrapper on top of Bft-Smart, which is a library which implements an atomic broadcast algorithm resilient to these types of failures.
Nevertheless, Fireplug is coded in a manner which allows us to adapt the system to plug-in whichever type of System with the same guarantees easily.
Unfortunately, this kind of fault tolerance usually comes with a high cost of N² messages which, in a high performance, and especially in a geographically replicated environment leads to huge issues.
This is why we implemented a novel hierarchical structure.
Hierarchical Infrastructure.
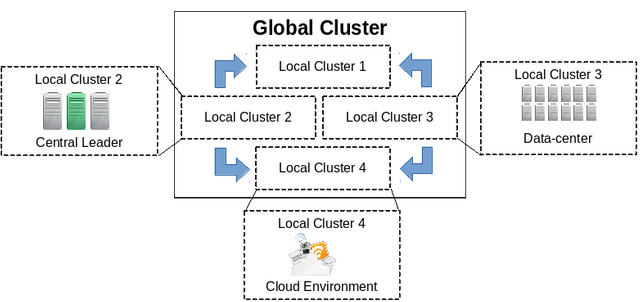
This infrastructure allows us to employ different Database Clusters in a bunch of different setups.
The figure above shows an example setup where we'd have 4 different datacenters in completely different environments, each of these datacenters elects a leader replica which is responsible for the global communication.
Therefore, only 1 of the replicas will have to do the communication and this way we won't require N² messages, we'll only require K² + N messages which is the number of replicas in the global cluster + the replicas they have to distribute their decisions too.
For this setup, we implemented a Wrapper class called ServerWrapper.

Which contains a link to the global consensus algorithm and a link the local consensus algorithm.
In this manner, Fireplug is more decentralized than the more common databases but elects a certain number of replicas to a "council" which allows it to scale better.
Results:
Architecture:
In order to test the performance of this, we ran a whole bunch of experiments, to guarantee correctness and to show the performance advantages we achieved.
The shown results are a bit outdated, but we're currently executing more tests to achieve newer results:
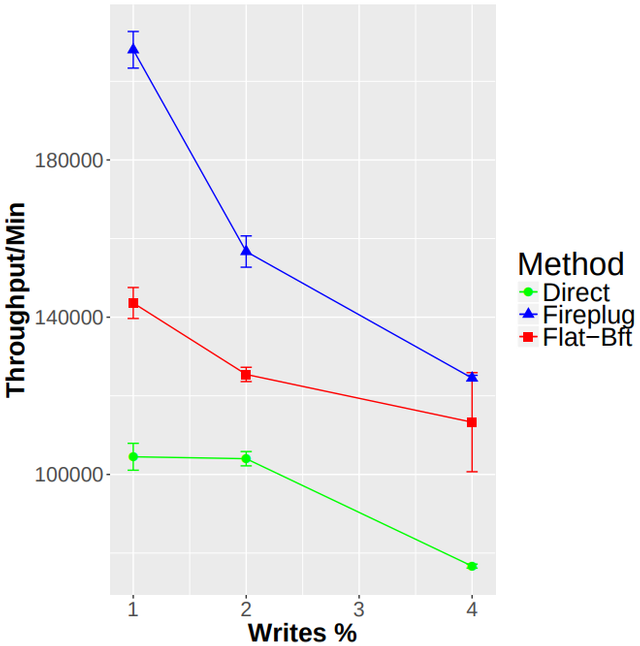
In the first iteration already, considering a latency of 20ms between each datacenter, with 8 replicas, Fireplug outperformed Neo4js native replication system by far and also outperformed a flat alternative until 4% writes (Considering that a typical write percentage lies around 0.2% for graph databases).
With 12 replicas the performance difference has been even bigger.
Reads:
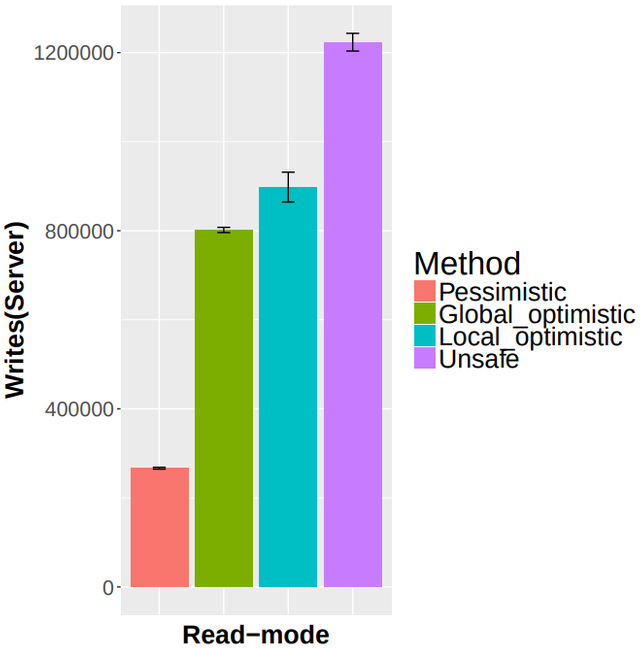
Additionally, Fireplug comes with a selection of read-modes which allows executing different modes depending on the required security level.
N-Version:

Executing Fireplug in a mixed setup also showed a considerable performance in its first iteration where the performance of a mixed setup was just at the performance of the second fastest graph database.
After extending it further, the performance of Sparksee dropped strongly and OrientDb became the number 2.
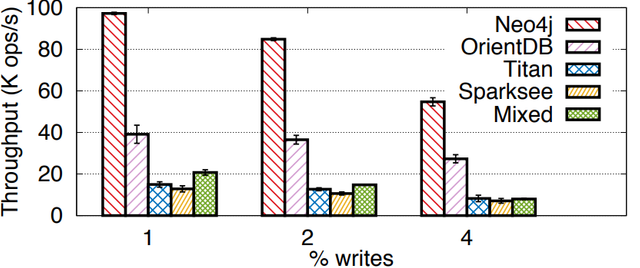
Unfortunately, Sparksee and Titan showed an extremely low performance on this setup which caused the mixed performance to drop badly as well since we had to balance the load strongly to Neo4j and OrientDB since Sparksee and Titan were unable to keep up with the two stronger databases.
Scripts:
We added a bunch of starter scripts to this repository as well as 4 identical example databases of titan, sparksee, orientDB and Neo4j to replicate the results.
The main scripts are:
Utility Scripts:
- Script to kill all processes (Kills all java processes).
killjava
- Script to pull the newest version and compile a new Jar.
compile
- Script to setup latency between the different nodes.
addlatency
- Script to generate the environmental variable and setup the config and latency files.
update_servers.py (Requires python).
Run Scripts:
- Script to run a single server.
runservera
- Script to run the whole architecture.
runarch
- Script to run the clients to access the server.
runarchClient
I hope you liked this small report of this project.
We're currently working strongly on extending this further and have already a bunch of plans for things to add to make it fit for production.
Posted on Utopian.io - Rewarding Open Source Contributors
Thanks for the contribution. It has been approved.
Need help? Write a ticket on https://support.utopian.io.
Chat with us on Discord.
[utopian-moderator]
Hey @raycoms I am @utopian-io. I have just upvoted you!
Achievements
Utopian Witness!
Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x