Machine learning and Steem #2: Multiclass classification (content creator vs scammer vs comment spammer vs bid-bot)
Repository
https://github.com/keras-team/keras
What Will I Learn?
- Collect data from beem and SteemSQL
- Preprocess data to improve classification accuracy
- Visualize features
- Build neural network model for multiclass classification problem
- Measure model performance
- Use different neural network architectures
- Use different neural network optimizers
Requirements
- python
- basic concepts of data analysis / machine learning
Tools:
- python 3
- pandas
- matplotlib
- seaborn
- jupyter notebook
- scikit-learn
- keras + tensorflow (as backend to keras wrapper)
It looks like a lot of libraries, but it's a standard python toolset for data analysis / machine learning.
Difficulty
- Intermediate
Tutorial Contents
- Problem description
- Collecting account list for different classes
- Collecting account features from beem
- Collecting account features from SteemSQL
- Visualization of the dataset
- Preprocessing
- Building model for multiclass classification problem
- Measuring model performance
- Comparing different neural network architectures
- Comparing different neural network optimizers
- Conclusions
Problem description
The purpose of this tutorial is to learn how to build a neural network model for multiclass classification problem.
We will use the following classes:
- content creator
- scammer (an account that writes comments with links to phishing sites)
- comment spammer (an account that spams short with comments such as:
nice,beautiful,upvoted) - bid-bots
Each class will have 100 records.
Collecting account list for different classes
Accounts creating the content will be collected from the SteemSQL database with the following script:
SELECT TOP 100 author
FROM Comments (NOLOCK)
WHERE depth = 0 AND
category in ('utopian-io', 'dtube', 'dlive')
ORDER BY NEWID()
Scammers will be selected from the comments of the user guard, who warns about this type of accounts. For example:

SELECT TOP 100 account
FROM (
SELECT SUBSTRING(body, CHARINDEX('@', body) + 1, CHARINDEX(' leads', body) - CHARINDEX('@', body) - 1) as account, *
FROM Comments (NOLOCK)
WHERE depth > 0 AND
author = 'guard' AND CONTAINS(body, 'phishing')) C
GROUP BY account
ORDER BY COUNT(*) DESC
The users who have written the most comments such as: nice, beautiful, upvoted will be selected as comment spammers:
SELECT TOP 100 author
FROM Comments (NOLOCK)
WHERE depth = 1 AND
created BETWEEN GETUTCDATE() - 90 AND GETUTCDATE() AND
((CONTAINS (body, 'nice') AND body LIKE 'nice') OR
(CONTAINS (body, 'beautiful') AND body LIKE 'beautiful') OR
(CONTAINS (body, 'upvoted') AND body LIKE 'upvoted'))
GROUP BY author
ORDER BY COUNT(*) DESC
The list of bid-bots has been collected manually from https://steembottracker.com/.
Collecting account features from beem
The features to be analysed are:
- followers
- followings
- follow ratio
- muters
- reputation
- effective sp
- own sp
- sp ratio
- curation_rewards
- posting_rewards
- witnesses_voted_for
- posts
- average_post_len
- comments
- average_comment_len
- comments_with_link_ratio
- posts_to_comments_ratio
Some of the features will be collected with the beem script below.
full_list = content_creators + scammers + comment_spammers + bid_bots
d = defaultdict(lambda: defaultdict(int))
for name in full_list:
account = Account(name)
foll = account.get_follow_count()
d[name]['name'] = name
d[name]['followers'] = foll['follower_count']
d[name]['followings'] = foll['following_count']
d[name]['follow ratio'] = foll['following_count'] / foll['follower_count']
d[name]['muters'] = len(account.get_muters())
d[name]['reputation'] = account.get_reputation()
d[name]['effective sp'] = account.get_steem_power()
own_sp = account.get_steem_power(onlyOwnSP=True)
d[name]['own sp'] = own_sp
d[name]['sp ratio'] = account.get_steem_power() / own_sp if own_sp > 0 else 0
Collecting account features from SteemSQL
The remaining features will be downloaded from the SteemSQL database. This will be done with several separate queries, to keep them simple.
The following query will collect features such as:
- curation_rewards
- posting_rewards
- witnesses_voted_for
query = """\
SELECT
name,
curation_rewards,
posting_rewards,
witnesses_voted_for
FROM Accounts (NOLOCK) a
WHERE name in """ + to_sql_list(full_list)
for row in cursor.execute(query):
name = row[0]
curation_rewards = row[1] / 1000.0
posting_rewards = row[2] / 1000.0
witnesses_voted_for = row[3]
d[name]['curation_rewards'] = curation_rewards
d[name]['posting_rewards'] = posting_rewards
d[name]['witnesses_voted_for'] = witnesses_voted_for
The following query will collect features such as:
- posts
- average_post_len
query = """\
SELECT
author,
COUNT(*),
AVG(LEN(body))
FROM Comments (NOLOCK) a
WHERE depth = 0 AND
created BETWEEN GETUTCDATE() - 90 AND GETUTCDATE()
AND author in """ + to_sql_list(full_list) + """
GROUP BY author"""
for row in cursor.execute(query):
name = row[0]
posts = row[1]
average_post_len = row[2]
d[name]['posts'] = posts
d[name]['average_post_len'] = average_post_len
The last query will collect features such as:
- comments
- average_comment_len
- comments_with_link_ratio
- posts_to_comments_ratio
query="""\
SELECT
author,
COUNT(*),
AVG(LEN(body)),
CAST(SUM(CASE WHEN body LIKE '%http%' THEN 1 ELSE 0 END) as DECIMAL(10, 3)) / COUNT(*)
FROM Comments (NOLOCK) a
WHERE depth > 0 AND
created BETWEEN GETUTCDATE() - 90 AND GETUTCDATE()
AND author in """ + to_sql_list(full_list) + """
GROUP BY author
"""
for row in cursor.execute(query):
name = row[0]
comments = row[1]
average_comment_len = row[2]
comments_with_link_ratio = row[3]
d[name]['comments'] = comments
d[name]['average_comment_len'] = average_comment_len
d[name]['comments_with_link_ratio'] = comments_with_link_ratio
d[name]['posts_to_comments_ratio'] = d[name]['posts'] / comments if comments > 0 else 0
You also need to add the appropriate class, depending on which set the account belongs to.
def to_class(name):
if name in content_creators:
return 0
elif name in scammers:
return 1
elif name in comment_spammers:
return 2
else:
return 3
for name in full_list:
d[name]['class'] = to_class(name)
All data will be saved as file data.csv.
columns = ['name', 'followers', 'followings', 'follow ratio', 'muters',
'reputation', 'effective sp', 'own sp', 'sp ratio', 'curation_rewards',
'posting_rewards', 'witnesses_voted_for', 'posts', 'average_post_len', 'comments',
'average_comment_len', 'comments_with_link_ratio', 'posts_to_comments_ratio', 'class']
with open ('data.csv' , 'w') as f:
f.write(','.join(columns) + '\n')
for name in full_list:
row = [d[name][column] for column in columns]
f.write(','.join(map(str, row)) + '\n')
Visualization of the dataset
The dataset is loaded with the following command.
df = pd.read_csv('data.csv', index_col=None, sep=",")
It looks as follows:
name followers followings follow ratio muters reputation effective sp own sp sp ratio curation_rewards posting_rewards witnesses_voted_for posts average_post_len comments average_comment_len comments_with_link_ratio posts_to_comments_ratio class
0 alucare 556 119 0.214029 1 58.640845 4.417161e+02 441.716135 1.000000 21.275 433.544 4 111 630 387 97 0.074935 0.286822 0
1 ayufitri 644 318 0.493789 4 46.679335 1.503135e+01 8.926123 1.683973 0.037 17.479 30 301 1016 717 125 0.054393 0.419805 0
2 imh3ll 87 26 0.298851 0 53.589527 5.795137e-01 67.930278 0.008531 0.545 132.534 0 0 0 2 24 0.000000 0.000000 0
3 andeladenaro 205 75 0.365854 0 56.414916 9.938178e+01 99.381785 1.000000 0.158 195.882 1 0 0 0 0 0.000000 0.000000 0
4 shenoy 1225 1576 1.286531 3 65.416593 2.577685e+03 2063.983517 1.248888 46.552 2581.548 0 88 568 41 34 0.048780 2.146341 0
5 tidylive 542 70 0.129151 2 64.583380 8.252583e+02 825.258289 1.000000 18.131 1891.259 1 88 496 61 99 0.245902 1.442623 0
6 arpita182 26 0 0.000000 0 27.253055 1.505696e+01 0.173166 86.950855 0.000 0.143 0 0 0 0 0 0.000000 0.000000 0
7 world-of-music 45 1 0.022222 5 15.326558 5.008056e+00 0.100673 49.745673 0.000 0.000 0 0 0 0 0 0.000000 0.000000 0
8 mirnasahara 1145 2038 1.779913 2 47.750057 1.563195e+01 15.631949 1.000000 0.128 29.303 0 46 74 12 29 0.000000 3.833333 0
9 haveaniceday 57 2 0.035088 0 42.550673 8.587180e-01 0.858718 1.000000 0.000 2.137 0 0 0 0 0 0.000000 0.000000 0
10 blackhypnotik 513 70 0.136452 4 61.570600 4.559381e+02 455.938075 1.000000 5.423 893.037 1 189 955 70 372 0.671429 2.700000 0
11 openingiszwagra 207 42 0.202899 0 25.000000 1.505430e+01 0.100362 149.999441 0.001 0.000 0 47 395 7 28 0.000000 6.714286 0
12 swelker101 1610 131 0.081366 13 63.245558 1.681717e+03 5831.538042 0.288383 61.037 1845.328 26 45 731 52 106 0.057692 0.865385 0
13 phoneinf 1032 19 0.018411 14 65.778281 6.021037e+03 2418.063434 2.490024 50.373 1789.770 7 451 659 1573 184 0.052765 0.286713 0
14 spawn09 989 93 0.094034 6 62.882242 1.253178e+02 125.317849 1.000000 10.626 1736.275 0 240 598 65 32 0.015385 3.692308 0
15 dschense 112 34 0.303571 1 28.768973 5.017238e+00 0.637683 7.867919 0.012 0.233 0 0 0 0 0 0.000000 0.000000 0
16 brainpod 310 187 0.603226 0 53.062904 3.407024e+01 34.070244 1.000000 0.047 77.218 2 44 1219 64 123 0.031250 0.687500 0
17 jezieshasan 350 216 0.617143 1 42.953291 6.709893e+00 5.705882 1.175961 0.447 12.838 0 0 0 0 0 0.000000 0.000000 0
18 hmagellan 453 169 0.373068 0 45.283351 1.004239e+01 689.153713 0.014572 0.596 30.575 0 0 0 3 224 0.000000 0.000000 0
19 marishkamoon 191 1 0.005236 0 35.302759 1.326083e+01 13.260832 1.000000 0.000 1.042 0 24 311 0 0 0.000000 0.000000 0
20 xee-shan 198 8 0.040404 0 52.254091 3.666877e+01 36.668770 1.000000 0.076 72.899 0 27 1516 3 44 0.000000 9.000000 0
21 marcmichael 300 78 0.260000 2 39.739864 1.504864e+01 1.925210 7.816625 0.001 2.900 0 80 769 2 91 0.000000 40.000000 0
22 ridvanunver 425 53 0.124706 0 57.346462 1.128660e+02 112.865950 1.000000 0.211 265.501 1 86 927 16 62 0.062500 5.375000 0
23 cheaky 1131 48 0.042440 0 66.096330 1.512192e+03 1512.191914 1.000000 65.840 3511.447 2 71 309 30 27 0.000000 2.366667 0
24 dbroze 2385 76 0.031866 10 66.849140 2.073023e+03 2073.022665 1.000000 56.955 3972.949 0 60 2492 4 88 0.250000 15.000000 0
25 jarendesta 1911 55 0.028781 6 70.460557 1.206929e+04 12069.286644 1.000000 235.837 9692.369 0 101 1771 91 68 0.000000 1.109890 0
26 bitcoinmarketss 628 606 0.964968 3 -1.445307 1.412191e+01 0.646501 21.843597 0.007 0.078 3 2 137 1 9 0.000000 2.000000 0
27 revehs 180 0 0.000000 0 25.000000 1.505181e+01 0.109308 137.700692 0.000 0.017 0 33 531 0 0 0.000000 0.000000 0
28 skyshine 504 847 1.680556 0 52.665926 4.753474e+01 47.534744 1.000000 0.118 94.111 1 38 296 4 29 0.000000 9.500000 0
29 adamkokesh 14144 8882 0.627969 100 73.792439 5.002053e+05 5791.887941 86.363087 4782.833 22908.451 0 127 2114 23 122 0.043478 5.521739 0
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
Let's first look at the dataset. We can expect for example that:
- scammers and comment spammers have low reputation
- scammers and comment spammers add a lot of comments
- most of the comments from scammers have link to some site
- bid-bots have the highest effective STEEM POWER
- bid-bots have most of the STEEM POWER from delegation
- bid-bots observe fewer users
You can also add many more options here. Now let's look at the average values of the features of each class.
| Feature | content-creator average | scammer average | comment-spammer average | bid-bot average |
|---|---|---|---|---|
| followers | 1056.673 | 340.810 | 577.545 | 2328.080 |
| followings | 535.990 | 382.760 | 456.354 | 1753.760 |
| follow ratio | 0.448 | 0.764 | 0.757 | 0.420 |
| muters | 5.673 | 5.520 | 2.303 | 14.820 |
| reputation | 49.285 | 13.538 | 41.884 | 45.506 |
| effective sp | 5353.143 | 104.365 | 226.147 | 214445.739 |
| own sp | 731.946 | 96.332 | 1224.500 | 12243.641 |
| sp ratio | 33167243.073 | 22.164 | 28.494 | 121.184 |
| curation_rewards | 155.473 | 2.196 | 13.305 | 4703.424 |
| posting_rewards | 1800.861 | 78.733 | 149.129 | 938.840 |
| witnesses_voted_for | 4.020 | 3.540 | 3.010 | 2.270 |
| posts | 55.980 | 20.540 | 64.677 | 15.620 |
| average_post_len | 876.465 | 961.980 | 939.040 | 1930.990 |
| comments | 101.495 | 121.200 | 360.596 | 3390.350 |
| average_comment_len | 71.990 | 67.580 | 27.818 | 408.540 |
| comments_with_link_ratio | 0.045 | 0.179 | 0.025 | 0.481 |
| posts_to_comments_ratio | 3.395 | 2.692 | 0.307 | 0.159 |
We can see great differences in average values here. However, this is not enough. Let's look also at some charts.
followers + followings:

muters + rep:

follow ratio + sp ratio:

curation rewards + posting rewards:

posts + comments:
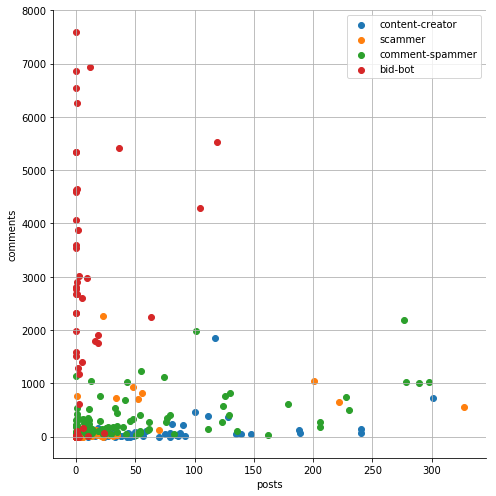
average_post_len + average_comment_len:

comments_with_link_ratio + posts_to_comments_ratio:

This gives us a much better picture of the situation. It is very important to have a good understanding of our data
Preprocessing
Preprocessing is a process of data preparation so that it is more valuable for the model being built. We will use QuantileTransformer.
X_cols = columns
y_cols = ['class']
X = pd.DataFrame(QuantileTransformer().fit_transform(df[X_cols]))
y = to_categorical(df[y_cols])
What is the difference between raw and preprocessed data is shown in the charts below.
| Raw data | StandardScaler | QuantileTransformer |
|---|---|---|
|  |  |
StandardScalerstandardizes features by removing the mean and scaling to unit variance.QuantileTransformermakes the data not only in the range of [0,1] but also evenly distributed throughout the area.
For the neural network, the best input is standardized to the range of [0, 1].
Building model for multiclass classification problem
The code building the neural network model is relatively simple. There are only two layers:
- input layer with 17 neurons
- output layer with 4 neurons
- (there is no hidden layer at the moment)
model = Sequential()
model.add(Dense(17, input_dim=17, activation='relu'))
model.add(Dense(4, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, y_train,epochs=40, batch_size=1, verbose=0)
score = model.evaluate(X_test, y_test,verbose=0)
y_pred = model.predict_classes(X_test)
A short glossary:
| Name | Description |
|---|---|
| model.add | adds new layer |
| Dense | fully connected layer |
| relu | ReLU activation function |
| sigmoid | sigmoid activation function |
| categorical_crossentropy | loss used for multiclass classification problem |
| adam | Adaptive Moment Estimation optimizer, basically RMSProp with momentum |
| accuracy | percentage of correctly classified inputs |
Measuring model performance
After training the neural network on the training set, we want to check its effectiveness on the test set. To do this, you will display the accuracy and the confusions matrix, which counts the records assigned to the given class.
print('accuracy: %.2f' % score[1])
cm = confusion_matrix(np.argmax(y_test, axis=1), y_pred)
plot_confusion_matrix(cm)
accuracy: 0.81

The obtained accuracy is 81 %. It is acceptable, but it could have been better.
Comparing different neural network architectures
We will now try to build a larger neural network. We will increase the number of neurons in the first layer and add two hidden layers.
model = Sequential()
model.add(Dense(85, input_dim=17, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(4, activation='softmax'))
accuracy: 0.83

Accuracy is slightly better, but it is not a big difference.
Comparing different neural network optimizers
We will try to use other optimizers. The optimizer is an algorithm for updating neural network weights during the learning process.
for optimizer in ['sgd', 'rmsprop', 'adagrad', 'adadelta', 'adam', 'adamax', 'nadam']:
model = Sequential()
model.add(Dense(85, input_dim=17, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(4, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
model.fit(X_train, y_train,epochs=40, batch_size=1, verbose=0)
score = model.evaluate(X_test, y_test,verbose=0)
y_pred = model.predict_classes(X_test)
cm = confusion_matrix(np.argmax(y_test, axis=1), y_pred)
plot_confusion_matrix(cm)
print('%s|accuracy: %.2f' % (optimizer, score[1]))
| Optimizer | Accuracy | Confusion matrix |
|---|---|---|
| sgd | 0.82 |  |
| rmsprop | 0.78 |  |
| adagrad | 0.80 |  |
| adadelta | 0.80 | 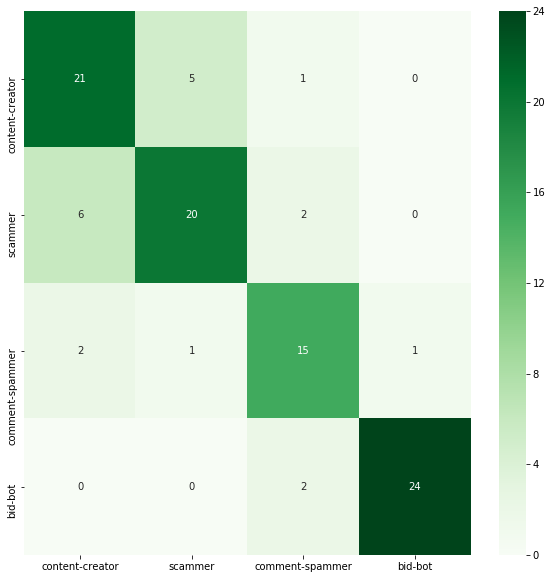 |
| adam | 0.80 |  |
| adamax | 0.81 |  |
| nadam | 0.81 |  |
The results are almost the same as for the Adam optimizer used earlier. In my opinion, changing the neural network itself will not help much here. In order to increase accuracy, a much larger data would need to be collected and possibly new attributes would need to be added.
Curriculum
Conclusions
- the bigger the dataset, the better we can train the neural network
- we should have a good understanding of our data
- preprocessing can make a huge difference
- building the optimal neural network model requires experimenting
- it is worth to experiment with different architecture of the neural network / different optimizers
Nicely written. I have been teaching myself neural networks and have only reached till ADALINE, have not yet covered Adam. They also did not tell us in the book that pre processing is needed. It might be helpful though to show your weight matrix, which should be 4 columns and 17 rows? Also is there a good guide for ADALINE? I solved it with hand and cannot seem to match the weights. They do not seem to converge.
Hey @hispeedimagins
Here's a tip for your valuable feedback! @Utopian-io loves and incentivises informative comments.
Contributing on Utopian
Learn how to contribute on our website.
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Thank you for your contribution.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
Hey @jacekw.dev
Thanks for contributing on Utopian.
Congratulations! Your contribution was Staff Picked to receive a maximum vote for the tutorials category on Utopian for being of significant value to the project and the open source community.
We’re already looking forward to your next contribution!
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Cool stuff! :-)
Congratulations @jacekw.dev! You have completed the following achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPExcelent post, I want your permission to translate this to spanish and share in my blog, the information that are you sharing is very valuable!
Thanks @jacekw.dev