Block chain is fundamentally and irreversibly changing intellectual property and online privacy
In this essay, I look at two aspects of the block chain: (i) the practical impact of block chain permanence on content that is illegal and/or universally undesirable; and (ii) the possibility of automated block chain incentivisation for the public disclosure of private information.
 Image source: pixabay.com, License: CC0, Public Domain
Image source: pixabay.com, License: CC0, Public Domain
Image source: pixabay.com, License: CC0, Public DomainIntroduction
Something I have thought about
is the complex relationship that exists among block chain, intellectual property protection, and illicit content like: slanderous or libelous content, child porn or non-consensual adult porn.
This line of thought was recently reignited when I read the article, Can a Blockchain-powered Search Engine Take On a Leviathan Like Google?, about a start-up called Presearch that intends to launch a block chain powered decentralized search mechanism. This excerpt of the article especially caught my attention:
As the Presearch whitepaper states, “We are exploring a model that will enable Members running a Presearch browser extension (and potentially a standalone browser) to act as web crawling and indexing nodes that would build the Presearch index as they surf the web. This would enable Presearch to get around one of the most difficult crawling challenges; getting blocked by webmasters. Members running nodes will earn PRE Tokens in exchange for utilizing their computers and internet connections for Presearch.”
I intend to go back and read the whitepaper, but haven't done so yet. However, if I'm understanding right, what that means is that they would pay people in cryptocurrency to perform reconnaissance inside the walled gardens that are hidden from traditional search engines by privacy protections. This might include, for example, non-public posts in your facebook feed or subscription-based e-books that you read in your browser.
I shared the link on facebook, along with that quote, and the remark that: "someone's not going to like this."
In the remainder of this essay, I'll summarize some recent thoughts triggered by this article. The essay will examine two aspects of block chain: (i) practical impact of block chain permanence on content that is illegal, like copyrighted works, and/or universally undesirable like child porn and other videos of non-consensual exploitation; and (ii) the possibility of incentivising and automating the release of non-public information.

 Image Source: pixabay.com, License: CC0, Public Domain
Image Source: pixabay.com, License: CC0, Public Domain
Image Source: pixabay.com, License: CC0, Public DomainBlock Chain Permanence
The block chain
is designed to be permanent and censorship resistant for good --- reason, but there are also cases where the block chain's permanence is less desirable.
Personally, I am conflicted about the economic and social desirability of legal protections for intellectual property. All I know is (a) that it's a complicated question and I haven't studied it enough to have a strong opinion on the matter; and (b) in the world where we live, those legal protections exist, so ignoring them is imprudent. So let's look at the interaction of copyright and the block chain...
What if, for example, a person were to use the Tor network and @social's private posting key - which is published right on its profile page - to publish the contents of a best selling book, page by page? What if they created their own anonymous account and did the same thing?
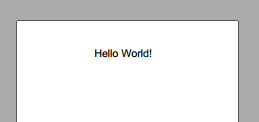
Image Source: screen grab
Image Source: screen grab
Maybe even in PDF format?
%PDF-1.4
1 0 obj <</Type /Catalog /Pages 2 0 R>>
endobj
2 0 obj <</Type /Pages /Kids [3 0 R] /Count 1>>
endobj
3 0 obj<</Type /Page /Parent 2 0 R /Resources 4 0 R /MediaBox [0 0 500 800] /Contents 6 0 R>>
endobj
4 0 obj<</Font <</F1 5 0 R>>>>
endobj
5 0 obj<</Type /Font /Subtype /Type1 /BaseFont /Helvetica>>
endobj
6 0 obj
<</Length 44>>
stream
BT /F1 24 Tf 175 720 Td (Hello World!)Tj ET
endstream
endobj
xref
0 7
0000000000 65535 f
0000000009 00000 n
0000000056 00000 n
0000000111 00000 n
0000000212 00000 n
0000000250 00000 n
0000000317 00000 n
trailer <</Size 7/Root 1 0 R>>
startxref
406
%%EOF
This capability isn't unique to steemit. That's just an example. A similar capability is available in the Bitcoin block chain. I believe that IPFS may have similar capabilities for permanence with video that's protected by copyright or contains other undesirable attributes. I imagine that most, if not all, block chains have this potential.
So in the example of steemit, @steemcleaners would flag the posts to oblivion, the publisher would send Steemit, Inc a take down notice, and they'd filter it from their web site. Someone else might just take the @social key and delete the post or edit it to be blank. But... the contents are still there on the block chain. Now, who does the publisher go after? Well, maybe someone will make a slip, and the publisher will find and prosecute the person who actually published it, but still the block chain continues to exist. What next?
In Steem's case, I imagine that the publisher starts going after witnesses. Let's say they succeed. All that does is replace the top-20 witnesses with another 20. Eventually, maybe the witnesses in one country are deterred, but the rest of the world continues on and the content still exists.
In the case of IPFS, if I understand correctly, the files are fragmented so that no particular computer is holding an entire file, so the ability to identify a hosting computer basically doesn't exist. They'd have to go after viewers one at a time.
Anti-IP activists may love it (although I suspect that almost everyone has some limit as to what private information should be available in the public domain) but copyright holders, victims of slander, libel, and non-consensual video postings aren't so thrilled. As far as I can tell, though, it cannot be stopped. Once Pandora's box has been opened, it can't be closed again.

 Image Source: pixabay.com, License: CC0, Public Domain
Image Source: pixabay.com, License: CC0, Public Domain
Image Source: pixabay.com, License: CC0, Public DomainIncentivising and automating the publication of private information
As I said,
this latest round of thought was prompted by an article about Presearch. In a sense, there is nothing actually new about this idea.
- Decentralized, peer to peer search has existed for years, for example: here and here. Last time I test drove a couple sites they weren't great, though. That was a couple years ago, so I assume they've improved.
- Software that harvests hidden information from the browser has existed for years.
- Cryptocurrency has existed for years.
This is just the next logical extension of those capabilities. What's new is just the combination of the three. Now, a distributed search engine is proposing to pay people for information that is published to them, privately. Presumably, the distributed search engine will then make that information available to the public in some fashion or other.
For better or worse, in principle, the capability for the public to search any information that's ever presented to anyone's browser is now possible. Among others, this includes private e-mails, social media feeds, discussion groups, and subscription-only publications.
As with the above example, if some of this information is illegal or otherwise undesirable, there really isn't a feasible way for the aggrieved party to shut it down. Even if Presearch does not implement this capability, it's probably only a matter of time until someone else does.
 Image Source: pixabay.com, License: CC0, Public Domain
Image Source: pixabay.com, License: CC0, Public Domain
Image Source: pixabay.com, License: CC0, Public DomainConclusion
In this essay,
I am just thinking out loud. Most of what I wrote had to do with copyright, but what's true of copyright is also true of many forms of undesirable content. I hope and believe that the benefits of censorship resistance probably outweigh the harms of permanence. But in the end, it really doesn't matter. Like it or not, the world is changing in a fundamental and probably irreversible way, and as with all changes, there will be winners and losers.
I don't remember where I read it, but back in the 1990s, I remember reading the advice that we should never put anything on the Internet, or even in e-mail, that we don't want our mothers to see on the front page of the NY Times. Today, that advice rings even more true.
As a general rule, I up-vote comments that demonstrate "proof of reading".
Thank you for your time and attention.

Great post, responding to it has been on my todo list.
I think I experience a lot of the same conflicts as you do with regards your thoughts on IP. I actually began here almost exactly one year ago intending to first speak on these kinds of issues. My own conflict is that I don't believe you can own an idea, or a methodology but I do believe however that storing information about people is potentially dangerous for the people the data is about, to the point where I think the legal structure should recognize all data about people to be owned by them automatically.
However in the last year I have moved away from favoring strong legal protections of data towards favoring strong technological protections of data. I've been chasing a phantom idea where it would be possible to store and share data and give temporary access of it to people or organizations but without opening pandoras box forever by doing so. I'm still trying to crack that nut.
It's gets even more murky when you start thinking about patents. I would make a greater distinction though between commercial information which can be IP, patents, etc. and private persons personal information. The protections for "privacy" are generally for the later. However I believe many laws do not make this distinction clearly enough.
In any case something what I propose is needed and I potential solutions in blockchain tech, mainly the idea of trustlessness and encryption, perhaps using zero knowledge proofs too (this might turn out to be crucial). The point is that no government can take your crypto unless they beat your keys out of you. We use very strongly locked technology for something that needs very strong protection.
I'm definitely on board with strong technical protections for data. It would be nice if we didn't have to care about IP law, because the technology enforced a more rational design. Architecturally, though, something like Presearch is basically built like a man in the middle attack. It's hard for me to imagine a way to deliver information to an end-user without a browser being able to intercept it (aside from ditching the browser). On the other hand, I guess Brave made a start in the right direction with their zero knowledge proofs and anonymous payments to web sites. Maybe there is a way to accomplish that level of privacy. Something like, "I'm not going to transfer the data to the browser, but if you pay me for it and put up an encrypted tunnel, I'll display it in field <SSN> for 30 seconds." or "I'll let you verify it against a hash." If it can be done, I think you're right, it will involve zero knowledge proofs and also expiring smart contracts.
I keep thinking back to The Local-Global Flip, or, "The Lanier Effect": A Conversation with Jaron Lanier [8.29.11]. He talked about how the capability to copy things on the Internet muddies up the sources of information in a way that you need predatory intermediaries to restore order. Enter the block chain, and that problem is solved, but new ones arise.
Right. However I suppose the issue is that government don't look too kindly on locked boxes that even their agents can't unlock. So the systems can be in opposition. Or in other words, do it yourself! Don't expect the laws to protect your data. This is why I take precautions personally but it's tedious and not for everyone.
I'm sorry, I didn't comment on the matter at hand, the MiTM attacks that seem to be the main information source for Presearch. Maybe that's what the "pre" stands for? Before firewalls 😭 I agree with you, this seems very unethical.
However I did a little digging and I think I know what they're trying to get around. Webmasters seem to want to ban (or nicely ask) search crawlers away from their sites in order to reduce traffic and likely reduce bandwidth costs. It's not a million miles away from the bot debate here, they want to server really human people over bots. Now it is of course in their interests to allow the almighty Google access so forums seem to be dominated by ways to ban all other indie and "foreign" engines.
I think this is what Presearch intend to bypass, content which is behind firewalls. I read their whitepaper and the paragraph you quoted is the only one which touches on this. Given that they are very clear that the project will be community led I doubt very much that no one will raise your interpretation as a red flag, especially considering the types who would be attracted to the project, so I think the concern, while founded, is unlikely to come to pass. Consider also that they will have to come up with an extremely robust way to prevent the leaking of personal information from sites, pages behind account access and even paywalls (if they are respected, again I think this will be debated).
Another note having read the whitepaper. It's more of a business plan than a whitepaper, there are no technical details at all. They kind of touch on the token sale aspect but it's all vision, ecosystem graphs and selling points. The abuse section is just a short passage on their aspirations! So there's not much to go on and judge here. As details emerge it will be interesting what the conversation will be because it's a great idea.
Thanks for the rundown! I will try to make time for the whitepaper this week-end. I really do like the idea of a decentralized search with cryptocurrency payouts to the people who hold the search index and/or answer the queries, and I can definitely see the potential usefulness of collecting search data in the browser for public sites that ban crawlers, so I think you're right, it should be interesting to see it emerge.
One of the downsides of blockchain technology is that it could enable a dystopian society (think Black Mirror). I think you are accurate in saying that Panadora's box is open so we must learn how to deal with it.
I guess most technologies amplify both the good and the bad traits of humanity and the best we can hope for is to find ways to maximize the good and minimize the bad. I hadn't heard of Black Mirror, but it sounds interesting. Thanks for bringing it to my attention.
This is extremely insightful and deserves more attention. This post has been deemed resteem & upvote worthy by your friendly @eastcoaststeem ran by @chelsea88 (not a bot)
Thank you again for the resteem.