UC Berkeley Robotics and Engineering Laboratory Professor Wang Qiang: Deep Learning and AlphaGo Zero (part) | Share Summary
In the early morning of October 19, Beijing time, DeepMind published the paper "Mastering the game of Go without human knowledge" in Nature, in which DeepMind showed them More powerful new version Go program "AlphaGo Zero", set off a big discussion of AI. And on October 28, Geoffrey Hinton published the latest capsule essay, completely overthrow the algorithm he has adhered to for thirty years, and once again set off a big discussion in the academic circle.
What is artificial intelligence? What is the history of deep learning? Recently, Lei Feng Wang AI Science and Technology Review invited UC Berkeley Robotic and Engineering Laboratory Professor Professor Wang Qiang, he explained in layman's language what is artificial intelligence, the depth of learning development process, how to perceive from the machine to the cognitive evolution of the machine, and analysis AlphaGo and AlphaGo Zero principle, learning process, differences and so on.
Guest Profile: Dr. Wang Qiang, graduated from Xi'an Jiao Tong University with a major in Computer Science and Technology. He obtained a master's degree in software engineering from Carnegie Mellon University and a doctorate degree in robotics. Member of the Audit Panel of the United States Monetary Authority (OCC), Member of the IBM Institute for Business Value, and Research Fellow, Thomas J. Watson, New York. IEEE senior member, and served as CVPR dissertation judges in 2008, 2009, 2013 and the future 2018, and is the editorial board member of two world's top journals, PAMI and TIP. Dr. Wang Qiang has published more than 90 papers in the top journals in the world and many times have contributed papers to conferences such as ICCV and CVPR. Its main research areas of image understanding, machine learning, intelligent trading, financial fraud and risk forecasting.
The following is his share, this article is the second, the main content is AlphaGo and AlphaGo Zero detailed explanation. For more information, please visit: UC Berkeley Robotics and Engineering Lab Professor Wang Qiang: Deep Learning and AlphaGo Zero (Part 1) |
On September 19 this year, DeepMind published a paper on Nature that was disruptive in AI and in-depth learning.
As we all know, AlphaGo, now out AlphaGo Zero, AlphaGo and AlphaGo Zero in the end what kind of difference between.
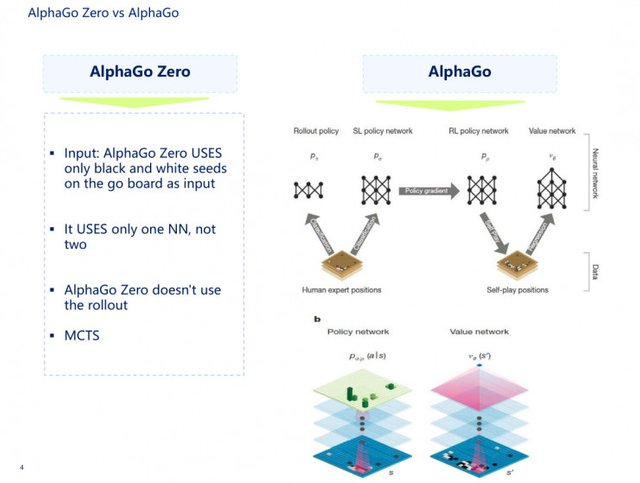
Let me first say AlphaGo, AlphaGo is actually composed of two networks, the first is the human experience, the second is the hands of each stroke, self-learning. The first part is the supervisory strategy network, the second part is the enhanced strategy network, there is a value network, coupled with the rollout network, that is a fast go chess network, these four networks together with MCTS, to form AlphaGo.
There are nearly 48 rules entered into AlphaGo, but in AlphaGo Zero, the input to the neural network is only sunspots and white, and the input is a network, not two networks. The two networks mentioned here refer to the value network and the strategy network. AlphaGo and AlphaGo Zero have used MCTS in common.
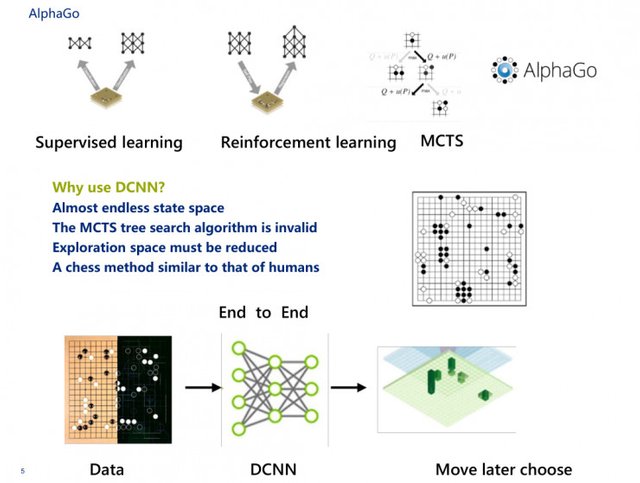
Here is a question, why AlphaGo and AlphaGo Zero will use the DCNN neural network.
First, we all know that it is more interesting to solve the Go problem. Go is the possibility of 19 grids and 19 × 19,361. At this moment, the vector space that may exist is 361 times N, the state space of this vector Almost endless, probably the calculation of the power of 171 is 10, 100 million GPU to 100 years of operation is also endless.
Second, here MCTS search method is invalid. MCTS search here I explain the popular under, take an apple at random, compared with the next apple and found which apple is larger, I will throw away the small apple, and then take this big and random take The next apple to compare. In contrast to the end, I will pick one of the largest apple.
The third is that we want to go when the chess exploration space must be reduced, depending on the child after the fall of another child, there are several possibilities, not to say that someone else has 360 after a sub-space space, which 360 space There is a possibility inside. DeepMind more powerful place is to do a random process, not to say that in the more than 300 selected which is the best, this computer can not figure out.
The fourth question, it must be done similar to a human chess method. So just a friend asked what is end-to-end inside the AlphaGo performance is very clear. I threw the data into the neural network, and then the neural network gave me a state right away. There are two states, including the current state and the current state value, which is very effective, indicating where the stone belongs and how much the probability of winning .
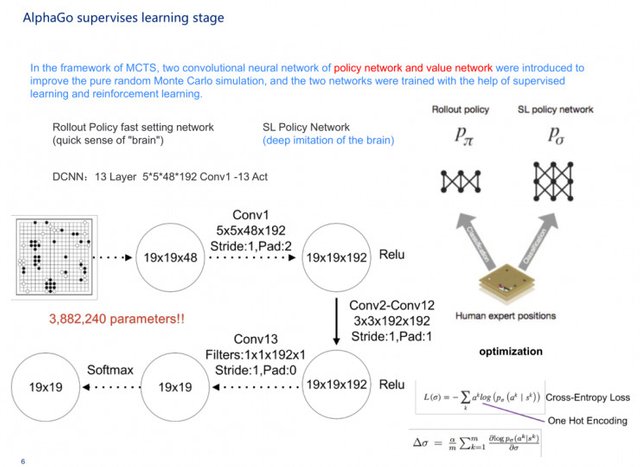
Here I will give you a talk about the principle of AlphaGo. The general chessboard such as go, chess, we first do one thing first, the state vector of the board labeled s, chess board is 19 * 19, which has a total of 361 intersections, each intersection of three State, 1 for sunspots, -1 for white, 0 for no children, and taking into account that there may be times for each position, etc. We can use the 361 times N-dimensional vector to represent the state of the board.
We change the state vector of the board to s, starting from 0, all states of the board represented by s0 have no children, s1 falling is the first child, s2 is the second child, and the second step is adding the child state a , In the current state s, we temporarily do not consider the situation can not be landed. Under the first child, the space available for the next step is 361, and we move the next step into a 361-dimensional vector that becomes a. The third step we design a Go artificial intelligence program, given s state, and then find the best strategy a, so that the program in accordance with this strategy to go. There are four conditions, first state of the board, looking for the best strategy for playing a, and then let the program follow this strategy a walk the chessboard to get the largest site, which is the basic principles and ideas of Go artificial intelligence program.
DeepMind and we did before Watson, the main process is as follows:
The first step is to find a training sample, and then observe the game, we find that in each state s there will be a drop of a, then this time there will be a natural training sample.
In the second step, we made a network and took a sample of 30 million. We took s as a 19 × 19 two-dimensional image and then multiplied by N. N refers to the various win-win features of 48 kinds of Go , A vector of a continuous training network, so that we have a simulated human next Go neural network.
In the third step, we design a strategy function and a probability distribution. We get a strategy that simulates human players and the state of a game. We can calculate the probable probability that human players may be on the board. The probability of each step is the highest Of the fall, the other pair after the re-count again and again to iterate, that is a similar human go Go program, which is the beginning of the design thinking and methods, strategy functions and probability distribution.
In fact, DeepMind is not yet very satisfied with the design of the neural network, they can and strokes around six, each other, but still under the previous made from Watson in a computer program. At this time, DeepMind combined their function with the function algorithm of the program derived from Watson, and made a complete and detailed revision of the original algorithm.
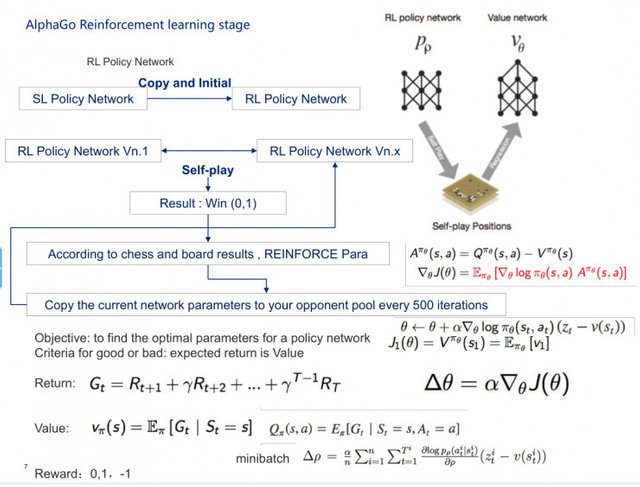
DeepMind did not know Go at all initially. Assume all the points of the game. Let's keep in mind that when doing any scientific research, you must first set a value when you discover that you know nothing. Value must not be zero. And then the second part is simple, just like throwing a dice, choose a randomly from 361 ways, the first sub-a0, then the state of the board by s0 into s1, the other step one step further, this time on the board state Become s2, these two people have come to the state sN, N may be 360, perhaps 361, and finally be able to get the winner, the computer won the R value of 1.
From s0, a0 began to simulate again, then the PPT as shown in the convolution, the activation function. After the next 100,000 sessions, AlphaGo got a very complete rambling solution this time, for example, the probability of the first child falling is greater.
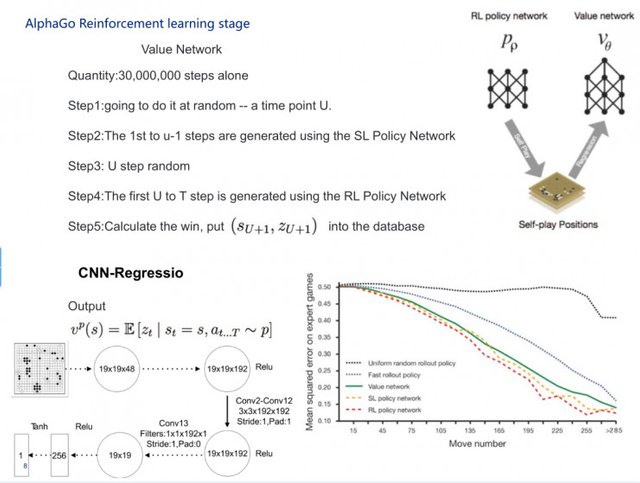
What is the role of MCTS here? MCTS can ensure that the computer can continue to think about countermeasures, in the process of comparison found the best way. After that, DeepMind found that using MCTS was not very good, and they started to design a more interesting thing, that is, the evaluation function, and I will not talk too much about the evaluation function here.
AlphaGo's supervised learning process is actually composed of two networks, one is learned from the experience of others, first made a softmax, that is, fast drop sub, its neural network is relatively narrow, the second part is a deep supervised neural network.
When it comes to intensive learning, it will copy the supervised neural network originally learned from the machine to the enhanced neural network, and then initialize it to let the enhanced neural network as an opponent and another enhanced neural network to learn from each other to select one of the most Excellent result. As the PPT shows, the iteration is done 500 times, and some gradient down will be used here.
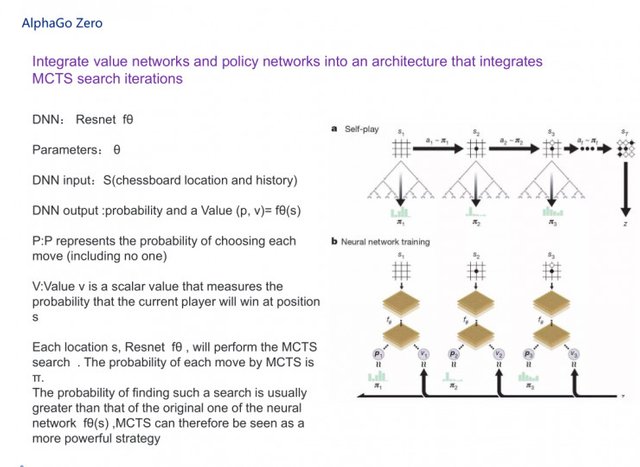
AlphaGo, which we saw earlier, followed by AlphaGo Zero, is a complete simplification of the original process. It integrates value and strategy networks into a single architecture that puts MCTS and two neural networks in one piece. The two neural networks actually use a more interesting neural network, called Resnet, the depth of Resnet We all know that there have been 151 layers, I will not speak here in particular detail. As the PPT shows, its parameter is θ, the input to the deep neural network is s, and the output ram probability (p, v).
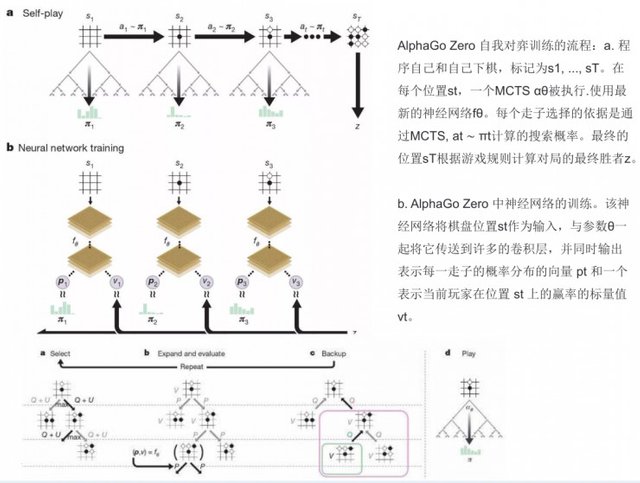
Here I will give you a general talk about AlphaGo Zero self-game training process.
The first step is to play the game yourself and yourself, labeled s1, ..., sT. At each position st, one MCTS αθ is executed. The basis for choosing each runner is the search probability computed by MCTS (choosing the best θ parameter), at ~ πt. The final position sT calculates the final winner of the match according to the rules of the game.
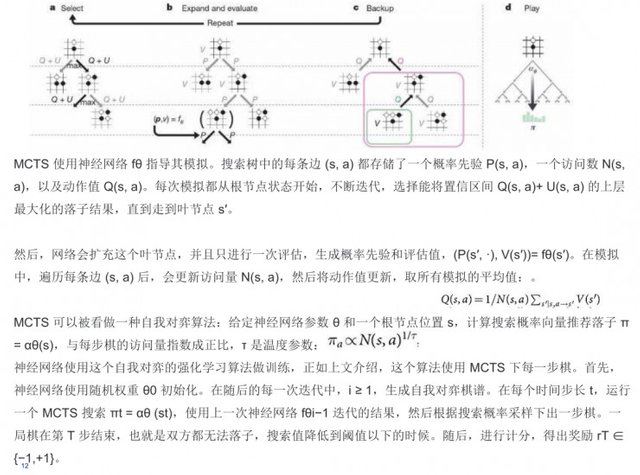
The second step is the training of the neural network in AlphaGo Zero. The neural network takes the position of the checkerboard st as an input and sends it along with the parameter θ to many of the convolution layers and at the same time outputs a vector pt representing the probability distribution of each move and a probability p representing the current player's win at position st The scalar value vt. At the same time MCTS uses neural network fθ to guide its simulation.
Each edge (s, a) in the search tree stores a probabilistic priori P (s, a) (probability priori is a critical issue in the CNN), a number of visits N (s, a) and actions Value Q (s, a). Each simulation begins with the state of the root node, iteratively iteratively selecting a sub-result that maximizes the upper layer of the confidence interval Q (s, a) + U (s, a) until it reaches the leaf node s'. Then, the network expands this leaf node and performs another evaluation to generate a priori probabilities and estimates. In the simulation, after traversing each edge (s, a), the traffic N (s, a) is updated, and then the action value is updated to obtain the average of all the simulations.
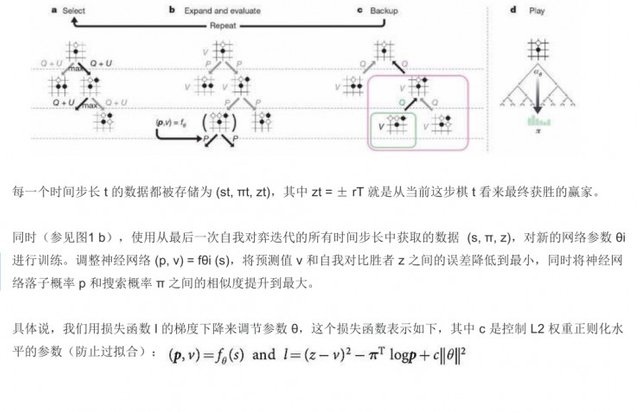
In addition, time-step calculations, as well as L2 weight regularization level parameters (to prevent over-fitting) are covered, including adjustments made using a gradient descent of the loss function.
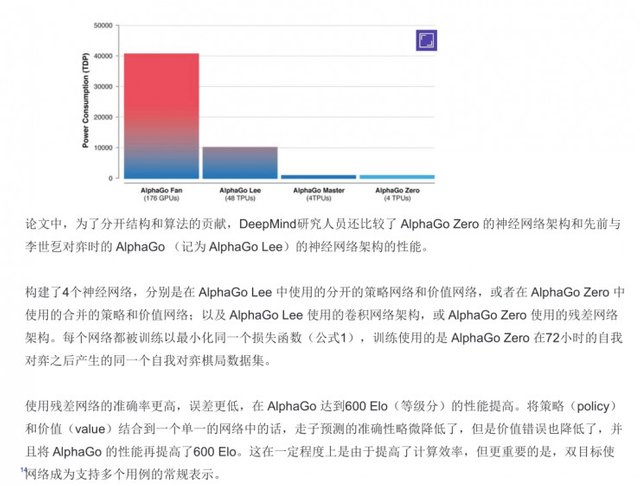
There was another very interesting thing here. They used a tensor processing unit (TPU) and made a series of explanations. They used the distributed training method completely when training the network and used 176 GPUs, 48 A TPU, in fact, AlphaGo Zero more powerful place is only four TPU to do. DeepMind also compares the performance of AlphaGo Zero's neural network architecture and AlphaGo's neural network architecture, and I will not say much in performance.

Where is AlphaGo Zero more awesome? The first is that it finds five human stereotypes (a sequence of common corners), the second is the five stereotypes used in self-play, the third is the first 80 moves in three self-games at different stages of training, each time The search uses 1,600 simulations (about 0.4s).
At first, the system focuses on wins, much like a human beginner, which is very powerful, whiteboard + unsupervised learning completely simulates human beginners. Behind, concerned about the potential and ground, which is the fundamental Go. Finally, the whole game showed a good balance, involving multiple battles and a complex battle, and eventually won more than half of White's. In fact, this approach is in the non-stop parameter optimization process to make a series of work.

Then talk about AlphaGo and AlphaGo Zero some of the more.
First, the neural network weights are completely randomly initialized. Without using the experience or data of any human expert, the weights of the neural network start from stochastic initialization completely, choose stochastic strategies, and use self-learning to enhance and enhance themselves.
Second, without prior knowledge. No longer need to manually design features, but only the use of black and white chess pieces placed on the board, as the original input data, enter it into the neural network, in order to get the result.
Third, the complexity of the neural network structure is reduced. The original two independent structure of the strategic network and value network into one, merged into a neural network. In the neural network, from the input layer to the middle layer is completely shared, to the final part of the output layer is separated into a strategy function output and the value function output.
Fourth, abandon the rapid walk network. Rather than using fast walking subnetworks for stochastic simulation, the results obtained from neural networks are completely replaced by stochastic simulations, which improves the accuracy of neural network estimation while improving learning rate.
Fifth, neural network introduces Resnet. Neural network is based on the residual network structure of the module to build, with a deeper neural network for feature extraction. This allows for learning in a more complex board situation.
Sixth, there is less need for hardware resources. AlphaGo Zero just 4 TPU can complete the training mission.
Seventh, learning time is shorter. AlphaGo Zero reached AlphaGo Lee in just 3 days and reached AlphaGo Master in 21 days.
Today, when we talk about so much, we may need to have some good basic knowledge when it comes to teaching this popular science, including MCTS, CNN, DNN, RNN, Relu, whiteboard learning, Resnet, BP, RBM, etc. I hope everybody told me these neural networks have a more detailed understanding.
The first is to understand its basic network architecture, the second is to understand the advantages and disadvantages where. The third is its application, is used in language processing or image, what contribution it has when used. By the fourth step, when you understand these deep learning processes, you can consider applying these algorithms to your project and building your data model and algorithms. By the fifth step, you can start to reproduce it in MATLAB or Python, and then finally look at what the deep learning algorithm does for your work.

Then, in particular, do some fine-tuning work, at this time you are likely to be able to publish a thesis. In this case, I give you a better way of thinking. If you are going to use deep learning, how can you ensure that the application from a simple AI to a complicated application can be guaranteed? Actually, this is the process of perceiving the machine's cognition from the machine.
Machine Perception Here is a summary to be made. Machine perception refers to the acquisition of target observations from the environment. This is the first step. To machine awareness is more interesting, is to map the current state of the corresponding operation, for example, next to the car to start, you may hit you, this time you may be smart watches to watch you watch your movements Whether there is a change, to determine whether the reminder is valid, and then further raise the alarm level.
In fact, in the process of machine cognition, it is possible to use large quantities of deep learning and NLP techniques, image understanding techniques, speech recognition techniques and multi-modal image recognition techniques. When doing some combinations in these fields, The research is more meaningful.
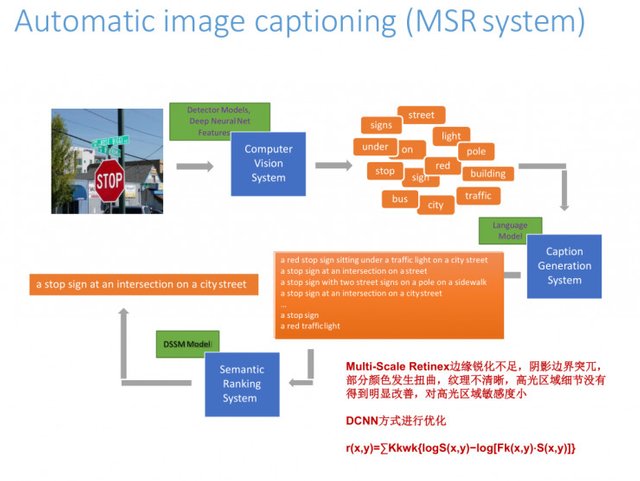
To talk about some of our recent work, this is an MSR system, we use DCNN method to optimize, the image captioning to do this system will face some problems. Multi-Scale Retinex technology here there will be some problems, such as lack of edge sharpening, shading the relatively large border, part of the color distortion and so on. We tried a lot of methods, but also a lot of parameters to optimize and found that the effect is not very good, Hinton out of the capsule, we immediately began to describe the coordinates of the object processing, without the BP reverse processing Way, and now we are doing some guesswork on the algorithm.

The final result is as follows: As we train pictures, it becomes more and more able to recognize what people are doing. The figure is seen by people and machine, the machine will think that this person is preparing food, but in fact, people will think she is doing more practical things, will all recognize all the pictures, we have now done with people Matching rate of 97.8%, but also through repeated Resnet learning to do it.
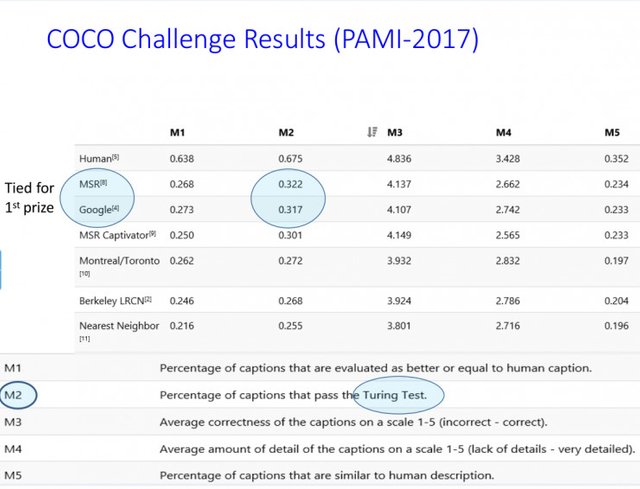
The following is the result on the COCO.
Today's open class is over, and I hope everyone will go down to the latest AlphaGo Zero essay and see if Hinton's Capsule Project can be explored if you have any ideas here. There is also a forum we can come and see, the address is mooc.ai, we can see here what there is need to discuss things.
@drotto @OriginalWorks or !originalworks @OriginalWork or !originalwork @steembank #untalented family. @red-rose and @re-steem
The @OriginalWorks bot has determined this post by @mzee to be original material and upvoted it!
To call @OriginalWorks, simply reply to any post with @originalworks or !originalworks in your message!