GDPR, digital trash and the AWS Data Pipeline

Every company has a serious digital trash problem. It is accumulating at unprecedented rates and the only solution that companies have today, is the expectation of using an infinite archive. Individuals in an organization are scared to delete data simply because they assume that everything that they have ever transacted upon is worthwhile. Management just throws more data storage at the problem because they have absolutely no visibility.
Analyst company Statista estimates that in 2018, data center storage capacity stands at 1,450 exabytes, growing to a massive 2,300 exabytes by 2021. (That’s 1.45 and 2.3 zettabytes respectively)
Most IT manager’s favorite riposte to the escalating information problem is to shrink it. The realpolitik of data storage is to compress information, eliminate duplicates, centralize location and catalog everything. In other words, let us feed it into the compactor, tie a neat little ribbon around it and throw it into our deep data warehouse!

It never seemed to matter for years on end as the usual response to aggregating useless information was to slide some more data storage spending under the budget line. More investments were made in copy data management techniques using Dedup, Compression and Erasure Coding.
But the central problem of digital data curation was never fixed. Curation involves pruning data that is no longer applicable to an organization working on the premise of automated/manual examination.
According to an Accenture study, 79% of enterprise executives agree that companies that do not embrace Big Data will lose their competitive position and could face extinction. Even more, 83%, have pursued Big Data projects to seize a competitive edge
The role of Big Data must not be underestimated for it gave birth to the philosophy being able to analyze everything under the sun! Who in their right minds would delete information without throwing it into the BI grinder first? The prospect of finding the diamond under the rough has made enterprises insensitive to the relentless accumulation of information.
Every company has now been persuaded by its infrastructure partners that a data silo growth of 100 Terabytes is actually healthy or unavoidable, whichever comes first! Infrastructure vendors are churning out disks that can store tens of Terabytes, systems that reach up to tens of Petabytes and archives that are limitless.
How can we fix something when we are not aware that it is broken?
But then the industry has a convoluted way of reminding companies about their vulnerabilities when it is least expected. GDPR dropped like a bombshell throwing the digital information management economy into a tailspin. Even though it is only the EU which is advocating GDPR, it is not unreasonable to expect that it will become the order of the day everywhere else too.
Digital trash is not just unstructured data as it is found in databases, backup images, installation software, conversations, emails, reports, configurations, installed applications, virtual machine images, documents and processes. This pervasive widely distributed data can be found on servers, desktops, tape libraries, cloud storage, storage appliances and even mobile devices.
What is Digital Trash?
Each company has its own definition of what constitutes digital trash. But here we are talking about a problem that badly needs addressing:
- The most straight forward definition from a retention perspective is information that has lost its importance with respect to compliance regulations
- Data is no longer usable because of the newly introduced GDPR’s right to forget mandate
- Application obsolescence eliminates specific data because they cannot be acted upon
- Operating system support erosion will invalidate any information that is system dependant
- Data that has an affinity to hardware which has been phased out or is unused. E.g. OS versions or saved configurations
- Information that is corrupt or undesirably mutated
- Knowledge that is lost its relevance over time either because of changed environments or altered priorities. E.g. if a product line is discontinued, then all data belonging to that product is obsolete
If companies have to arrive at an acceptable solution, it is evident that visibility to all data is absolutely critical. It is equally clear that centralization of all data is a virtual impossibility given their operating diversities. Without significant Extract-Transform-Load (ETL) processes, it is impractical to invest in a cold data management platform. Establishing on-premise trash repositories are futile because of data mobility and infrastructure availability requirements
The idea of a universal recycle bin is long overdue
As a concept, the recycle bin is omnipresent. It started with desktop operating systems, moved over to network file systems, infiltrated databases and now is part of even mobile devices. But what every medium to large sized organization needs is a recycle bin in the cloud which is universally accessible from on-premise infrastructure, mobile devices and in-cloud applications.
The act of deletion gets information into the universal recycling bin (URB). But given the complex process of labeling digital trash, automated mechanisms are vital to identify and initiate the digital trash process. This means that data in the form of files needs to be pumped into the recycle bin from any or all sources so the data can be identified, classified, sorted, dropped or accepted. If a decision is made to drop the file then it is purged immediately from the bin.
The art of identifying whether the file is drop worthy is based on a logjam of rules that incorporate everything that we have discussed earlier to identify trash data. Purge rules are a cascading set which have to be applied at regularly scheduled intervals.

The picture above hints at the complexities involved in implementing the URB. Most enterprise IT administrators will not touch primary data. This means that primary data must be literally pulled out from the (hopefully centralized) sources and then inserted into the recycle bin.
If you are worried about the ETL process in the middle, then you would be right! We have to be able to homogenize the information into a form in which we can eliminate complex business processes for identifying, tagging and isolating trashable items. This means that even database data needs to be converted into some kind of embeddable DB files. Sqlite, anyone?
File storage like Ethernet becomes a de facto standard in creating URB solutions.
This means that there is primary data and then everything else. Copy data management firms like Actifio have done this successfully in settings where homogeneity of data is established. But the real challenge in managing digital trash is to collect data that must be discarded. Once the URB is purged the data and any traces of it are gone forever.
Purging of data is idempotent which leads us to the conclusion that if we copy the same data to the URB over and over again, it will purge it automatically. This implies that once a particular piece of data is purged, it will now become a rule cast in stone.
The URB is a system that also utilizes manual curation by keeping data around for a pre-ordained time frame. The output of the URB is the erasure of the selected object, a fixed set of rules for continuous erasure and a set of inputs for cascading erasure in the primary dataset
Where does that leave us with primary data?
This is the sticky part isn’t it and it is the reason that the problem is so hard to solve. If the data architecture were done right then we would have enforceable rules to purge any piece of information irrespective of whether it is a single file, database record, Json object...
But legacy solutions are not built to uniquely identify every single piece of information floating around in the information network.
Most GDPR solutions will take the easy way out and restrict access to data that is marked for purging. This is a cheap and efficient way to solve the problem in the short term. But future applications will need to be architected to be able to insert purge rules for new items.
I guess the further we go into the future, the more important are the lessons we learn from cascading database triggers.
The long and short of it is that primary data management needs a total overhaul which will not happen in our lifetimes! Hence the best approach is a band aided solution of custom scripts that will only purge data that can be safely deleted
Wherefore are art thou, AWS Data Pipeline?
URB needs a data driven workflow that operates on data dropped into the recycle bin. It is easy to envisage a process that is initiated at regular intervals to process the output of the ETL operation. But some deciding factors are:
- Each URB is a compendium of rules that are highly customized to the deployment location, workload data types, compliance regulations and nature of business
- The URB needs to be globally available along with ability to process the information
- Exclusion filters and data transformation processes are always cascading in terms of applicability
- Business process workflows cannot keep up with the volume of data that is generated in a single day
Q: What is AWS Data Pipeline?
AWS Data Pipeline is a web service that makes it easy to schedule regular data movement and data processing activities in the AWS cloud. AWS Data Pipeline integrates with on-premise and cloud-based storage systems to allow developers to use their data when they need it, where they want it, and in the required format
There are lots of interesting problems that AWS Data Pipeline can solve but it is an ideal fit for what we have in mind. A bird’s eye view of the eventual data pipeline to implement URBs is given below. The curative action step may involve integration with a business process instance.
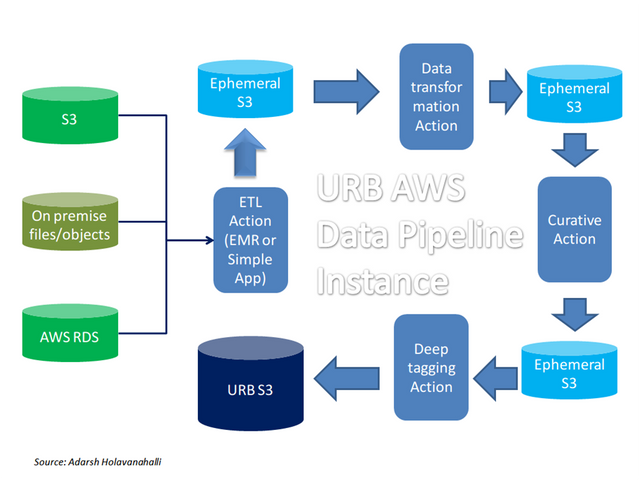
The data driven workflow is an absolute necessity when we implement large scale data aggregation, transformation and metadata marking.
Summary
Digital trash is piling up at amazing speeds. Businesses are not investing enough to deal with the problem. It is clear that GDPR has forced the hands of many enterprises and they are busy trying to figure out a workaround for the problem of holding data that is required to be forgotten. Data obsolescence is reaching a new high in this fast changing world.
Data archival has to be preceded by curative strategies to ensure that useless information does not stagnate and thus reduce operational efficiencies. AWS Data Pipeline is an ideal framework to create a digital trash management infrastructure that is customizable for your organization.
References:
I will be featuring it in my weekly #technology and #science curation post for the @minnowsupport project and the Tech Bloggers' Guild! The Tech Bloggers' Guild is a new group of Steem bloggers and content creators looking to improve the overall quality of our niche.
Wish not to be featured in the curation post this Friday? Please let me know. In the meantime, keep up the hard work, and I hope to see you at the Creators' Guild!
If you have a free witness vote and like what I am doing for the Steem blockchain it would be an honor to have your vote for my witness server. Either click this SteemConnect link or head over to steemit.com/~witnesses and enter my username it the box at the bottom.
@jrswab, thanks for reading. i am glad you found it useful. i really appreciate you showcasing my article.