Análisis del tag spanish (2da entrega) - Introducción descriptiva y análisis estadístico del payout
Para esta entrega he querido ir más allá de lo descriptivo. Para analizar el payout que obtienen los posts, he usado un modelo GLMM. En el análisis de esta entrega he incluido variables sencillas relacionadas a los posts, específicamente. En la próxima sacaré otros indicadores relacionados con los usuarios y su comportamiento.
En cuanto al análisis anterior que he publicado, resulta que la API de steem para python no me dio todos los datos que hay del tag #spanish. Como no he encontrado documentación sobre steemd no puedo explicarlo, en realidad. Gracias a SteemData he podido obtener, ahora sí, todos los datos. Esta vez los tengo hasta el 5 de Julio. Como la entrega anterior está errada debido a este mal comportamiento de steemd, repito los números de aquélla, esta vez con los valores correctos:
23,566 posts con el tag spanish.
2209 autores distintos.
El primer post con el tag ocurrió en el 02-05-2016.
Los tags más usados:
TAG COUNT
--- -----
life 6669
steemit 3315
art 3209
photography 2920
blog 2614
writing 2107
story 1598
venezuela 1458
travel 1366
news 1361
introduceyourself 1231
bitcoin 1204
nature 1074
Un dato que le interesará a @bitcoinroute: El tag #espanol a la fecha está presente en 364 posts.
Las gráficas de la serie temporal de conteos de posts y votos:
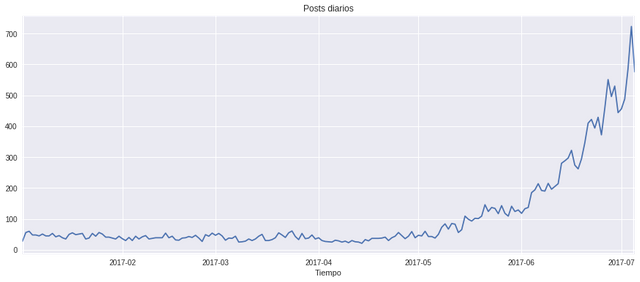
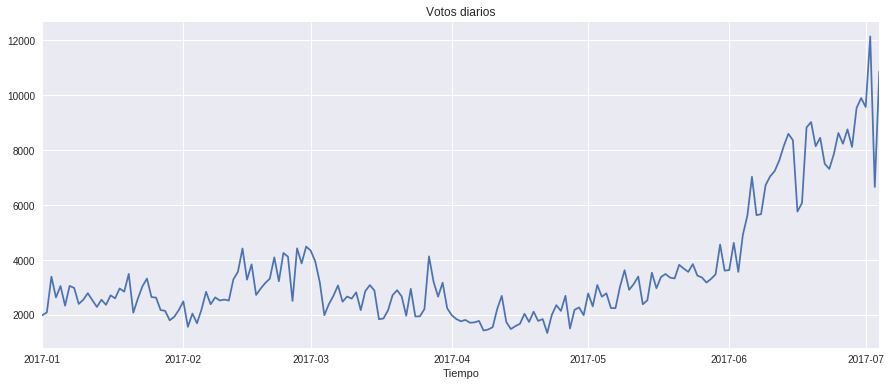
Ha habido un crecimiento exponencial imparable en posts y votos. Aunque el crecimiento de votos no supera el crecimiento de posts. Para mí esto significa un problema de sobrepoblación a lo que se añade el fork que nos ha hecho cuidar más nuestros votos.
La siguiente gráfica que quiero mostrar es la distribución de votos por día de la semana y hora del día. Para que sea información relevante (y viendo cómo van cambiando las cosas tan rápidamente, limito esto al período de Abril a Junio 2017). Las horas están en UTC, así que tendrán que restar sus horas de su zona horaria.
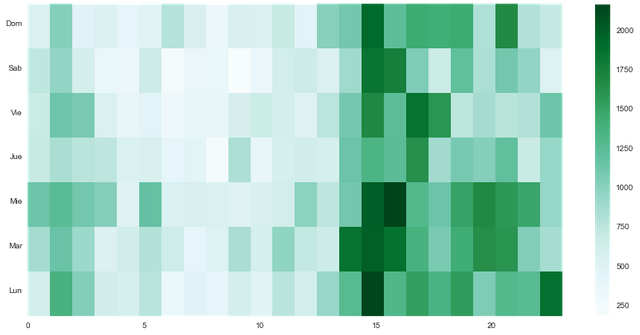
Lo mismo para los posts, conteo de posts agrupado por día y hora en que fueron creados:
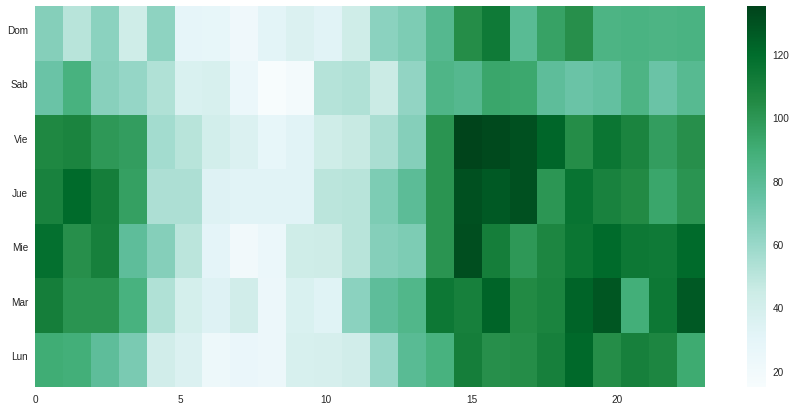
Esto muestra los patrones de actividad. Claramente hay mucha actividad cuando es de día en latinoamérica.
La distribución de los payouts es obviamente algo muy desigual. Steemit tiene una economía absolutamente dominada por una élite de personajes que conocemos como ballenas. Son estas ballenas quienes con sus generosos votos reparten el dinero de steemit a su antojo. Hay varios proyectos pro-ballenatos (minnows) que se dedican a combatir esto, pero a decir verdad veo difícil cambiar esto a menos que se regule más la red. Claro que no todo es rencor o envidia. Muchas de estas ballenas o "delfines" han invertido dinero externo en comprar steem, además que han hecho el esfuerzo por ir creciendo, así que no pienso que sea un asunto blanco o negro. Es sencillamente la manera en que funciona esto. Se me ocurrió graficar los cuantiles del payout a través del tiempo para que se vea la evolución de su distribución:
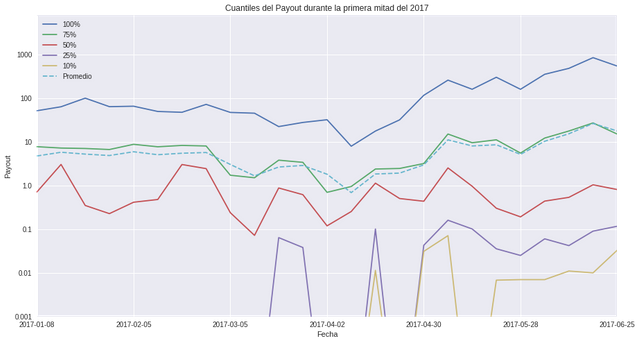
Como se puede ver, sólo el 25% de posts ganan más que el promedio (10.8SBD). Algo interesante y motivante es que los cuantiles bajos (10% y 25%) han ido obteniendo mejores pagos, tal que ahora el 90% de los posts gana más de 0.015SBD, que es casi nada, pero hace unos meses se tenía una situación peor.
Definitivamente la comunidad hispanohablante ha ido creciendo y avanzando y cada vez es más sencillo llegar a ganar por lo menos unos centavos. Sin embargo, hacer posts que caigan en ese 25% que gana más que el promedio es algo bastante difícil. La distribución de los payout ha evolucionado hacia mejorar los pagos de los peces menores, pero no ha bajado el promedio a un cuantil más justo. Una distribución sin sesgo tiene el promedio cercano al cuantil 50%. Sin embargo se puede ver que se ha mantenido el promedio en el cuantil 75% y eso dificilmente va a cambiar. En especial con la ola de nuevos que tienen poca reputación y alcance.
Hace unos días vi gráficas generales de steemit. Estas gráficas han demostrado un estancamiento en los votos y los posts. Sin embargo estos datos específicos del tag spanish no muestran esa recesión. Muestran un crecimiento bastante grande. Ya veremos en unos meses si ese crecimiento se mantiene.
Finalmente, el análisis prometido. Lo que muestro a continuación es el resultado de un modelo GLMM. Este modelo intenta explicar qué factores influyen en el payout de los posts. Para esta entrega incluyo ciertos tags y ciertas variables que yo he considerado relevantes. Sin embargo esto está repleto de sesgos. Se trata de un análisis sin rigor, para nada conclusivo y bastante exploratorio. A pesar de esto, dada mi experiencia, considero que es información valiosa y que puede ayudarnos a ir comprendiendo qué posts reciben mejores pagos. Ya advertidos, les explico: el método GLMM o modelo generalizado lineal con efectos mixtos permite agrupar los datos y hacer que cada grupo tenga efectos aleatorios que expliquen la variabilidad de los datos. En este caso he agrupado los posts por autor, y cada autor tiene su intercepto. Esto significa que el modelo permite que cada usuario tenga su nivel de pago individual. De modo que datos de usuarios con pagos bajos no intervendrán con datos de usuarios con pagos altos. Esto es muy importante porque si dejamos que esos datos se influyan, los efectos de cada factor estarán contaminados con esa variabilidad entre usuarios.
He añadido una variable que indica si @cervantes ha votado los posts. Cervantes es un proyecto que se dedica a valorar contenido bajo el tag spanish. Es de las pocas ballenas en la comunidad en español y su presencia es muy importante para hacernos crecer económicamente. De modo que sus votos, como se verá suben los pagos considerablemente, y el sesgo que tenga cervantes para votar será introducido si no se le separa de los demás factores. Por ejemplo, si cervantes vota los días lunes y no se identifica a los posts votados por éste, entonces el modelo pensará que los lunes los posts son mejor pagados, cuando en realidad es el efecto cervantes.
Así como este ejemplo, claramente hay factores escondidos que yo no incluyo por puro sesgo personal. Así que estos modelos hay que tomarlos con pinzas.
Otro asunto importante es mencionar que este modelo nos da un efecto estadístico para cada factor. Pero esto no es un argumento de causalidad. Es decir, que si sale que un post sobre gatos recibe más pago, no quiere decir que si yo posteo sobre gatos mágicamente recibiré más pago. Podría ser que quienes postean sobre gatos tienen followers que les han ido incentivando a postear sobre gatos, pero al postear yo sobre gatos sin tener esos followers no recibiré mayor pago. Correlación no es causalidad.
Les copio el resultado del modelo, pero no se asusten. A continuación explicaré los hallazgos:
Mixed Linear Model Regression Results
====================================================================
Model: MixedLM Dependent Variable: np.log(totalpay)
No. Observations: 15104 Method: REML
No. Groups: 1719 Scale: 2.6769
Min. group size: 1 Likelihood: -30066.2892
Max. group size: 164 Converged: Yes
Mean group size: 8.8
--------------------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
--------------------------------------------------------------------
Intercept -2.033 0.064 -31.951 0.000 -2.157 -1.908
C(weekday)[T.1] -0.110 0.049 -2.226 0.026 -0.207 -0.013
C(weekday)[T.2] 0.035 0.050 0.693 0.488 -0.063 0.133
C(weekday)[T.3] 0.217 0.053 4.093 0.000 0.113 0.321 ***
C(weekday)[T.4] 0.131 0.053 2.455 0.014 0.026 0.236 *
C(weekday)[T.5] 0.043 0.053 0.814 0.416 -0.061 0.148
C(weekday)[T.6] 0.040 0.053 0.757 0.449 -0.064 0.144
cervantes_upvote[T.True] 3.817 0.038 100.926 0.000 3.742 3.891 ***
wordcount_title 0.023 0.004 6.195 0.000 0.016 0.030 ***
wordcount_body_norm 0.150 0.019 8.078 0.000 0.114 0.186 ***
life 0.107 0.037 2.865 0.004 0.034 0.181 **
art -0.078 0.058 -1.333 0.182 -0.192 0.037
photography 0.005 0.052 0.092 0.927 -0.097 0.107
writing 0.081 0.062 1.308 0.191 -0.040 0.202
story -0.103 0.062 -1.665 0.096 -0.225 0.018
steemit 0.250 0.045 5.517 0.000 0.161 0.338 ***
venezuela 0.321 0.061 5.298 0.000 0.202 0.439 ***
travel 0.112 0.068 1.661 0.097 -0.020 0.245
bitcoin -0.250 0.076 -3.279 0.001 -0.400 -0.101 ***
music -0.233 0.082 -2.850 0.004 -0.394 -0.073 **
history 0.033 0.094 0.354 0.723 -0.151 0.217
poetry 0.046 0.085 0.548 0.584 -0.120 0.213
drawing 0.479 0.115 4.162 0.000 0.254 0.705 ***
food 0.059 0.085 0.691 0.490 -0.108 0.226
funny -0.133 0.105 -1.260 0.208 -0.339 0.074
health -0.451 0.106 -4.261 0.000 -0.658 -0.243 ***
science 0.138 0.110 1.246 0.213 -0.079 0.354
technology 0.117 0.133 0.880 0.379 -0.143 0.377
philosophy -0.151 0.134 -1.120 0.263 -0.414 0.113
news -0.161 0.073 -2.200 0.028 -0.304 -0.018 **
english -0.320 0.172 -1.858 0.063 -0.658 0.018
imgcount 0.025 0.003 7.450 0.000 0.018 0.031 **
groups RE 1.692 0.057
====================================================================
He puesto asteriscos en los resultados significativos, al estilo R. La primera columna muestra los efectos, que debido a que se ha usado el logaritmo del pago como variable dependiente, son efectos relativos. Para interpretarlos hay que sacar su función exponencial y el resultado al multiplicarlo por 100 nos daría un porcentaje.
Los primeros 6 efectos son los días de la semana en que ocurren los posts. Esto empieza desde el martes C(weekday)[T.1] hasta el domingo C(weekday)[T.6]. Muestra que los posts creados en el día jueves obtienen un 24% más pago (la exponencial de 0.217 es 1.24). Los viernes también tienen mejores pagos.
Ahora podemos cuantificar el efecto cervantes, que por supuesto ha salido muy significativo. Si cervantes vota un post, éste hará 44 veces más pago. Esto es en promedio. Hay posts que no son votados por cervantes y hacen bastante dinero, pero son una minoría. Ya investigaré eso en próximas entregas.
Los títulos con más palabras obtienen más pago. Al igual que los posts cuyo contenido tiene más cantidad de palabras que el promedio (para ser exactos una desviación standard más que el promedio).
Luego viene una serie de tags y su efecto estimado. La mayoría no parecen influir mucho. Pero hay ciertos tags para los que el pago incrementa y hay unos para los que el pago se hace menor.
Finalmente, por cada imagen que hay en el post, éste hará 2.5% más pago.
Como dije, tenemos que tomar esto con pinzas y no confundirlo con argumentos causales. Poner imágenes no hará que tus posts tengan más pago. Postear sobre salud no hará que tus posts tengan menos pago, tampoco. Yo recomendaría usar estos resultados más para ver qué nichos están más descuidados. Por ejemplo, los posts sobre salud tienen un efecto negativo. Reciben un pago 36% menor. Pero esto no debería disuadirlos de postear sobre salud. Al contrario, si van a postear sobre salud, tengan en cuenta que deben superar a los otros posts sobre salud, para evitar caer en esta estadística negativa, y dado que parece que es un nicho descuidado, al crear un post destacado sobre salud puede que reciban un pago bastante bueno ya que va a sobresalir.
Hay otros factores importantes que quiero añadir en un próximo análisis, como por ejemplo, el número de followers que tiene el usuario que postea, los días que la cuenta lleva activa, el promedio de posts diarios o semanales y otros.
Ha sido un post largo. Para los que hayan llegado hasta aquí, espero que les sirvan estos datos y análisis. Para mí es divertido explorar datos frescos e intentar comprender qué es lo que pasa entre todo este caos. Si tienen ideas para análisis próximos, no duden en comentarlas para considerar incluirlas en la próxima entrega. También propongo hacer un experimento por esta vez, para ver si este esfuerzo que he invertido puede llegar a ser remunerado. Si este post llega a tener más de 150SBD (cosa que dudo mucho ^^, pero vale la pena intentarlo), publicaré el código python que he usado para que puedan reproducir los análisis y me comprometeré a tener listo para dentro de una semana otro post detallado y didáctico de análisis de datos.
Muy buen trabajo @elguille. Espero que puedas monetizar este esfuerzo porque resulta muy interesante.
Gracias @valki. Ya veremos. Pienso que el análisis de datos tiene mucho potencial en steemit, especialmente para quienes desean optimizar su contenido para generar ingresos.
Muy interesante. Sobretodo lo relativo a las horas de voto y publicación. El tag Spanish seguirá creciendo, esperemos que durante mucho tiempo. Y si algún día podemos escribir tags con ñ será fantástico.
Siempre útiles las estadísticas, muchas gracias por tanta información de valor
Espero que te sirvan, @bitcoinroute. Saludos
@hermes1666 mira los datos de los que te hablaba ... es gran informacion para preparar el trabajo
Creo que tengo una entrada en Python que puedes usar para extraer los datos de ese TAG... Y bueno lo de la distribución por horas esta interesante, en su momento hice una publicación con una tabla pero las Gráfica hablan mejor, me gustaría saber con que librería haces esas gráficas :D
Saludos
Hola @sethroot. Me pasé por tu blog y hay bastantes posts muy buenos sobre python + steemit. Muy interesante tu bot para trading. Yo para esto he utilizado https://steemdata.com que es básicamente una base de datos Mongodb. Es muy fácil de hacer queries. Para las gráficas usé matplotlib y seaborn. Subiré el notebook al rato, para que podás ver el código fuente. Saludos :)
Saludos.
Perfecto amigo y siguiéndote... Básicamente puedes extraer toda la base de datos de Steem con la API
Próximamente haré algunas entradas de esto
Excelente. Aunque hay cosas que no logro entender a la perfección, algo de seguro podré asimilar y usar a mi favor. Gracias, bro, por tan arduo trabajo el que has realizado. upvote and I follow you
Gracias @oneray, te sigo de vuelta. Iré subiendo más análisis en el futuro. Si tenés ideas de qué analizar contame.
Saludos.
Excelente post guille, muchas gracias por compartir!
Gracias @sancho.panza