Deep Learning Note 3 -- Machine Learning Strategy of Setting up the Learning Target
This week’s course Machine Learning Strategy mainly focuses on how to work on a machine learning project and accelerate the project iteration. Since this course covers quite a lot small topics, I’ll break down my notes to several shorter posts. Topics covered in this post are marked in bold in the Learning Objectives. The original post was published on my blog and as usual, the posts are linked together for verification purpose.
Previous Notes:
- Deep learning Note 2 — Part 2 Optimization
- Deep Learning Note 2 — Part 1 Regularization
- Deep Learning Note 1 – Neural Networks and Deep Learning
Learning Objectives (Topics covered are in bold)
- Understand why Machine Learning strategy is important
- Apply satisfying and optimizing metrics to set up your goal for ML projects
- Choose a correct train/dev/test split of your dataset
- Understand how to define human-level performance
- Use human-level performance to define your key priorities in ML projects
- Take the correct ML Strategic decision based on observations of performances and dataset
Why Machine Learning Strategy?
When you are trying to improve the performance of a machine learning system, there are just too many directions you can try out. If you choosed poorly, you could waste a lot of time chasing down the wrong road. Machine learning strategy is about effectively figuring out the ways that are worth pursuing. Just to give you an idea:

Orthogonalization
Good machine learning engineers know what hyper-parameters to tune in order to achieve the effect they want through orthogonalization. For supervise learning to do well, we can base on a chain of assumptions on machine learning.

The basic idea is that each step has a set of tools to achieve good performance and these tools should be orthogonal to each other. That means tuning one set of tool in step A should not interfere with step B and we only move from one step to another after we achieves good performance on the former. The details of each step will be explained later in the post.
Early stopping, is like juggling multiple balls at the same time, could be problematic. Imaging that your steel wheel in the car not only controls the direction but also the brake. I’m sure it will be a nightmare to drive. On the other hand, I always have this concern in my head that following orthogonalization may not guarantee global optimization. However, on second thought, why should I care? If the goal here is to get a good-enough system into production, as long as this approach can achieve that, it’s a good-enough approach.
Setup your goal
Single number evaluation
Having a single number evaluation makes it faster to tell if your current idea is better than the previous ones. If you have multiple evaluations, it will be difficult to compare the performance of your classifiers, especially when you have multiple of them, say, 10 classifiers. The rule of thumb is that Dev Set + Single real number evaluation speeds up iterating (here in the example we are using the Average, assuming the average is a good combination of all other 4 metrics. Imagine you don’t have the last column and now choose).
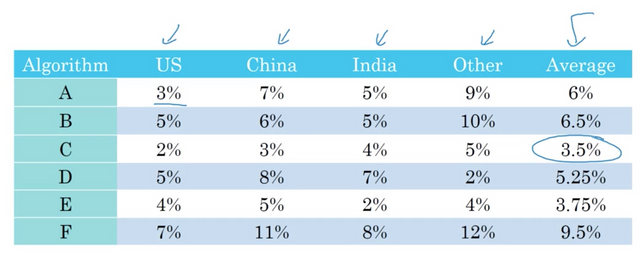
Satisfying and Optimizing Metrics
It is not always easy to setup a single number evaluation. This approach here could be a useful alternative.

Say we have N metrics. We can pick 1 metric M as the optimizing metric and the rest N - 1 as the satisfying metrics. That means we want to optimize the metric M as long as the requirements on other metrics are satisfied, like meeting your Service Layer Agreement (SLA) of 100 ms delay in the prediction.
Set up training/dev/test set
The metrics we talked about above are evaluated on the training/dev/test set. Here we discuss how to set them up properly.
How to set up the dev/test sets.
Rule of thumb is that to make sure your dev and test sets come from the same distribution. Dev set plus the metric is the target you and your team will aim at. If its distribution was different from the test set, you could spend months aiming at the wrong target. For example, if regional data are different, developing on some regions but testing on the rest could give you nasty surprises.
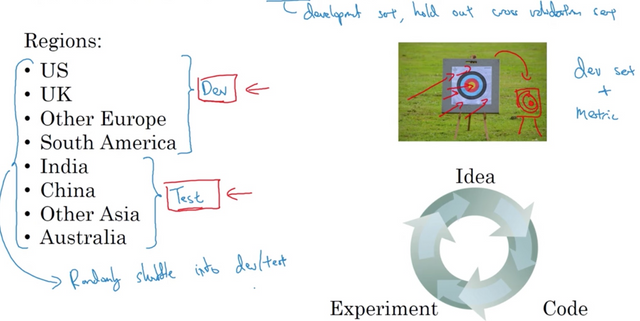
So how can we prevent this from happening?
Choose a dev and test set to reflect data you expect in the future and consider important to do well on. In particular, the dev and test should come from the same distribution. And hopefully, by setting the dev set and the test set to the same distribution, you're really aiming at whatever target you hope your machine learning team will hit.
Randomly shuffle the data for dev/test set.
How to choose the size of the dev/test set.
As mentioned in previous post, in the deep learning era, the traditional 70/20/10 split may not apply anymore. Deep learning algorithms crave for more training data. Therefore,
Unless you need to have a very accurate measure of how well your final system is performing, maybe you don't need millions and millions of examples in a test set, and maybe for your application if you think that having 10,000 examples gives you enough confidence to find the performance on maybe 100,000 or whatever it is, that might be enough.
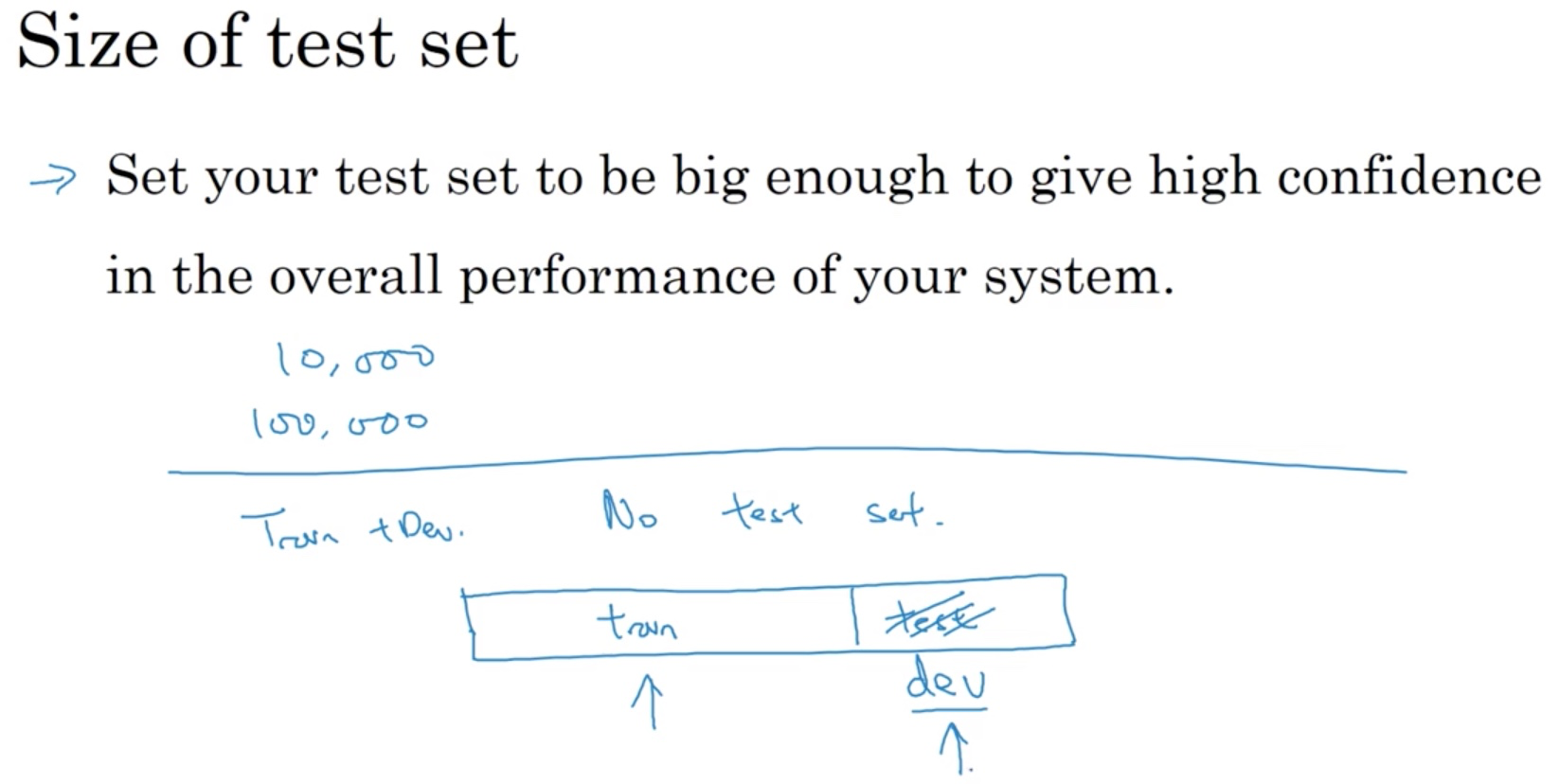
Sometimes people talk about train/test split. What they actually mean is train/dev split. It is OK to do so without a actual test set but it is more reassuring to have one.
In summary, just pick a dev/test set that is big enough for its purpose. You do not have to go up to 20 or 10 percent if you have enough data.
When to change your dev/test set and (or) metric
Changing the metric
Sometimes you realize that the target (dev + metric) is wrong. In that case, we should move the target. Suppose you have this cat image classifier of which the metric is classification error. Algorithm A has less error but some errors are on porn images, which are not acceptable. On the other hand, although Algorithm B has high error, it doesn’t make mistakes on porn images so B is actually better. This indicates that your metric is not representing the right preference and needs modification. In this particular example, assigning a larger weights to the porn images in dev and test sets would be one way to go, as depicted in red in the screenshot. Another way I can think of is to setup a satisfying metric that we want to optimize classification error satisfying the condition that there is no porn images misclassified as cat.

The takeaway is that if you find your metric is not giving the correct rank or order of preference, then it’s time to develop a new evaluation metric.
Orthogonalization
- Define your metric first. (Placing the target)
- Worry about how to do well on it separately. (Aiming at the target)
Changing the dev/test set

In this example, if A does better than B on the dev/test set, but worse in the actual application, you may need to change the dev/test set and/or metric. Specifically, the dev/test set contains high quality cat images but in production the system is dealing with blurring user images. This means you are training off the wrong data distribution.
Summary
If doing well on your current metric plus dev/test set doesn't correspond to doing well on what you actually care about in the application, then change your metrics and/or your dev/test set to better capture what you need your algorithm to actually do well on.
From engineering perspective, even if you can’t find the perfect metric or dev/test at the beginning, just set something up and use that to drive your team’s iteration. DO NOT RUN FOR TOO LONG WITHOUT A METRIC OR DEV SET. Fast iteration is the key. If down the line you find the target is wrong, change it.
I don't like the way machine learning technology is progressing. They need to be more secure and under the control of humans. Fast progress in machine learning Technology might lead to creation of a AI that can think for himself and make decisions on his own best interests. AI is a threat to human existence.
Then I encourage you to contribute to the tech community and make it the way you want it to be :)