How are the Chinese, Koreans, Indian able to write Steemit posts?
This looks like a rather odd question but before 2003, the internet was still not a universal place to do business. This was due to Europeans and Americans not being able to do online business with Chinese, Koreans and other countries with exotic languages.
We are now going into the rabbit hole of the post that I wrote yesterday on Binary - All Steemit posts are just numbers!
A small recap
In my previous post, I have written how our computer processor is able to display information in a readable format for humans after processing the binary digits 0 and 1 based on the ASCII table. We have also seen that 1 byte of information, which is made of 8 bits, can only represent 256 characters and symbols in all the languages in the world.
If we combine all the characters and symbols in the world, that we currently know of, it is way beyond 60 000 characters! How are we going to represent all those characters such that everyone can communicate with each other.
The history of the ASCII table
When computers were developed, we found that we needed a map to know what decimal combination we need to match the binary bits to our natural languages.
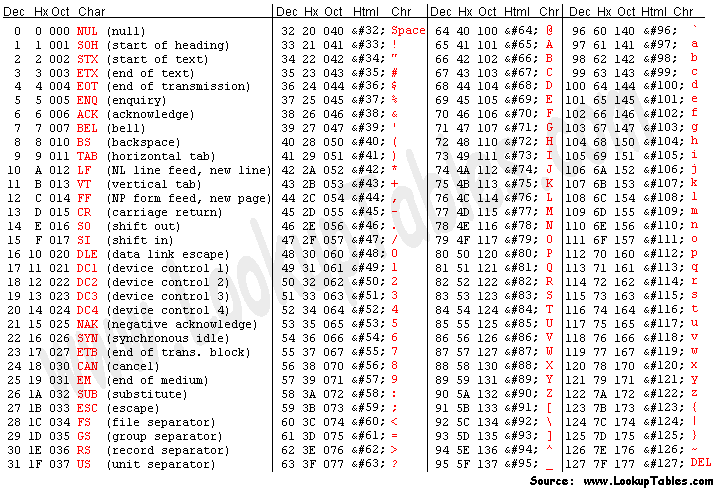
(Credit: here)
That is how we came with the ASCII table with all symbols from the English languages being represented with those 128 characters as shown above. This ASCII table was implemented inside the computers' memory so that they can refer to the table anytime to display something on the screen.
Likewise, the Chinese, Korean, Indian, Hebrew and many other languages created their own ASCII tables to represent their own language in their computers.
In this sense, a Chinese computer could interact and understand another Chinese computer but a Chinese computer and an Indian computer would not have been able to understand each other.
Here is an example that I created using the latest post of @elizacheng post titled Steepshot - My lunch with Team Malaysia / 我和大马队的午餐.
Below is part of the original text as we see today on our browser:

Before the year 2000, if a computer from America would have seen the same post, it would have looked like this (this is no joke!):

As you can see, all the Chinese characters have been replaced by squares or other characters present in the ASCII table. Hence as each computer in a country implemented their own ASCII table, sending information across borders was not possible.
If a Chinese guy bought a computer in America and received a document from Chinese origin, he would not have been able to read that document. That Chinese guy in America would have to order a computer in China and have it delivered to his place in America to be able to view the document.
Resolving the problem of ASCII tables
In order to make the Internet a truly international place, a unified table with all characters need to be made. Problem is with 8 bits or 1 byte of data, you can store only 256 characters. How do we include the Indians, Korean, Chinese and Hebrew?
This is where the development of the Unicode character set was developed and later implemented by Unicode Transformation Format (8 bits) UTF-8. Instead of having all characters limited to 8 bits, the international community devised a way to have characters to be 16, 32 and 64 bits also.
So instead of storing the data in decimal like before, they will store the information in hexadecimal. The simple reason is that it allows for more characters to be stored on the character map.
How computers resolve UTF-8 characters
With the development of the Unicode, we now have around 65 000 characters in the character map (which has replaced ASCII). Below is a sample list taken from UTF-8 encoding table and Unicode characters, which contains all the possible characters present in Unicode. You can go to the site to see all the codes and characters.

The third column represents hexadecimal values of the corresponding letter in Chinese language. There are even some interesting characters in the Unicode, like pictures of all cards, emoticons, domino tiles and Mahjong tiles.

Instead of looking for decimal values in the ASCII table like before, computers now look in the Unicode character set to find the corresponding value in hexadecimal.
How the processor reads UTF-8
As discussed in my previous post, computers take the 8 bits and then convert it to decimal and then look into the ASCII table for the corresponding character to display.
Now computers have to convert 8 bits, 16 bits, 32 bits and 64 bits into hexadecimal and look it up in the Unicode character set. How do processors convert hexadecimal to bits and vice versa?

In the above table, we have all the hexadecimal values and their corresponding decimal value. For ease of calculation, I have provided the binary representation of each of the hexadecimal characters. For an understanding of the converting to binary, check out my previous post.
Now lets take a simple example of how the letter 'X' is represented in hexadecimal. The representation of the letter X is 58. Hence looking in the table above, we place the binary digits f 5 together with 8 which gives us 01010110. This is that simple!
Backward compatibility
Now let us try the same example as in my previous post when we converted the letter 'A' and got the answer 0 1 0 0 0 0 0 1 in binary using the ASCII table. Will the result be the same when we use the Unicode table?
In Unicode, the letter 'A' is represented by 41. If we use the table above, we need to take the binary representation of 4 and stick it together with the binary representation of 1 which gives us 00100001 which gives us the same result even if we used the ASCII table.
In general, computers codes are designed to be backward compatible. Computer and software manufacturers do not want companies to change computers whenever a new technology appears. This will make many companies go bankrupt. Hence when designing change, the engineers ensured that previous machine would still be working when the character set was changed from ASCII to Unicode and that the processor still does the calculation the same way.
Converting a more complex Unicode character
So far we have looked at the conversion of English language characters whose end result still gives us 8 bits of 0 or 1. The Unicode Chinese character 㐆 look like this e3 90 86 in hexadecimal. Hence we check the hexadecimal table above, we will get the following result, 11100011 1001000 10000110 which is simplest viewed in the table below:

As we can see, 24 bits are required to represent the character 㐆 which is also 3 bytes (24/3). This is the simplest possible way of explaining this concept that I have found.
How our processor know it is getting Unicode
As we mentioned earlier, computer and software designers implemented a backward compatibility option which is still present in today's modern computers. Hence the processor need to have a way of knowing that it is going to process a Unicode character. When storing a file other that in ASCII/ANSI encoding, there is a header which is added to the file which is called Byte Order Mark (BOM). This is a 3 byte special character which is added to a file to let the processor know that this file contains Unicode and hence the processor knows how to process the characters.
If we save an empty notepad file in UTF-8 encoding, the file size would be 3 bytes even if it is empty as shown below. This is the 3 bytes BOM header!

Now if we store the character 㐆 in the same file, the file size should be 6 bytes. 3 bytes for the header and 24 bits, which is also 3 bytes, for the character we are storing.

How does Steemit tells the browser to display Unicode
When designing a web application like Steemit, we need to tell the browser which encoding is being used. Whether it is ASCII or Unicode so that the browser is able to tell the processor how to read the binary information it is getting from the Steemit server.
This is achieved by a special header information that need to be added in the website to enable the browser to know how to process. For Steemit, the encoding used is UTF-8, which supports Unicode, and is writtenin the header of the HTML as charset attribute as shown below (highlighted in blue on the right-hand side):

This can be a really mind stressing activity to wrap your head around this concept of computer logics so why not give yourself a relaxing time on the Steemit Lotto Game by playing on this post: Steemit Lotto Weekly # 8 - Minimum Pot Size 18.5 SBD

Good luck to everyone 😎
Don't forget to check if you are a winner every Sunday at around 19 00 (GMT)

(created by @readallaboutit)
Wow, really interesting. I had no idea! And I'm still at least mostly clueless about this! :) I didn't know that if you wanted to read documents in Chinese, you had to buy a computer in China years ago! So crazy. So you would have possibly had multiple computers to be able to read emails from family members if you were an immigrant and had friends in your new country! That is pretty wild. Thanks for a cool post.
Yes there are some stories about how the internet evolved which has been forgotten or not really covered by media :)
useful post,,,wow post, I upvoted and followed you. Can you check my last blog post ,
https://steemit.com/motivational/@rockyhandsome/self-confidence-have-faith-in-yourself-be-inspiring
Well explained. Great post!
Thanks :)
Wow I never even realized this, but you explain it very clearly which I like a lot, thank you!
Thanks for the nice comment :)
Thanks for sharing it. I did not know much about unicode characters. But you give me great detail about how its work! how we can calculate it.