Project S - Day 5: Persisting information in a datastore, and more
In my previous blog, Project S - Day 4, I talked about some design considerations: Speed, Persistence, SPAM and Interconnecting components. Due to some private matters, I have had to postpone development several times, but in the few spare hours left I also was able to make some great progression and fixed several issues. The main one being the issue of lagging behind on the blockchain.
Lagging issue
We will need to figure out a way to detect when we are lagging to much and catch up again. I believe this is going to be the most difficult part of the whole server component.
OK, I decided to shift my priorities to this one. After going through all relevant code in the steem-python library, I found that for every action a separate call to the steemd client was made. This resulted in at least 3 to 4 calls to the server for each block, and can become quite inefficient if you request lots of blocks successively. This maybe doesn't really matter if you are querying the database-api for historical data, but live blockchain streaming proved to be slow. Therefore I decided to write my own code that pulls the blocks from the servers in semi-realtime, requiring sending only a single request to the server for each block. I also implemented an ability to catch-up in case we start lagging behind again.
NOTE:
Actually, the catch-up mechanism requires it's own call to the server to get the last irreversible block number, but this usually happens only once every few blocks.
Running the test code during the weekend proved no more issues with lagging! In the end, the solution was more easy than I thought, although it took me quite some time to figure out what was happening and how to solve it.
from time import monotonic, sleep
from lib.server import Worker
from .blockchain import BlockChain
from .steemd import SteemdHTTPClient
class Steem(object):
def __init__(self):
self._steemd = SteemdHTTPClient()
self._blockchain = BlockChain(self._steemd)
def get_last_block(self, irreversible=True):
if not irreversible:
return self._blockchain.last_head_block
return self._blockchain.last_irreversible_block
def stream(self, filter=None, raw=False):
previous_block_nr = self._blockchain.last_irreversible_block_number
blocktime = self._blockchain.block_interval
prev_time = monotonic()
while True:
for block in self._blockchain.get_blocks(start_block_number=previous_block_nr + 1):
yield block
previous_block_nr = block.block_number
curr_time = monotonic()
sleep_time = max((blocktime - (curr_time - prev_time)), 0)
prev_time = curr_time
sleep(sleep_time)
class SteemWorker(Worker, Steem):
def __init__(self, **kwargs):
Worker.__init__(self, **kwargs)
Steem.__init__(self)
def _run(self):
previous_block_nr = self._blockchain.last_irreversible_block_number
blocktime = self._blockchain.block_interval
prev_time = monotonic()
while not self._sentinel:
for block in self._blockchain.get_blocks(start_block_number=previous_block_nr + 1):
self._process(block)
previous_block_nr = block.block_number
curr_time = monotonic()
sleep_time = max((blocktime - (curr_time - prev_time)), 0)
prev_time = curr_time
sleep(sleep_time)
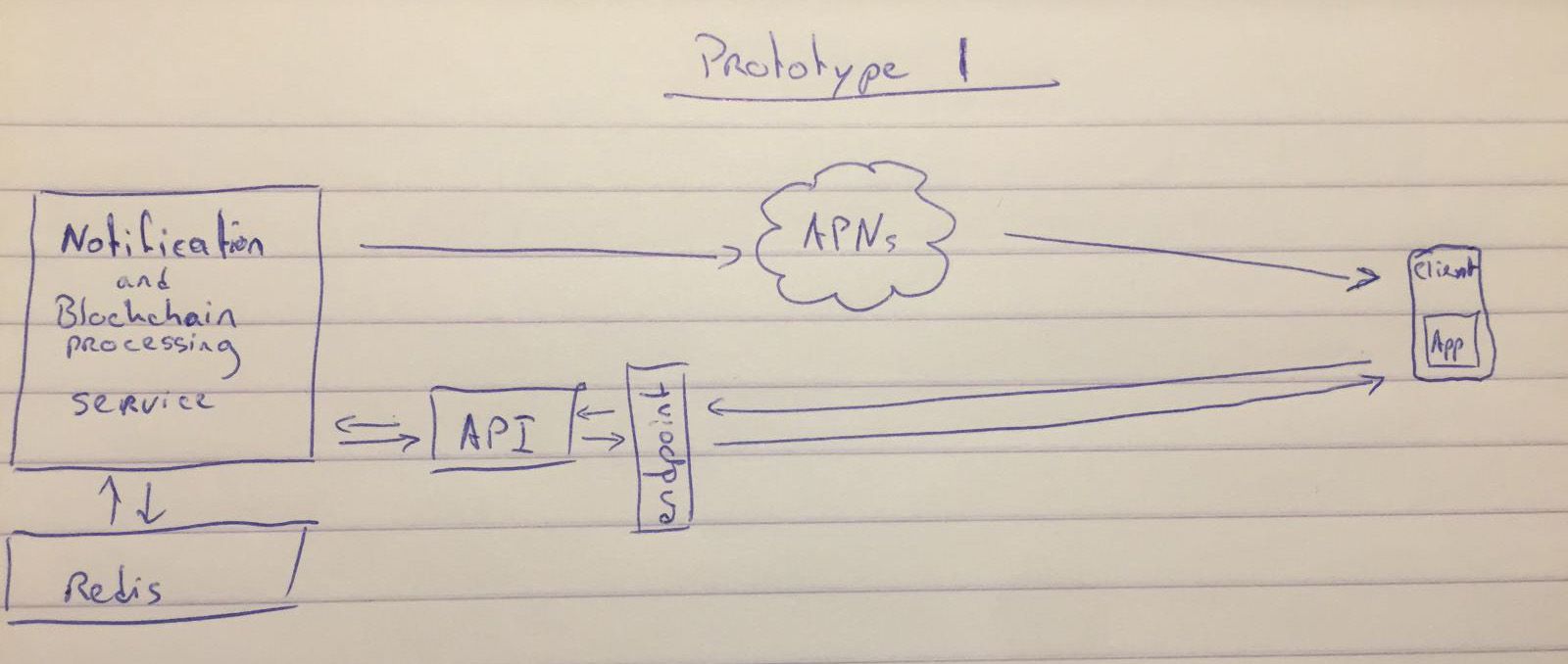
Persisting information
As said, I choose to use to use Redis for data storage. We can use this to store the device tokens of the users that want notifications from our server, as well as some settings that might need to be linked to a specific device. Although Redis is mainly stored in memory, we can persist the data on request by issueing the BGSAVE command to our Redis server. This saves the state of the database to disk and is useful in case the server crashed or gets rebooted in between snapshots (those are automatically created by the server, but the interval depends on several factors and settings).
I've also created several worker-components that use a Redis database as a means of communicating. The blockchain-worker reads the blockchain and enqueues relevant operations to one or more lists. The processor gets items from this list, filters, and queues them for the notification-worker and the API database. The notification-worker processes its own queue (filled by the processor) and sends out the notifications to its subscribers. The API, on the other hand, is used to provide our App with the required data.
NOTE:
I recomment this post by @furion to get an insight in what data is contained in a block. If you want more info about the Steem blockchain and programming for it, I highly recommend you check out his posts.
SPAM
I decided to postpone any filtering mechanisms to a later version. Let's first get the base established and running reliably.
NEXT UP: Some more iOS App programming to create a basic front-end

Looking forward to chatting with you
Great! I'll contact you soon.
Great progress so far Ben!! I am thrilled to see how everything will work out in the near future!
Thanks for your work @bennierex Followed...
Congratulations @bennierex! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPCongrats on investing into steem!
Congratulations @bennierex! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOP