A breakdown of how search engines work; what they do, how they do it and how they profit from doing it

The main purpose of search engine is to produce high quality content relevant to the search query entered by each and every of it's user.
That said, Google has been acknowledged as the best search engine in the world due to its wide distribution network with other major search engines trailing in its shadow.
Search engine operations can be divided onto three processes, they include
- Crawling
- Indexing
- Retrieval
More about these in a moment but first I wanna talk about a few points.
Search Engines vs Directories

Though they have confused to be the same in the past search engines are different from web directories.
Web directories are websites maintained by humans that lists websites based on the different subjects and categories they represent while search engines are software that use advanced algorithm while searching through webpages in order to find content that's related to the words or phrases entered into the search box.
Though both involve maintaining a cache of websites there are distinctions in the way both render their services. For search engines webpages are indexed after they have been discovered by the crawler before they will rendered upon the event of a related search while for web directories websites are usually submitted for listing by the site owner.
Sometimes spiders from search engines index websites directly from web directories. Why and how they do this will be covered in the coming sections.
Getting a website indexed on search engines
Search engines can be oblivious to the existence of a new website unless the webpage has been listed on a directory or on a website frequented by the crawler.
Even after eventually discovering a new website or page search engines still experience difficulty in figuring out the quality of the content present on those pages.
To determine the quality of the contents on a page search engines rely on an algorithm. Some factors checked by this algorithm includes but not limited to backlinks (pages linking to the page from other websites) and the age of the website.

Other factors checked by this algorithm are all aimed to find a page that meets the criteria of a trusted source for the information required from the search term.
How search engines find, store and retrieve content##
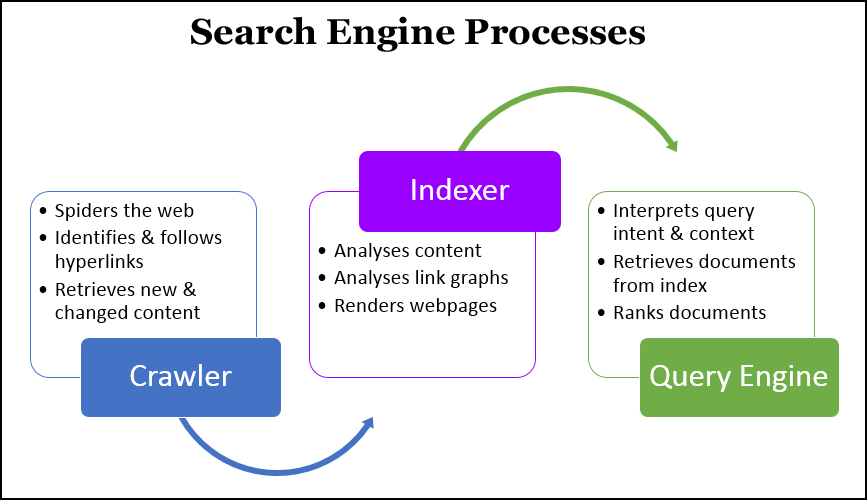
As mentioned earlier, there are three parts to a search engine.
- Crawler for finding new content and web pages
- Index which serves as a catalog or storage for discovered pages
- Search interface for the retrieval of stored pages or content during search
Crawlers
Otherwise known as spiders, they are bots responsible for finding new content and pages.
Crawlers discover new pages by virtue of links, they scour the web by following random links on pages to visit other web pages to be added to their index as new or as updates to previously added pages.
A page with frequently changing content has more chance of being crawled than pages with less changing content.
Index

After the crawler visits a page by following a link, it stores the contents of the page in what is called an index.
Using a search engine is not necessarily searching the internet, it's more like searching through a cache of websites stored in an index somewhere.
The index of a search engine can be likened to a large library of digital content where the search engine goes to retrieve information upon request.
Search engines use reverse index to organize and group their content by words.

Search engines read the contents of a page from the source code which is why it is important to write neat code that the search engine can understand easily.
Search engines also store how a word is marked up. For example, is the word emboldened, emphasized or italicized? Is the word in the page body or title, does it appear in a list, in the heading, footer? Is the word in a link to another page?
Search engines store the position where the words from the search query appear in a page to understand how close to each other the words are. Words that are close to each other are generally considered as more relevant to the search query.
Search engine tend to overlook certain words known as stop words. These include common words such as the, in, at and so on. This list of stop words by Yoast will give better insight the type of words search engines give little regard.

Search engines use term frequency to determine how often a keyword appears in a document. Words that appear too frequently are given little to no value, this explains why stop words are largely ignored.
Search Interface

After a query is entered the search algorithm will first of all try to determine the intention of the user by clearly inspecting the words against certain variable factors.
These words in the search query is checked against a lexical database like WordNet to understand what concepts they represent.

Big search engines like Google also try to determine user intent by collecting information from the user search history, if the phrase in the present search query is similar to the phrase from a past query there is a good chance the search results will contain pages displayed for the past query.

As people continue to search on a frequent basis the search engine builds a custom click through profile for each user based on their search history.
Whenever a user searches for information the search engine firstly goes through an archive containing billions of documents and creates a list of pages that contain useful information pertaining to the search term secondly it gives each page a rank accordingly by checking the page against certain ranking factors.
Lots of search engines use different retrieval methods based on their purposes, Google uses different ranking factors from Yahoo, though they may share some similarities at some point.
All companies keep their ranking algorithms secret, it is widely regarded as a secret sauce that determines the effectiveness of a search engine software.
How Do Search Engines Make Money?
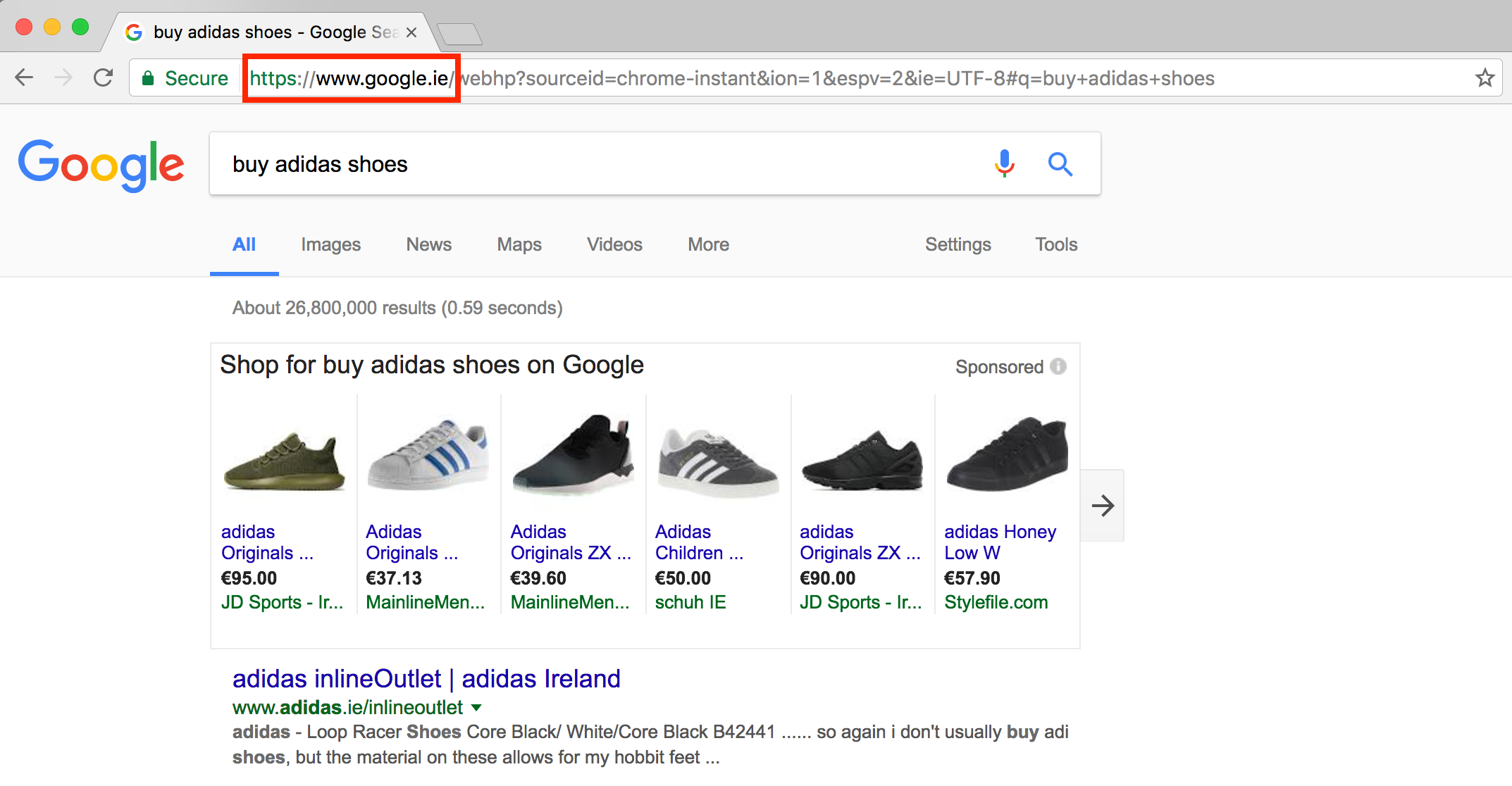
All search engines primarily make money whenever a user clicks on their sponsored ads. For example, on a Google search results page like the one in the picture below, the ads appearing at the top of the page will generate revenues for Google everytime a user clicks on it and visits the resulting page
I hope you have found this resource to be valuable, is there's any you wish I'd added, an omission you think I made or something you'd like to add yourself, kindly leave a comment and upvote. Cheers
Interesting facts about the search engine program.
@originalworks
The @OriginalWorks bot has determined this post by @gotgame to be original material and upvoted(1.5%) it!
To call @OriginalWorks, simply reply to any post with @originalworks or !originalworks in your message!
You did an impeccable job with this post
It is always good to keep in mind what these tools are for and what the differences between them would be.
Very true... Thanks for reading
Thanks for discussing a great topic "Serch Engine Optimization". good to see your post
I'm glad you like it. Thanks and you are welcome