[개발] 스몬 좀 잘해보자!
스몬에서 기존 ruleset이 두 개가 적용되는 시점 이후부터 점수 올리기가 힘들군요. 순위도 이제 50위 권에 들어가지도 못합니다. 새로운 변화에도 잘 적응하시는 분들은 정말 게임을 잘 하시는 분들 같습니다.
그렇다고 여기에서 머무를 수만은 없으니, 기존 상위 플레이어들의 게임을 복습하면서 실력을 쌓아야 하는데, 이것 또한 쉬운 일은 아니죠.
그래서 데이터 기반으로 스몬을 하기로 결정했습니다.
머리가 딸리면 데이터로 극복하자!
블록체인의 장점이 모든 자료가 공개되어 있다는 것이죠. 스몬 게임 자료를 찾아봅니다.
우선 본인의 과거 대전 내역은 아래와 같은 링크를 통해서 구할 수 있습니다. 사용자 계정만 변경하면 되기 때문에 모든 플레이어의 최근 대전 자료를 구할 수 있습니다. 하지만 이 함수는 30-40개 정도의 최근 게임 내역만 알려주는 단점이 있습니다.
https://steemmonsters.com/battle/history?player=tradingideas
그래서 또 찾아봅니다.
beempy를 만든 @holger80가 운영하는 사이트가 있군요. 역시 멋진 우리 형아!!
https://beempy.com/static/sm_decks_ranking.html
여기도 자료가 많지는 않지만 리그별, 마나별, ruleset 별로 대전 정보를 검색할 수 있습니다.

그런데 말입니다.
이렇게 좋은 사이트를 찾아도 내가 만든 소프트웨어가 처리할 수 있도록 데이터를 가지고 와야 합니다. 클릭/copy/paste 수 천 번은 해야 하는데 이게 보통 일이 아니죠.
그래서 또 찾아봅니다. 얼마 전 @goodhello님이 steem-engine.rocks에 있는 데이터를 가져오는 방법에 대한 글을 쓴 적이 있습니다. 기회가 되면 한 번 써먹어보려고 했는데, 바로 기회가 왔습니다.
https://steemit.com/sct/@goodhello/11-1-2
그럼 Beautiful Soup 라는 파이썬 패키지로 대전 정보를 가져와보겠습니다.
사용법은 간단합니다. requests 명령어로 원하는 html 문서를 받은 후 Beautiful Soup로 html로 만들어진 자료로 전환합니다.
import bs4
import requests
def doit() :
r = requests.get("https://beempy.com/static/sm_decks_ranking_silver_15_Standard.html")
html = r.text
bs = bs4.BeautifulSoup(html, 'html.parser')
이후에는 받은 html 문서를 분석해서 원하는 데이타가 있는 부분을 뽑아내는 코드를 직접 짜야 합니다. html 문서를 보는 방법은 크롬에서 지원하는 개발자 도구 모드에서 확인이 가능합니다. 여기에서 보면 아래와 같은 방식으로 기술되어 있는 table에 관련 자료가 들어가 있습니다.
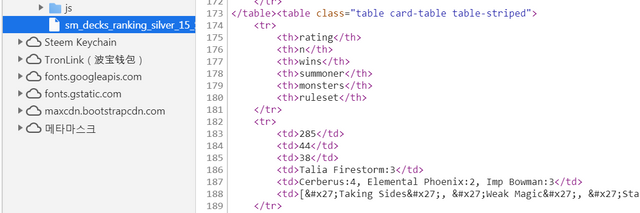
select 함수를 사용하면 본인이 원하는 부분을 뽑을 수 있습니다. 이 함수를 통해 받은 table.text에 html 관련 코드가 빠진 순수 text 데이터가 들어있습니다. 다음 순서로는 table.text의 값을 보면서 원하는 데이터를 추출하는 코드를 만들어야 합니다.
for table in bs.select("table[class='table card-table table-striped']") :
print(table.text)
table.text에는 아래와 같은 형식으로 저장되어 있습니다.
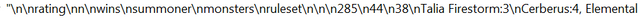
- rating 값
- 게임 수
- 이긴 게임 수
- summoner
- monsters
- ruleset
그리고 각 항목은 '\n'으로 연결되어 있군요. 이것을 바탕으로 원하는 데이터를 뽑습니다.
우선 split함수를 이용하여 'n'을 제거합니다. 그 결과 값을 보면서 원하는 데이타가 있는 위치를 확인합니다. 10 번째부터 대전 정보가 들어있고, 그 후 매 8번째 위치에서 새로운 대전 정보가 저장되어 있군요. 이러한 사실을 바탕으로 원하는 자료를 뽑아봅니다.
data = table.text.split('\n')
offset = 10
while(end == 0) :
print('rating :', data[offset])
print('tries :', data[offset+1])
print('wins :', data[offset+2])
name = data[offset+3].split(':')
print('summoner : ', name[0])
mons = data[offset+4].split(',')
print('monsters : ',data[offset+4])
print('rules : ',data[offset+5])
나름 잘 동작하는군요. 이 코드는 아래 위치에서 확인해 보실 수 있습니다.
https://repl.it/@zonemultiwhs/crawling
이게 겨우 아래 한 html문서에 대한 대전 정보입니다.
https://beempy.com/static/sm_decks_ranking_silver_15_Standard.html
이런 자료가 수백 개가 존재하죠. 수백 개의 html 문서 위치를 바꿔가면서 확인하는 것도 일이죠. 그래서 문서 이름을 만드는 것도 파이썬으로 코딩을 해서 돌려야 합니다.
이제 곧 엄청난 대전 정보가 생길 것이니, 승률이 대폭 올라갈 것으로 기대해봅니다.
jcar토큰 보팅입니다.
날마다 행복한 날,
되시길 바랍니다. ^^
Thank you for your continued support towards JJM. For each 1000 JJM you are holding, you can get an additional 1% of upvote. 10,000JJM would give you a 11% daily voting from the 700K SP virus707 account.
Hi @tradingideas!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your UA account score is currently 4.404 which ranks you at #2444 across all Steem accounts.
Your rank has dropped 46 places in the last three days (old rank 2398).
In our last Algorithmic Curation Round, consisting of 137 contributions, your post is ranked at #91.
Evaluation of your UA score:
Feel free to join our @steem-ua Discord server
^^