Categorizzazione dei testi: LSA e Clustering
Introduzione
I computer hanno implementato già da molto tempo sistemi automatici per la correzione di testi scritti: tutti noi (o almeno, la maggior parte) prima di pubblicare un post lo fa passare attraverso il correttore automatico di Word, tanto per correggere quel doppio spazio, quell'accento sbagliato o quella parola scritta male.
Si tratta di pura e semplice analisi grammaticale: come detto nei miei precedenti post, i calcolatori elettronici sono perfetti e molto più veloci di noi umani a risolvere problemi deterministici basati su regole fisse.
Ma mettiamo caso che correggere grammaticalmente il nostro post non ci basti: abbiamo appena scritto un intervento geo-politico sull'utilizzo delle cryptovalute paragonato al baratto dell'era pre-romana. Bellissimo, profondo, ma... che tag gli devo assegnare? Storia? Geografia? Cryptocurrencies? Sicuramente non gatti. E neanche Steem. O forse sì?

L'equivalente informatico di uno scaffale di libreria - click for source
Ecco, quando le regole non sono più schematizzate e i concetti diventano fumosi, i computer cominciano a perdere colpi.
La categorizzazione dei testi
Il problema della categorizzazione dei testi è affrontato spesso nella letteratura scientifica e informatica; in qualche modo costituisce le basi sulle quali poggiano le più recenti teorie di intelligenza artificiale in ambito accademico.
Come per l'Ant Colony Optimization, gli Algoritmi genetici e le Reti Neurali, anche il metodo utilizzato per la categorizzazione dei testi non potrà mai raggiungere il 100% di successo e, come gli altri criteri d'intelligenza artificiale, basa la sua efficacia sulla robustezza del "Training Set" che gli viene dato in pasto.
La differenza è che il metodo di cui voglio parlarvi oggi si basa su puri processi matematici: esatto, mettiamo il determinismo al servizio dell'indeterminatezza.
Strano eh?
Vi presento la tecnica di LSA, "Latent Semantic Analysis".
Latent Semantic Analysis
La Latent Semantic Analysis è una "branca" dell'NLP (Natural Language Processing) e si occupa principalmente del confronto tra documenti scritti in linguaggio naturale attraverso l'inferenza statistica. Con "linguaggio naturale" si intende tutto ciò che fa parte della comunicazione umana: principalmente la scrittura ed i discorsi vocali. Fanno parte dell'NLP tutti i metodi di traduzione simultanea, riconoscimento vocale, analisi dei sentimenti... tutto ciò che non è basato unicamente sulla sintassi ma che sfora naturalmente nella semantica.

Lingua non riconosciuta - Sintax Error - click for source
Per categorizzare i testi, LSA ha bisogno innanzitutto di una matrice delle occorrenze.
Questa matrice è composta da due dimensioni: i documenti analizzati e le parole che li compongono, usando come indicatore il numero di occorrenze registrato.
Facciamo un esempio banale:
Doc1: Il Cane Mangia il Pollo
Doc2: Il Gatto fugge dal cane
La matrice risultante sarebbe:

Ora, questa matrice per un elevato numero di documenti (con centinaia o migliaia di parole ognuno) può diventare gigantesca; tanto da richiedere una potenza computazionale esagerata e dei tempi di risoluzioni molto lenti. Il primo passo quindi, è la Semplificazione.
La semplificazione si occupa ridurre le dimensioni della matrice delle occorrenze usando diversi criteri:
- l'esclusione delle parole che non danno un vero e proprio significato alle frasi (e che di solito compongono le regole di sintassi): quindi l'eliminazione degli articoli, delle preposizioni, dei pronomi e così via.
- L'esclusione dei membri non utili alla categorizzazione: parole usate molto spesso in tutti i documenti, documenti identici tra di loro, onomatopee, slang ecc.
- L'esclusione degli outlier: documenti in lingue diverse, grammaticalmente e ortograficamente scorretti e così via.
L'approccio migliore dovrebbe essere quello di scremare direttamente i documenti prima di inserirli nella matrice: per questo, come nel machine learning, la scelta del "Gold Standard" di input è uno dei punti più cruciali per la buona riuscita del sistema d'analisi.
Una volta semplificata la matrice (anche usando procedimenti matematici, operazione chiamata "rank lowering") vengono applicati alcuni processi matematici per eseguire la cosiddetta "Derivazione": in parole povere il problema originale viene compresso, creando una matrice diagonale capace di "riassumere" la soluzione iniziale.
Salterò tutta la parte matematica (non che sia troppo complicata ma è lunga e laboriosa da spiegare): per chi vuole approfondire i concetti, si tratta di applicare la Singular Value Decomposition per il calcolo della matrice diagonale, usare questa matrice per ottenere i vettori caratteristici di una particolare parola o documento e confrontare la "distanza" tra di loro, solitamente utilizzando la cosine similarity.
Il risultato dell'analisi
Quindi siamo riusciti a tradurre il significato semantico delle parole e dei documenti in uno spazio vettoriale; questo spazio ci permette di assegnare un coefficiente di correlazione ad una coppia di termini o documenti. Alcuni esempi possono essere:
- Il termine "Cane" e "Gatto" sono maggiormente correlati dei termini "Cane" e "Protone"
- Il documento "Amo i cani" è molto simile per contenuti al documento "Mi piacciono gli animali", ma entrambi sono molto diversi dal documento "Riparazione navicelle spaziali".
- Il termine "Gatto" è correlato ai documenti numero 1, 2 e 3 e scorrelato ai documenti 6, 7 e 8.

Cane e gatto amici nel Latent Semantic Analysis- click for source
Come facciamo ad utilizzare queste informazioni per una categorizzazione dei testi? Utilizzando gli algoritmi di Clustering.
Il Clustering
Gli algoritmi di Clustering utilizzano la funzione di distanza tra punti per poterli riunire in due o più insiemi congrui tra di loro. Gli algoritmi di Clustering vengono utilizzati in diversi ambiti dell'intelligenza artificiale, come la biometrica, il riconoscimento delle immagini, l'information retrieval, il social network analysis e così via.
Nel caso dell'LSA il nostro scopo è riunire i documenti categorizzandoli per argomento: quindi dividere gli interventi di politica da quelli di sport, i post di scienza da quelli sugli animali ecc.
Esistono numerosi metodi di clustering, ognuno con i propri vantaggi e svantaggi; di solito l'unico modo per stabilire quanto un algoritmo sia utile e funzionale per un particolare problema è provarli tutti e verificare "sul campo" come si comportano. Questi raggruppamenti devono essere forzatamente verificati dall'intervento di un uomo ed i problemi maggiori si verificano sul confine tra più cluster.
Faccio un altro esempio: tramite la mia matrice ho appurato che il termine "Berlusconi" è associato quasi sicuramente ad un argomento di politica. Mettiamo caso però di imbatterci nel documento "Berlusconi lascia la presidenza del Milan": si tratta evidentemente di un articolo sportivo. Quindi il peso degli altri termini e l'algoritmo di clustering devono saper differenziare questo documento da tutti gli altri che parlano di Berlusconi, inserendolo in "Sport".
Tipologia di Clustering
Il clustering può essere di tipo hard o soft: il primo metodo crea dei veri e propri insiemi dove "o sei dentro o sei fuori". Senza entrare anche qui nel dettaglio dell'algoritmo, in ambito LSA è molto usato il metodo K-means basato sulla selezione randomica dei "candidati ad argomento" e alla conseguente modifica del centroide in base alla media calcolata sui vari documenti.
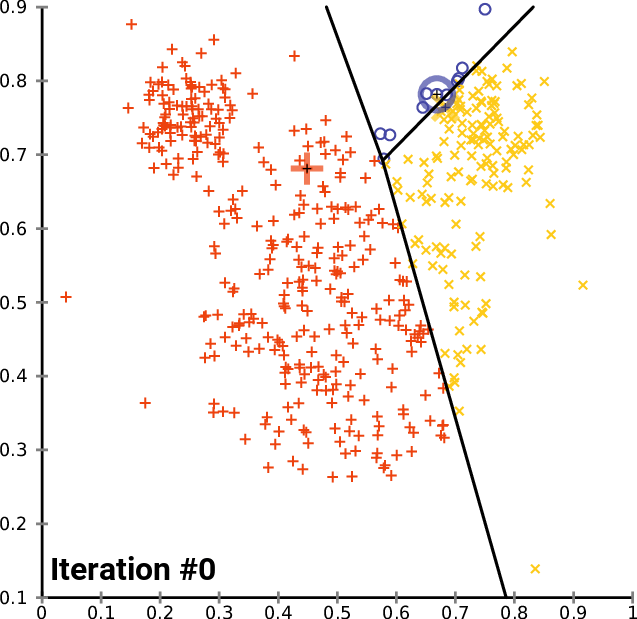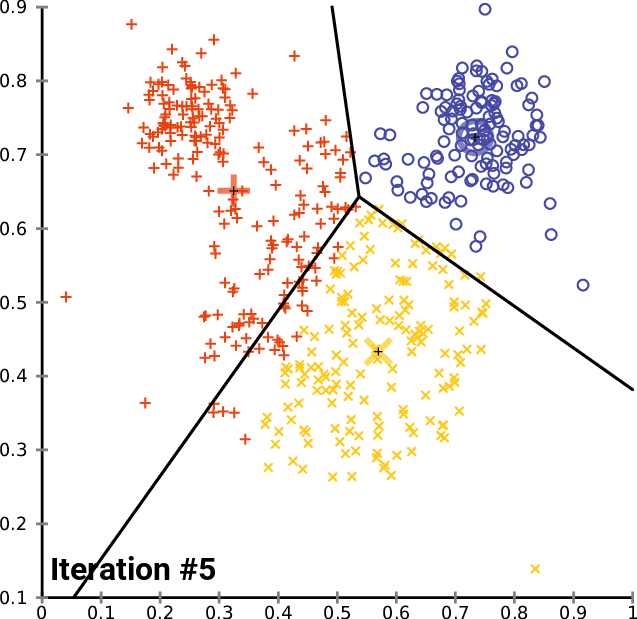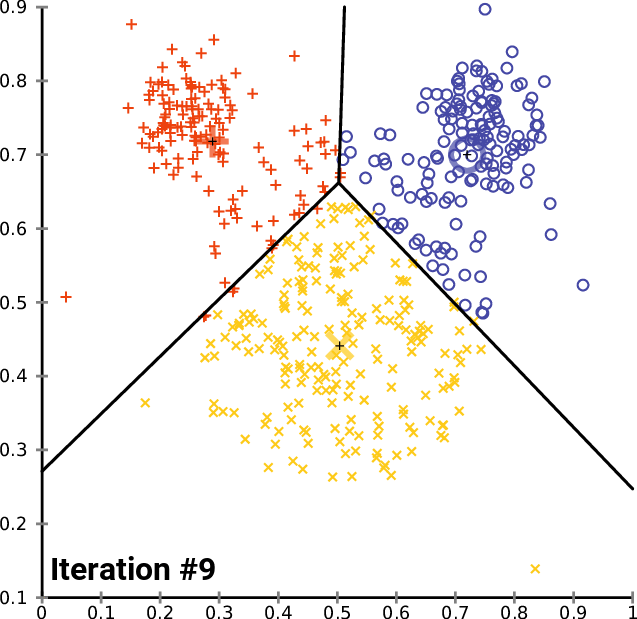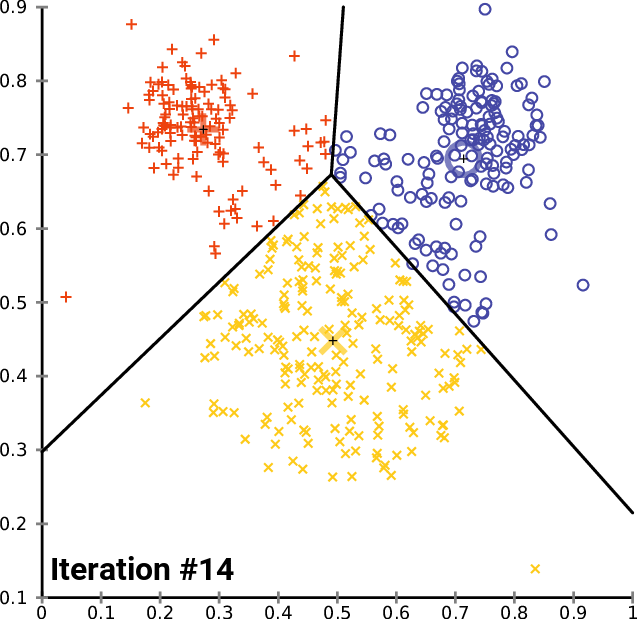
Esempio di iterazioni per il calcolo dei cluster con l'algoritmo K-means - click for source
Il clustering soft (basato sulla cosiddetta "Fuzzy logic") non assegna ad ogni documento una specifica categoria, ma permette di applicare una percentuale di correlazione ad ogni documento o parola. Ad esempio "Berlusconi lascia la presidenza del Milan" avrebbe un 20% di politica ed un 80% di sport. L'algoritmo usato in LSA è il Fuzzy C-means clustering, molto simile applicativamente al k-means ma che ci permette di prendere in considerazione alternative ad un eventuale falso positivo generato dall'procedimento di clustering hard.
Applicazioni
LSA viene ad oggi utilizzato per l'analisi semantica automatizzata: abbiamo fatto l'esempio per la categorizzazione dei testi, ma viene usato anche per il riconoscimento di sinonimi e contrari, per la correlazione tra un set di testi ed una stringa di parole (information retrieval... esatto, sto parlando di Google), per la ricerca di documenti in altre lingue con la dovuta traduzione del vettore dei termini (cross-language search).
O, chissà, in futuro potrebbe permetterci di inserire automaticamente i TAG dei nostri post su Steemit senza starci a pensare troppo... o per analizzare la semantica dei post italiani e notificarli ai particolari canali tematici di Discord.
Tra l'altro a cosa serve l'I.A. se non per mettersi al servizio dell'uomo?
Fonti e approfondimenti:
- An Introduction to Latent Semantic Analysis (Thomas K Landauer, Peter W. Foltz, Darrell Laham) http://lsa.colorado.edu/papers/dp1.LSAintro.pdf
- Probabilistic latent semantic indexing (Thomas Hofmann) https://dl.acm.org/citation.cfm?id=312649
- Come calcolare la Singolar Value Decomposition http://www.okpedia.it/come_calcolare_la_singular_value_decomposition_svd_di_una_matrice
- A Comparison of Document Clustering Techniques (Michael Steinbach, George Karypis, Vipin Kumar) https://pdfs.semanticscholar.org/c110/0f525044b2b926f7bd7f407ce7b0157bcfd8.pdf
- K-Means Clustering (John Burkardt) https://people.sc.fsu.edu/~jburkardt/classes/isc_2009/clustering_kmeans.pdf
NOTA: tutte le foto presenti sono liberamente utilizzabili con licenza Creative Commons
Caro omonimo, volevo dirti che sei stato votato anche da SteemStem, complimenti!
Grazie mille a te e a SteemSTEM... Voto il commento con piacere, é il minimo che possa fare 😊
Ci sta un errore che farebbe svenire svariati miei professori: non si può parlare di correlazione quando si parla di frequenze. Si parla di connessione. La correlazione si usa per le modalità numeriche. Come fai a calcolare la covarianza e varianze di due parole?
Come fai a fare la correlazione fra punti? Gli algoritmi di clustering, da quanto ne so, si basano per lo più sulla distanza euclidea. Ossia di norma euclidea, dell'algebra lineare, cantata con parole diverse.
Noto un abuso della parola correlazione che mi fa pensare ad una influenza di carattere informatico e di cultura americana.
Quando scrivo "correlazione" intendo la relazione tra una parola e l'altra dal punto di vista semantico. Io non sono un matematico quindi mi spiace se ho utilizzato termini a sproposito, ma la terrei perché secondo me due termini che afferiscono allo stesso "tema" sono in qualche maniera connessi tra loro (non da un punto di vista statistico ovviamente).
Per gli algoritmi di clustering stessa cosa, ma effettivamente all'interno della frase "generica" non ha molto senso, lo tolgo ;)
Qui vedo un errore d'algebra o forse una mia mis-interpretazione. La SVD non calcola solo la matrice diagonale. Calcola 3 matrici diverse. Più precisamente decompone la matrice di partenza in 3 matrici, che hanno dimensioni diverse.
Beh ma io non ho detto "solo" :) Hai ovviamente ragione tu, ma è la matrice diagonale ad essere usata per il calcolo della distanza tra termini. Grazie comunque per le puntualizzazioni!