GIT feature branches vs. Continuous Integration (CI) - Improve your software development
Have you ever asked your self how to use feature branches correctly?
Hay Steemians,
have you ever seen a project on GitHub which has like 100 different branches? If not you may have a look at the Steem Repository that currently has about 79 different branches and can be used as a good example for those kind of projects. In this post I‘ll explain why this can be a bad practice if not done properly and how to work with feature branches correctly.
Basic knowledge
So lets start by clarifying both buzzwords “feature branches” and “Continuous Integration” which I’ve used in the headline.
Feature branches
As this is a pretty common technique a lot of definitions exist. Here is one from Martin Fowler who could be called the godfather of CI. In one of his blog posts he describes a feature branch like this:
The basic idea of a feature branch is that when you start work on a feature (or UserStory if you prefer that term) you take a branch of the repository to work on that feature. In a DVCS**, you'll do this in your personal repository, but the same kind of thing works in a centralized VCS too.
**A DVCS is a „Distributed Version Control Systems“. Examples are Git or SVN
The following picture shows this pattern in action.
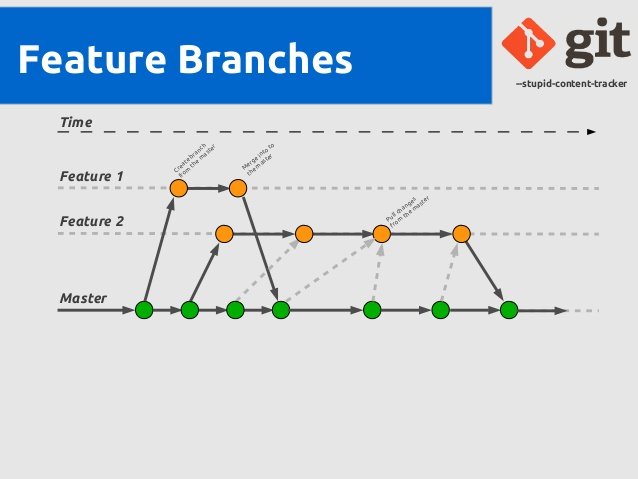
Source
What is Continuous Integration (CI)?
I‘ve discussed this topic already in one of my first posts here on Steemit. If you actually haven‘t heard about CI in general, I would suggest to read this post first.
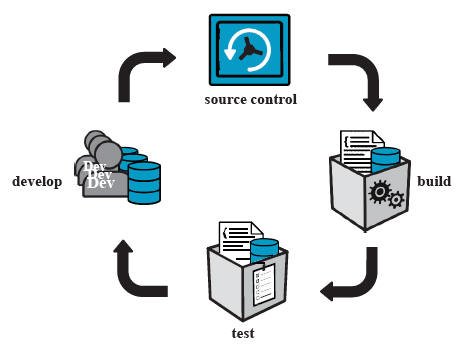
For those of you who just need a small recap, here we go: The main goal of CI is to integrate changes as often as possible to do not detect problems after working on single feature for days, weeks or even moths.
To achieve this you or your company needs some kind of CI-Infrastructure which can handle the following workflow:
- Every change that a develop makes gets committed into the version control.
- A CI-Server detects the change and starts to
- Build the software
- And executes fast unit tests
- When the build is done it provides a fast feedback to the developers. In case of a failed build or test execution, the developer who is responsible for this fail has to fix it as soon as possible.
Source
{kind=link}
First thoughts
Now, both techniques are really great and can help to secure the quality of the source code you deliver and make sure that you always have a working revision of it. This sounds really great and I guess everyone wants to use it!
Sadly, this seems to be not possible. If we have a closer look at the CI article by Martin Fowler where he describes what CI is and how to do it, we find predicates like:
Everyone Commits To the Mainline Every Day
or
Pretty much everyone should work off this mainline most of the time.
So he basically says: Do not use a branch until you have a really good reason for it. Otherwise commit to the mainline as often as possible.
If we now think of a feature branch, it could be possible that several days or weeks are required to finish this feature and merge it back to the mainline. Until this merge none of those changes have been integrated which transgress the definition of CI.
Martin Fowler made this pretty clear in his article about feature branches.
So unless feature branches only last less than a day, running a feature branch is a different animal to CI. I've heard people say they are doing CI because they are running builds, perhaps using a CI server, on every branch with every commit. That's continuous building, and a Good Thing, but there's no integration, so it's not CI.
Not only that feature branches seem to not be combinable with CI, they also come with a lot of anti-patterns. Here are just some of them:
- Merge Paranoia—avoiding merging at all cost, usually because of a fear of the consequences.
- Merge Mania—spending too much time merging software assets instead of developing them.
- Big Bang Merge—deferring branch merging to the end of the development effort and attempting to merge all branches simultaneously.
- Never-Ending Merge—continuous merging activity because there is always more to merge.
- Wrong-Way Merge—merging a software asset version with an earlier version.
- Branch Mania—creating many branches for no apparent reason.
- Cascading Branches—branching but never merging back to the main line.
- Mysterious Branches—branching for no apparent reason.
Find a full list here.
Are there alternatives?
So feature branches seem to be bad at all, but most projects will still need some way to isolate a new, big feature from the rest of the code so its not activated in production before its really ready. The question here is what alternatives we have beside feature branches? Martin Fowler mentions two of them: “Feature toggles” and “Branch by Abstraction” which I’ll explain now.
Feature toggles
One alternative are feature toggles. The easiest form of a feature toggle is some kind of flag that allows you to switch between the old and the new implementation or to activate or disable a new feature.
Here is an example:
function reticulateSplines(){
if( featureIsEnabled("use-new-SR-algorithm") ){
return enhancedSplineReticulation();
}else{
return oldFashionedSplineReticulation();
}
}
Branch by Abstraction
The „branch by abstraction“ technique allows you to perform a large-scale change to a software system in gradual way that allows you to release the system regularly while the change is still in-progress. This is basically done by adding a new abstraction layer which handles the call of the methods to change. A great example can be found again on Martin Fowlers blog.
Disadvantages
While the alternative pattern look quite great, they also came with some disadvantages.
For example toggles have to be removed some when and the code, hided by a feature toggle can still cause problems in production. One pretty funny example is the Knight Capital Group which lost nearly $400 million in assets and went bankrupt in 45-minutes because of a feature toggle. You can read the full story here.
I hope this story shows that also the alternatives do not solve all problems or at least introduce new ones.
What to do now?
So we now had a deep look on both ideas and it seems like its impossible to use both of them. But instead of having a look at the differences, we can have a look at the commonalities: Both techniques try to protect the main line! They are only doing it in different ways.
While CI tries to do it by integrating, building and testing the whole project and all changes as often as possible, feature branches keep unfinished changes in separate branches and therefore away from the mainline.
And also both techniques are not perfect: With an increasing number of developers working on the project also the chance of broken commits increases. As we already know: Those broken commits can cost a big amount of money as it blocks the developers from working. For feature branches we have a problem that a change works perfectly in its own, separate feature branch, but no longer works when merged due to changes on the mainline which happened in the meantime.
So both techniques are not that different and there might be the chance to find a compromise between them.
The compromise
The book “Using Git and feature branches effectively” ( Original post ) already provides some guidelines to use the best of all possible worlds. From my point of view the main points in that post are:
- If you start versioning my code decentralized, I also need to integrate, build and test decentralized.
- Remove a feature branch if the feature is ready.
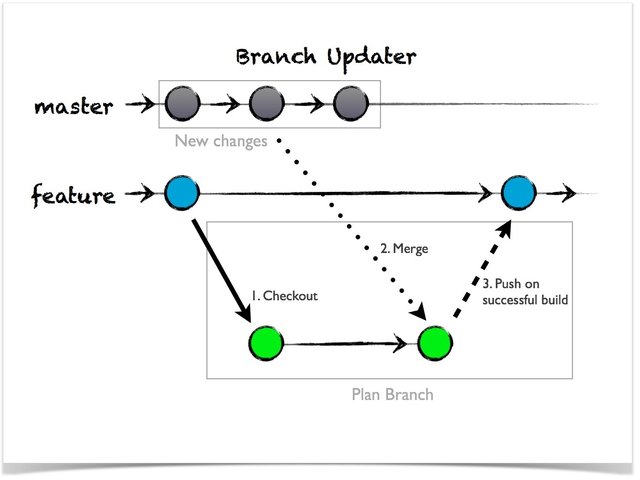
If we start to map those ideas on a concrete workflow, we end up with something like this:
- Create a feature branch
- Create a CI-Job for this feature branch
- If your CI-Server is Jenkins you can do so by using the Jenkins Multibranch Plugin which can automatically detect new branches and create a job for them.
- Start to work in your feature branch
- Merge the mainline into your feature branch as often as possible
- Create a “pull request” when you want to merge changes into the mainline.
What makes this idea quite great is that “the integration” step is also done on the branches – So the critical part of merging changes into the mainline is no longer there as you merge the mainline into your feature branch.
Source
Summary
Today we talked about the differences between Feature Branches and Continuous Integration and I hope that I could show you, why its not always a great idea use feature branches. Beside that we defined a workflow to use the best of both worlds to improve our software development again.

Thanks for reading and best regards,
@dez1337
I like the Idea of CI and also I'm not a fan of branching because sometime merging cost is to big. But you need a merging system at least between ST and UAT. :)
Ah yeah. I think it also depends a lot on the developers you are working with.. Some companys just try to introduce git from the management level, because someone heard that its cool and modern while their dev teams do not have a clue how to work with it.
There are companies that doesn't use any source control like git/TFS? In 10 years of experience I hadn't opportunity to see that. :)
:D Na, its not that bad actually. But from my experience SVN is more or less the standard and there are no things like feature branches and if so, some infrastructure guy had to create it. Beside that those topics are not taught good enough to students (at least here in Germany).
The result of both points is that you see development teams that do not have a clue how to work with a SCM in general.
Yes, in general, small companies prefer SVN because it's free.
Also in Romanian universities source control it's a "myth". But at my trainings I force my students to use Git to push their homework, otherwise I mark them "not done". :)
Haha, very good idea. They need to know that all companies want to live devops and people with those skills will get the better jobs in the end - So your students are actually some lucky guys! 👍👍
Yes, you're right. ;)
Hey, good advice here.
Would you like to have a quick look at the Steem FOSSbot Voter repo and tell me what you think of the management there? I do not use CI, not sure how to do that with a Node.js server.
I'm the only developer 😭 bar a few small contributions, but I manage it in a hierarchy like this
master - only for releases or emergency patches
^
develop - all devs work ends up here after a short period ideally (daily, or similar)
^
personal branch - work on this, merge from develop often, and merge to develop when appears more or less stable
So it's a pipeline that goes up to master.
I also use some other branches, one as a kind of scratchpad for dirty testing (as deployment is easiest from GitHub), some for the docker deployments which have some extra files and for the sake of convenience branches are the best way to go I think.
Hay @personz,
thank you for your feedback = )
So from what you describe you basically went for the pretty standard "gitflow" strcuture.
Source
Without using feature branches. From my point of view thats totally fine and when you are the only developer it also saves you some overhead.
Regarding the CI topic: I would absolutly recommend to go for that if you have some hardware available to setup a CI Server. Jenkins for example is available as a Docker-Image in can be setup in seconds. Here is a tutorial how to create a CD job for Node.js: https://codeforgeek.com/2016/04/continuous-integration-deployment-jenkins-node-js
Best regards!
Thanks for the link
You're always welcome ;)
Thank you! I'll give it a lot, it would be really useful I think. 😆
Hi, good post, I assume the "clean" Fowler setup is the same as trunk based development? I do agree that the compromise you describe is a reasonable thing to do but there is also the nagging thought that true CI needs frequent integration on a main branch. I heard Nicole Forsgren at Code-Conf and she said that her research points to trunk based development as one of the practices that creates high performing software companies. http://www.code-conf.com/speakers/?tag=sthlm&scrollto=nforsgren
Hay @jedibofink ,
Thank you for your feedback and the link to code conf - I personally hadn't the chance so far to be there 😢
I agree with your remarks, but I want to add that this strongly depends on the size of the team and its skill .. if people don't know how to work with the tools around CI/CD all strategies will fail 😅
Thank you once again and best regards!
I agree, technology/tools is one part but there is always a human side, if you don't have a buy in and knowledge in the organisation you will not succeed.
really nice post buddy,
Try to know all about latest HARDFORK? check out my latest post for sure that will help you to earn more on steemit thanks
https://steemit.com/hardfork/@thecrytotrader/so-finally-we-got-our-super-powers-the-hardfork