Programmieren in C - Hashtabellen Theorie und Implementation der Verkettung
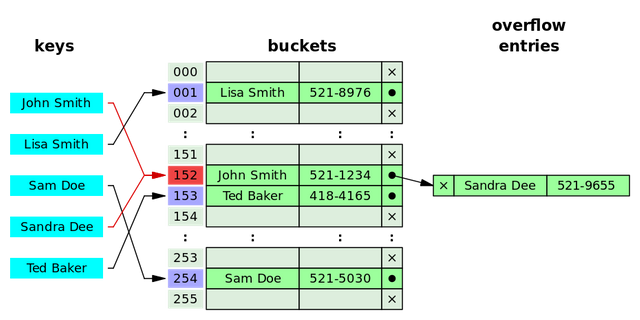
Bild Referenz: https://commons.wikimedia.org/wiki/File:Hash_table_5_0_1_1_1_1_0_LL.svg
{kind=link}
Intro
Hallo, ich bin's @drifter2! Der heutige Artikel ist an meinem englischen Artikel "C Hashtables with Chaining" basiert. Wir werden heute über das so genannte Hashing und Hashtabellen reden. Das heißt das wir also erstmal die Theorie hinter all dem analysieren werden. Zusätzlich werden wir auch die einfachste Hashtabelle implementieren, welche Elemente mit dem gleichen Hash-Schlüssel mit Verkettung in die selbe Hash-Liste einfügt. Nächstes mal werden wir eine Hashtabelle mit Offener Adressierung implementieren, bei der wir das Lineare sondieren als Kollisionsauflösungs-Strategie verwenden werden. Also, fangen wir dann direkt an.
Hashing Theorie
Hashtabellen sind eine weitere Datenstruktur, die Datenstrukturen die wir bis jetzt erwähnt haben verwendet. So eine Struktur wird bei Fällen benutzt wo eine sehr schnelle Suche nach einem Eintrag mit einem gewissen Schlüssel (Key auf Englisch) von Nöten ist. Jedes Element hat einen so genannten Hash-Schlüssel (Hash-Key auf Englisch), der anzeigt bei welcher Stelle der Hashtabelle dieses gewisse Element eingefügt werden muss. Dieser Hash-Schlüssel wird von einer so genannten Hash-Funktion berechnet. Meistens werden diese als Statische Tabellen-Felder implementiert (die vergrößert werden wenn ein Re-Hashing benötigt wird). Die einfachste Hash-Funktion ist die modulo Hash-Funktion (XmodN), bei der die Elemente bei dem Index vom modulo mit der Länge des Feldes abgespeichert werden. Mit Hilfe so einer Funktion wissen wir dann wo genau ein spezifisches Element bei einem Feld eingespeichert ist. Damit kann man dann auf Elemente sehr schneller zugreifen, als mit der Suche bei einem kompletten Feld, einer Liste oder sogar einen Binären Baum.
Kollision
Es gibt aber ein gewisses Problem. Es kommt sehr oft vor das zwei Elemente den selben Hash-Schlüssel haben und deswegen beim selben Hash-Index in der Hashtabelle angehören. Damit trifft eine so genante Hashkollision auf, die wir natürlich Auflösung müssen. Wenn ein anders Element bereits bei dem Hash-Index eingespeichert ist muss das neue Element dann bei einer anderen Stelle eingefügt werden. Es gibt sehr viele verschiedene Wege mit denen wir dieses Problem beseitigen können. Die Strategie mit der wir diese Kollisionen lösen ist sehr wichtig!
Clustering
Jedes mal wenn mehrere Elemente den gleichen Hash-Schlüssel haben, kann es vorkommen das so genannte Cluster oder Gruppierungen von Einträgen geformt werden. Dieses so genannte Clustering in Englisch) senkt natürlich die Effizienz und Leistung unserer Struktur, da wir ja nun nicht mehr einen, sondern mehrere Schritte brauchen um das Element zu finden. Sagen wir mal wir haben eine Hashtabellen von 10 Indexen und wir wollen die Werte 5, 15, 25, 35 und 45 abspeichern welche natürlich den gleichen Hash-Schlüssel (5) haben. Sagen wir mal wir lösen diese Kollisionen in dem wir die Elemente 15 bis 45 einen Index nach dem Schlüssel einfügen (das so genannte Lineare sondieren das wir gleich erwähnen werden). Jedes mal wenn wir nach 45 suchen wollen wird die Suche nun 5-Schritte dauern. Jedes mal wenn ein weiteres Element mit dem selben Schlüssel eingefügt wird, wird dann dieser Cluster verlängert. Durch das Clustern wird natürlich der schnelle Zugriff auf Elemente, welches die Hashtabelle verspricht, direkt negiert.
Also wie sollen wir dann diese Kollisionen Auflösen? Es gibt spezifische Kollisionsauflösungs-Strategien, welche mit spezifischen Datensätzen funktionieren. Je nach Datensatz wird also eine gewisse Strategie eine bessere oder schlechtere Leistung haben. Vorhin haben wir bereits das Lineare sondieren erwähnt, gehen wir also jetzt mal in ein paar mehr von diesen Strategien ein!
Kollisionsauflösung
In Code werden wir nur über zwei dieser Strategien reden, aber hier ein paar die sehr wichtig sind und sehr nützlich bei gewissen Datensätzen sein können.
Generell kann man diese Strategien in zwei Kategorien einteilen:
- Offene Adressierung (Lineares sondieren, Quadratisches sondieren, Doppel-Hashing)
- Verkettung
Gehen wir mal ein bisschen mehr in die Details von denen ein:
- Lineares sondieren, welches vielleicht das einfachste von allen ist (wenn man Felder verwendet). Bei einer Kollision lösen wir diese in dem wir das neue Element (den neuen Wert) in die nächste freie Stelle einfügen. Dieses Verfahren funktioniert sehr gut wenn die Elemente bei verschiedenen Schlüsseln angehören. Sonst werden Cluster geformt welche die Leistung senken (wie wir auch vorhin erwähnt haben).
- Quadratisches sondieren, welches sehr ähnlich zu dem Linearen sondieren ist. Eine Kollision wird jetzt gelöst in dem das neue Element bei der nächsten freien Stelle einfügen, aber in i^2-Schritten, die mit i = 1 anfangen. Damit wird die das Element nun bei der nächsten freien Stelle oder 4 oder 9 oder... Schritten nach dem Hash-Index eingefügt. Jedes mal wenn die nächste Stelle bereits frei ist wird wieder mal ein Cluster gebildet. Wenn aber die nächste Stelle bereits belegt ist wird dann des Clustering verhindert, da ja nun die Elemente nicht mehr direkt eine "Kette" bilden. Diese Technik ist sehr gut bei Datensätze wo nun ein paar der Elemente den gleichen Schlüssel haben.
- Doppel-Hashing, welches wieder mal ähnlich zu den vorherigen zwei ist. Jedes mal wenn die erste Hash-Funktion "versagt", wird eine andere Hash-Funktion verwendet. Der Hash-Wert dieser zweiten Funktion zeigt uns den Schritt den wir folgen. Also starten wir vom Hash-Index und machen so viele Schritte bis wir eine leere Stelle finden. Das ist also sehr ähnlich zu dem Quadratischen sondieren, nur das der Schritt den wir folgen nun nicht mehr i^2 ist, sondern von einer anderen Hash-Funktion genommen wird.
- Verkettung. Diese ist die leichteste von allen Strategien. Bei dieser hat jeder Hash-Index seine eigene Liste und die Element mit dem selben Hash-Schlüssel, werden dann bei der selben Hash-Liste eingefügt. Damit senkt natürlich wieder die Leistung da ja das zutreffen von mehreren Elementen bei dem gleichen Schlüssel dann wieder mal Cluster bildet. Die Leistung ist aber besser als beim Linearen sondieren da ja keine Werte von Elementen mit anderen Schlüssel dazwischen vorkommen können. Die Leistung wird also nur bei dem suchen nach Elementen in der Liste verschlechtert wo mehrere Elemente eingespeichert sind (die also den selben Schlüssel haben). Der Zugriff auf andere Elemente ist also immer noch "schnell".
Hashing Tipps
Hier ein paar Tipps die euch beim Hashing generell helfen können:
- Die Größe-Länge der Hashtabelle sollte eine Primzahl sein, welche nur mit sich selbst und '1' teilbar ist. Damit wird die Gruppierung (Clustering) von Elementen bei sehr vielen Fällen gesenkt.
- Die Kollisionsauflösung-Strategie ist immer vom jeweiligen Datensatz abhängig. Also wählt und probiert verschiedene Wege aus um zu sehen welche die beste Leistung hat. Natürlich könnt ihr auch immer auf eigene Lösungen kommen!
- Wenn die Hashtabelle bereits halbvoll ist senkt die Leistung bereits sehr. Deswegen sollte man dann erneut Hashen mit einer anderen Hash-Funktion und Hashtabellen-Länge, welches oft Re-Hashing genannt wird. Natürlich muss die neue Länge wieder eine Primzahl sein. Die Elemente die bereits bei der Tabelle eingefügt sind müssen dann erneut mit der neuen Hash-Funktion bei der neuen Stelle-Index eingefügt werden.
Implementation der Verkettung
Die Verkettung ist sehr einfach. Wir müssen ein Feld erstellen bei dem die Indexe auf verschiedene Listen zeigen. Um simple zu bleiben werde ich eine Modulo Hash-Funktion verwenden. Sagen wir mal die Länge der Hashtabelle ist '31' (Primzahl). Die Hash-Funktion kann dann sehr leicht mit "define" definiert werden wie folgend:
#define N 31 // prime number for size of array#define h(x) (x % m) //h(x) = x mod mBei dem Programm wird dann 'm' immer den Wert 'N' haben.
Datenstruktur
Sagen wir mal wir wollen einfach nur Ganzzahlen abspeichern. Die Datenstruktur bei jedem Hash-Index ist dann eine ganz normale Liste, welche von den folgenden Knoten (Nodes auf Englisch) besteht:
typedef struct Node{ int val; struct Node *next;}Node;Da 'N' ja verändert werden kann werde ich die Hashtabelle als ein dynamisches Feld definieren (also als Zeiger) und dann genügend Speicher für N-Elemente zuweisen.
Node *table; // Hashtabelletable = (Node*) malloc(N*sizeof(Node));Die Hash-Listen sollten zu "NULL" initialisiert werden, damit wir wieder mal wissen wann die Liste leer ist, etwas das bei den Operationen sehr wichtig ist!
for(i = 0; i < N; i++){ table[i].next = NULL;}Die eigentliche Implementation hat ein switch-case Menü (ich werden einen Link zu dem Code vor dem Ende des Artikels haben). Erklären wir mal die verschiedenen Operationen, damit ihr diese besser versteht.
Hashtabelle mit zufälligen Elementen füllen
Das Einfügen eines Elements in einer Liste kennen wir bereits von dem Artikel über Verkettete Listen. Beim Einfügen eines Elements in der Hashtabelle wird das Element dann bei der richtigen Hash-Liste eingefügt, je nach Schlüssel.
Die Einfüge-Funktion sieht also wie folgend aus:
Node *insert(Node *table, int hash_index, int val){ Node *nn, *cur; nn = (Node*)malloc(sizeof(Node)); nn->val=val; nn->next=NULL; if(table[hash_index].next == NULL){ table[hash_index].next = nn; return table; } cur = table[hash_index].next; while(cur->next != NULL){ cur=cur->next; //cur=cur+1; } cur->next = nn; return table;}Wir können sehr leicht eine gewisse Anzahl an zufälligen Elementen mit der folgender Funktion einfügen:
Node *fill_table(Node *table, int table_range, int number){ int i; int num; for(i=0; i<number; i++){ num = rand()%10000; // zufaellige Nummer von 0 bis 9999 table = insert(table, num % table_range, num); } return table;}Beim Menü müssen wir nur die Anzahl an Elementen als Eingabe vom Benutzer nehmen, welches wie folgend aussieht:
printf("Lot to insert: ");scanf("%d", &n);table = fill_table(table, N, n);Löschen von Elementen
Beim Löschen müssen wir erstmal die richtige Liste zum suchen finden, indem wir den Hash-Index des gesuchten Elements berechnen. Wenn die Liste leer ist (NULL) kann der Wert nicht gefunden werden. Wenn es das einzige Element ist wird die Liste dann NULL. Sonst löschen wir den Wert indem wir das Element finden das vor dem Element das zulöschen ist abgespeichert ist.
Der Code dafür ist:
Node *del(Node *table, int table_range, int val){ int index = val % table_range; Node *prev; if(table[index].next == NULL){ // if empty printf("Value %d not found cause Table[%d] is emtpy!\n", val,index); return table; } if(table[index].next->val == val){ // if first item printf("Value %d was found at table[%d] and Deleted!\n", val,index); table[index].next = table[index].next->next; return table; } prev = table[index].next; while(prev->next!=NULL){ if(prev->next->val == val){ prev->next = prev->next->next; printf("Value %d was found at table[%d] and Deleted!\n", val,index); return table; } prev = prev->next; } printf("Value %d was not found in Hashtable!\n", val); return table;}Suche nach einem Element
Die Suche ist sehr ähnlich mit dem Löschen. Hier suchen wird aber nach dem eigentlichen Element und geben es zurück als Rückgabe. Bei dem Programm gebe ich nur eine Ausgabe bei der Konsole aus, die uns sagt ob das Element gefunden wurde.
Das sieht wie folgend aus:
void search_table(Node *table, int table_range, int val){ int index = val % table_range; Node *cur; if(table[index].next == NULL){ // if empty printf("Value %d not found cause Table[%d] is emtpy!\n", val,index); return; } cur = table[index].next; while(cur!=NULL){ if(cur->val == val){ printf("Value %d was found!\n", val); return; } cur = cur->next; } printf("Value %d not found in Hashtable!\n", val);}Hashtabelle ausdrucken
Natürlich können wir die Hashtabellen-Inhalte auch ausdrucken indem wir alle Listen durch-iterieren. Dabei werde ich versuchen die Ausgabe ähnlich zu einer Liste zu gestallten. Der Code ist wie folgend:
void print_table(Node *table, int table_range){ int i; Node* cur; for(i = 0; i < table_range; i++){ // for each list if(table[i].next == NULL){ // if empty printf("Table[%d] is empty!\n", i); continue; } cur = table[i].next; printf("Table[%d]", i); while(cur!=NULL){ // else print all the values printf("->%d",cur->val); cur=cur->next; //cur=cur+1; } printf("\n"); }}Ausführungsbeispiel
Den kompletten Code könnt ihr euch bei der folgenden Adresse runterladen:
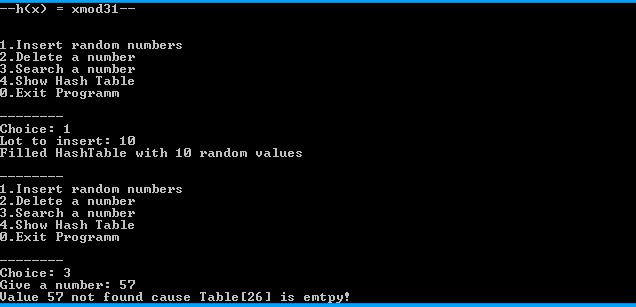
Eine Ausgabe kann z. B. wie folgend aussehen:
Referenzen:
- https://de.wikipedia.org/wiki/Hashtabelle#Algorithmen
- https://cg.informatik.uni-freiburg.de/course_notes/info2_11_hashverfahren.pdf
- https://steemit.com/programming/@drifter1/programming-c-hashtables-with-chaining
Der Artikel ist zu 90% eine Übersetzung von meinen englischen Artikel, aber enthält ein paar mehr Informationen. Die anderen Referenzen, haben dabei geholfen die richtigen Begriffe zu verwenden. Die eigentliche Änderung ist das ich nun jede Funktion erstmal alleine erkläre, und nicht direkt den ganzen Code gebe.
Vorherige Artikel
Grundlagen
Einführung -> Programmiersprachen, die Sprache C, Anfänger Programme
Felder -> Felder, Felder in C, Erweiterung des Anfänger Programms
Zeiger, Zeichenketten und Dateien -> Zeiger, Zeichenketten, Dateiverarbeitung, Beispielprogramm
Dynamische Speicherzuordnung -> Dynamischer Speicher, Speicherzuweisung in C, Beispielprogramm
Strukturen und Switch Case -> Switch Case Anweisung, Strukturen, Beispielprogramm
Funktionen und Variable-Gueltigkeitsbereich -> Funktionen, Variable Gueltigkeitsbereich
Datenstrukturen
Rekursive Algorithmen -> Rekursion, Rekursion in C, Algorithmen Beispiele
Verkettete Listen -> Datenstrukturen generell Verkettete Liste, Implementation in C (mit Operationen/Funktionen), komplettes Beispielprogramm
Binäre Suchbäume -> Baum Datenstruktur generell, Binärer Baum, Binärer Suchbaum, Implementation in C-Sprache (mit Operationen/Funktionen), komplettes Beispielprogramm
Warteschlangen implementiert mit Feldern -> Warteschlange als Datenstruktur, Implementation einer Warteschlange mit Feldern in C-Sprache, komplettes Beispielprogramm
Stapel implementiert mit Feldern -> Stapel als Datenstruktur, Implementation eines Stapels mit Feldern in C-Sprache, komplettes Beispielprogramm
Warteschlangen und Stapel implementiert mit Verketteten Listen -> Liste, Warteschlange und Stapel mit Liste implementieren in C-Sprache.
Fortgeschrittene Listen und Warteschlangen -> Doppelt verkettete Listen (mit Implementation), Zirkuläre Listen, Vorrangwarteschlange (mit Implementation)
Fortgeschrittene Bäume -> Βinärer Suchbaum (Zusammenfassung), AVL-Baum (mit Implementation), Rot-Schwarz (ohne Code) und 2-3-4 Bäume (ohne Code)
Stapel-Warteschlangen Übungsaufgabe mit Dynamischen Feldern -> Aufgabenbeschreibung, Lösung-Implementation in C (zutiefst) und Vollständiges Programm mit Ausführungsbeispiel
Stapel-Warteschlangen Übungsaufgabe mit Verketteten Listen -> Aufgabenbeschreibung, Lösung-Implementation in C (zutiefst) und Vollständiges Programm mit Ausführungsbeispiel
Anderes
Funktionsvergleich mit Ausführungszeit und Berechnungen -> Ausführungszeit berechnen, Wie man etwas beim ausführen messt (generell), Vergleichsbeispiele
Schlusswort
Und das war's dann auch schon mit dem heutigen Artikel und ich hoffe euch hat dieser Artikel gefallen. Nächstes mal werden wir über die Offene Adressierung oder besser gesagt das Lineare sondieren reden.


Keep on drifting! ;)
This post has been voted on by the steemstem curation team and voting trail.
There is more to SteemSTEM than just writing posts, check here for some more tips on being a community member. You can also join our discord here to get to know the rest of the community!