Sieci neuronowe #4 - opisanie metody gradientu
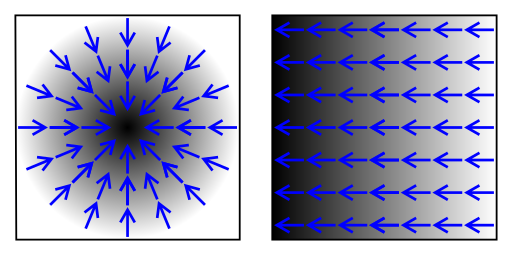
Cześć,
Generalnie metoda gradientu służy nam w sieciach neuronowych, aby znaleźć minimum funkcji, dzięki czemu dostajemy odpowiednie rozwiązanie w naszej sieci. Oczywiście sama w sobie metoda nie jest idealna i może okazać się tak, że nasze minimum funkcji jest minimum lokalnym. Znaczy to tyle, że na wykresie mamy kilka dołków i jeden dołek położony wyżej od siebie jest pewnym minimum funkcji, ale tylko lokalnie, czyli w określonym przedziale. Przykład przedstawię wam poniżej:
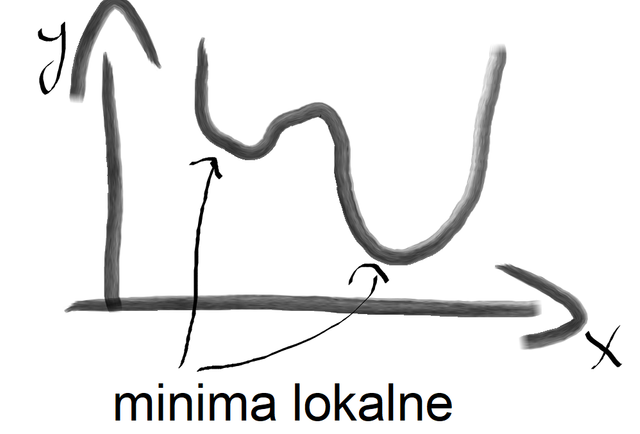
I taki też mniej więcej przykład przedstawię wam w kodzie programu napisanym w c++.
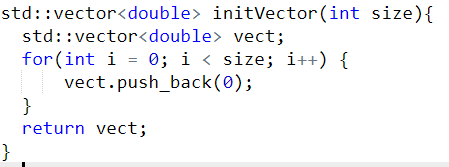
Najpierw wypada stworzyć funkcję, co nam będzie generowała pusty wektor
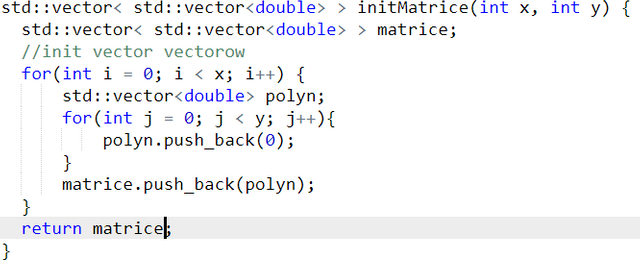
Przyda nam się także jakaś reprezentacja macierzy czy tam tablicy dwuwymiarowej
Teraz podam wam jaką funkcję wykorzystamy, do poszukania minimum globalnego i lokalnego funkcji
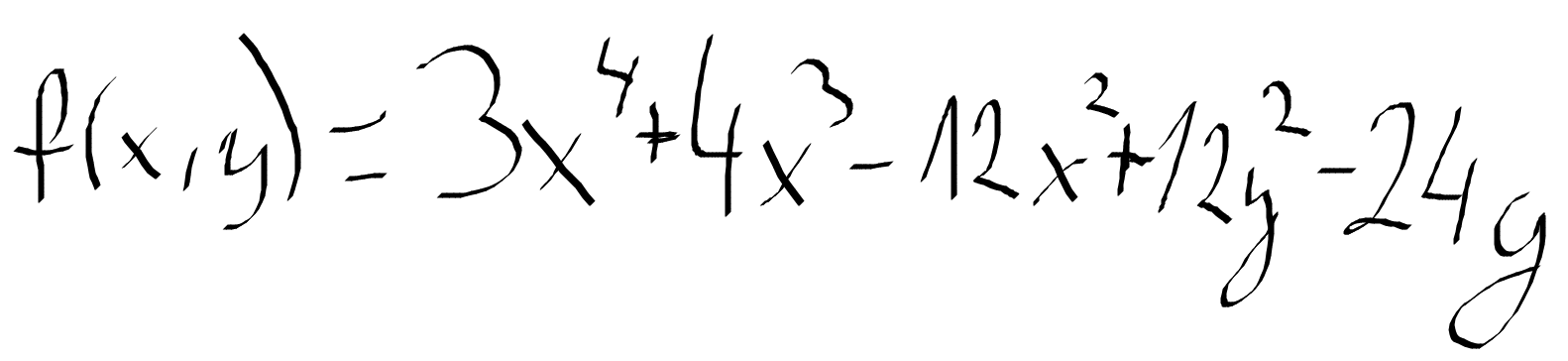
Zapiszę teraz powyższy wzór w kodzie, dzięki czemu będziemy mogli uzyskać odpowiednią wartość funkcji dla zadanych x i y

Następna rzecz, która jest nam potrzebna, to pochodne cząstkowe funkcji f(x,y). W tym przypadku możemy obliczyć je ręcznie dla tego przykładu względem x i względem y tak jak przedstawione to jest poniżej. Najpierw obliczona pochodna cząstkowa względem zmiennej x
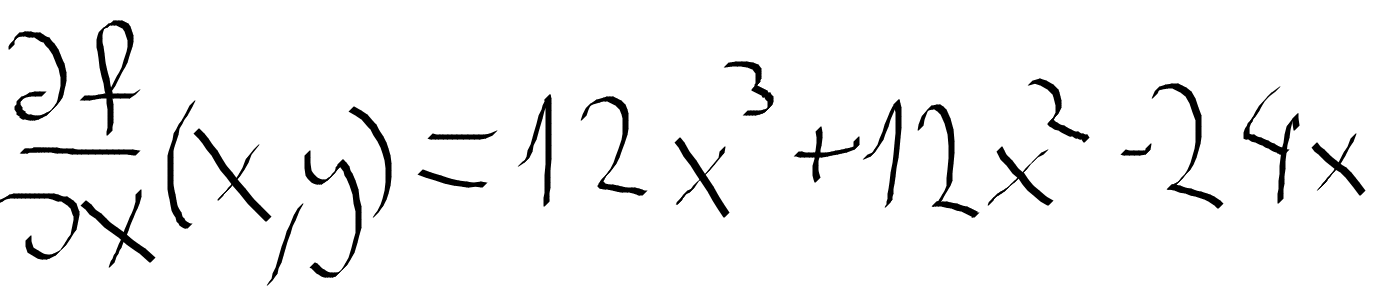
A teraz pochodna cząstkowa względem zmiennej y
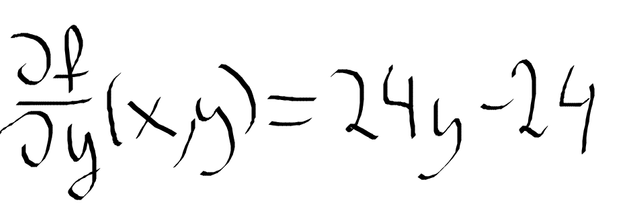
W obliczaniu pochodnych cząstkowych tego typu nie ma żadnej filozofii, trzeba uznawać zmienne jako stałe i wykonywać operacje jak przy obliczaniu zwykłych pochodnych.
Pochodne cząstkowe wykorzystane zostaną w obliczaniu gradientu. Przedstawię teraz moją reprezentację pochodnych w kodzie i funkcję obliczającą gradient
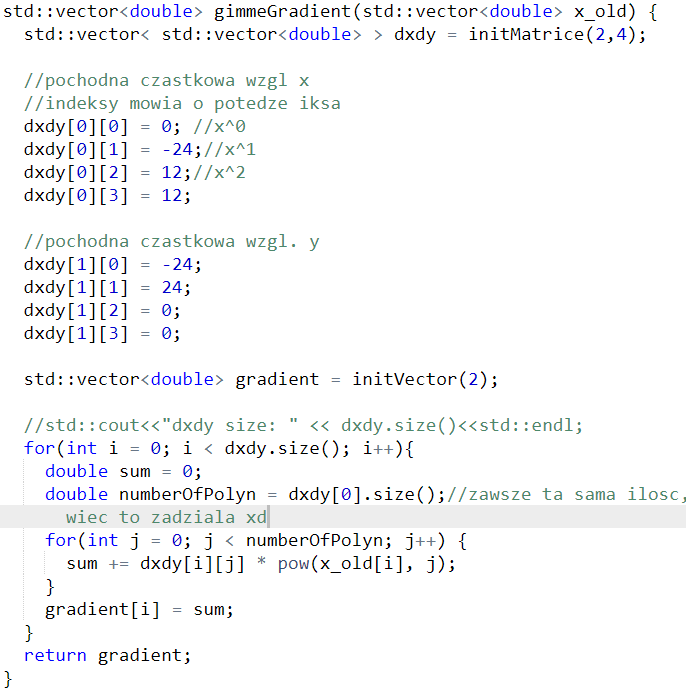
Generalnie w naszym przypadku gradient to dwie liczby, czyli tyle ile naszych zmiennych. Nie będę się wgłębiał w we wzór, ale jak widać z kodu, że brana jest jakaś wartość początkowa, która może być w miarę losowa na początku.
Następna funkcja to obliczenie nowych spółrzędnych, które prowadzą nas do minimum

Zmienna c określa o ile mamy przechodzić po wykresie.
Po obliczeniu kroku, będziemy potrzebowali funkcji na obliczenie normy, która będzie decydowała o wystarczającej dokładności obliczeń i wygląda ona tak

I teraz po sklejeniu tego w klasie main, powinniśmy mieć coś takiego:

Jak widać w powyższym kodzie, epsilon służy jako określenie jaka ma być dokładność, potem mamy wybranie losowych współrzędnych, a na końcu obliczamy nowe współrzędne i robione to jest tak długo, aż nie otrzymamy jakiegoś minimum lokalnego.
Dzięki temu, że losujemy współrzędne, mamy pewność, że w końcu trafimy na minimum globalne funkcji. Metodę gradientu wykorzystywana jest w propagacji wstecznej "back propagation", która wykorzystywana jest w sieciach neuronowych.
Możliwe minima wyżej przedstawionej funkcji to -17 albo -44. Wszystko zależy czy trafimy na lokalne minimum czy globalne minimum.
źródło zdjęcia:https://commons.wikimedia.org/wiki/File:Gradient2.svg
Aż mnie natchnales do napisania posta poszukiwania minimum funkcji za pomocą sztucznej inteligencji 😉
W tym przypadku sztuczna inteligencja potrzebuje minimum funkcji do propagacji wstecznej, żeby minimalizować błąd. A to jest takie wprowadzenie do tego co będzie potem potrzebne.