Inside Machine Translation: is the Language Barrier Broken?

image source
English is not my native language, but like many other users I write all my articles on it. Not only because of the opportunity to "cut the cake", but to improve proficiency in this language.
Before Steemit I've read many books, technical literature, independently, resorting to the translator only as a dictionary. But to read and understand in a foreign language that's not the same as write and communicate on it, sometimes it is impossible to do without machine translation. Not to say that this is an insurmountable problem, but it takes a lot of time.
For example, one article takes me at least 4-6 hours, sometimes more if I write on complex subjects (for this one I have spent about 10 hours). First I read the sources in both languages English and my native, then I write my own material in Russian, after it I translate it into English using my brain, two interpreters and a few dictionaries.
I know English just enough to understand when the translator has processed a text incorrectly. When I don't know how to make it right, I check it manually through searching for analogues of the sentences among the English-speaking sites, watch how native speakers build similar sentences, in blogs, in books, in social networks. At first I tried to write articles directly in English, but paid attention that they are too scarce, words often repeated, all sentences are simple and the text looks too poor, because I don't have enough vocabulary.
I think many non-English users do the same. They write in English, and spend a lot of time on their articles too, continuing to improve their skills. Others get tired of such loads, in addition that you have to come up with an interesting subject for writing and competently express your thoughts through text, moreover you need to translate it in a foreign language. So, people who want only money, think that it's not worth it and leave platform. And many people are afraid to try, because they are don't confident in their knowledge, they don't want to wait when their language-area on Steemit will grow.
The language barrier has always been a serious obstacle to the growth of ideas.

image source
The majority of those who don't give up, solve these tasks with Google Translator, and they have noticed how many mistakes it makes when working with different language pairs. This is often even confusing, you begin to doubt, even in poor but faithful knowledges that you have.
This tool (GT) can help to reader understand the overall meaning of the content of the text in a foreign language, it doesn't provide accurate translations. In fact it works well in one direction only: if you translate text from another language into your native, in the reverse translation, it makes you sweat. So, let's see how it worked, and how neural network changed it.
How did it work?
The old functionality was based on a static machine translation (SMT), namely on the Phrase-based machine translation (PBMT). In simple words, it was a huge dictionary of different language-pairs containing phrases, collocations, turns of phrase.

image source
When you request, the translator begins to look for similar sequences of words in millions of sources that have been translated by humans before. Its working principle can be divide into three components: the collection of statistical data, creation of models and decoding.
- data collection is the comparison of parallel texts in language pairs (again from sources translated by people).
- based on this information, the machine creates models- forms of translation that occur frequently and are basic, usually these models do not contain more than 3-4 words running together, it also creates a simple model of grammar for different language pairs.
- and finally decoding: When you request translation, decoder selects the most likely variant of all collected models, checks it (variant) in all models of language and as a result gives you the proven, statistically the best option.
That’s why Google translator often loses or omits prepositions, which in fact have a rather strong semantic impact in many languages. In the reverse translation onto English it puts the wrong articles. The more models in the database, the more accurate translation you will get. But you have to sacrifice a number of models to support the translation speed, therefore, the translator in most issues gives basic variants.
How does it work?
Google's Neural Machine Translation (GNMT) is so called the developers of their new creation. The name implies the work of a new translator based on a neural network with using deep learning. according to the latest tests, the neural network significantly increased the quality of the translation in all language pairs.
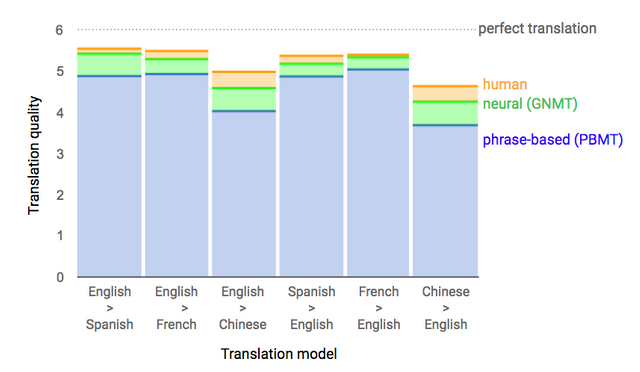
image source
In some sense, the stages of its work are the same as in a static machine translation. But as we know, increasing the accuracy of the translation decreases the speed of the transfer. Therefore, was changed the principle of operation of the encoder and decoder for save speed. Because of this, changed the format in which AI collects statistical data and creates models.
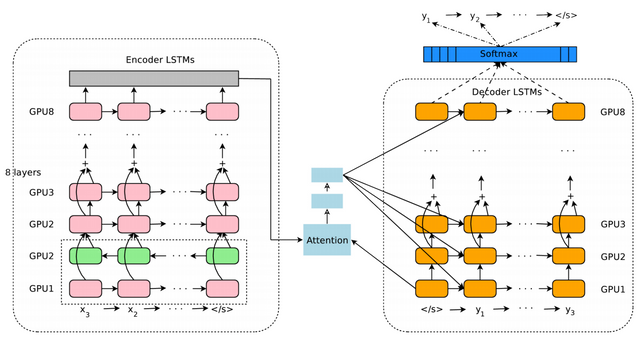
image source
The developers have said that GNMT uses a vector principle, but what it means? It collects statistics on the combined use of words in sentences, then reduces the dimension and gives a compact vector representation of words (which most accurately reflect the meaning of the words).

image source
This approach covers a large number of linguistic patterns. It turns out that linear operations over vectors correspond to semantic transformations. Computing a cosine distance between word vectors, AI can easily find words that are very often met in a similar context, that is a kind of synonyms. But this is true only within texts related by theme which neural network was learned. I.e. the resulting vectors from the fantasy theme will not work correctly in in the text with the culinary theme. The neural network is well able to classify the text with words that are peculiar to only a particular direction. It turns out the larger the piece of text you use for translating (it has more classifying words), the more accurate will translation.
To implement this functionality used deep learning with a high-level architectures of data. In a sense, this approach resembles the work of neural networks in machine vision (when the system processes the image pixel by pixel and gradually increases the level of processing, capturing more complex components). GNMT begins with a single word in combination with the vector, going from simple values to search the semantic content and tone, AI, step by step, chooses the right option, given the weight of each word in the original text.
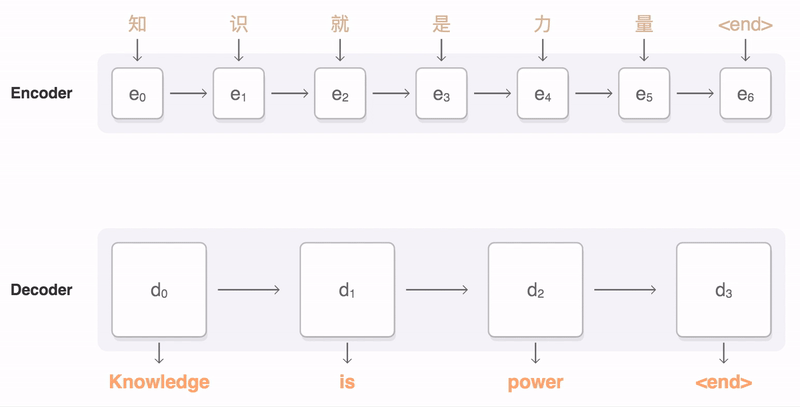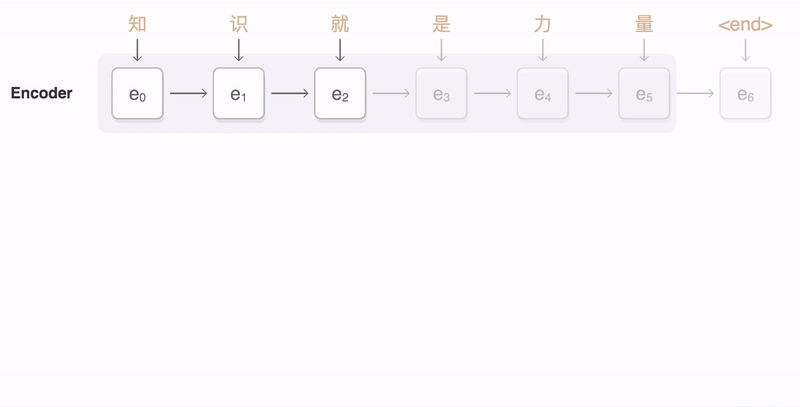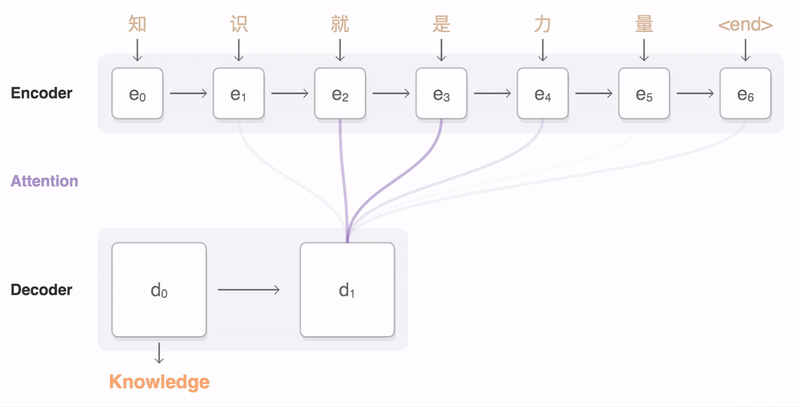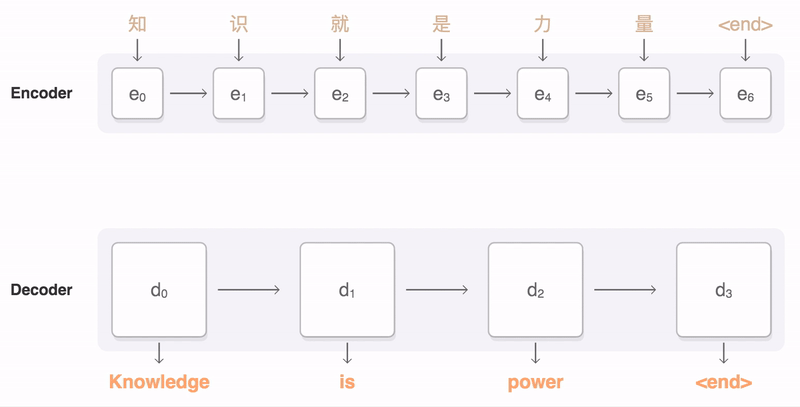
image source
Through this approach, the neural Network performs intelligent analysis of the sentences, breaking them in "dictionary segments" which are correspond to the meanings of words.
The more sources, professionally translated people, system will eat, the less mistakes it will make in the translation. Now it has reduced the number of errors in the work of a pair of English-Chinese 60% (this is the hardest pair to translate) and made a translation as close as possible to the human.

image source
GNMT is already working on many language pairs (but not on mine), and with each day improving. Did you notice that, does it make your work-process easier?
***
Not to mention the benefits of the global using of neural networks and deep learning in machine translation, these changes is a great news for Steemit, I think. Yes, we will see more the usual copy-paste from the lazy users, who don't even want to fix mistakes in translation. On the other hand, the anti-plagiarism bots will be able to identify the same copy-paste more accurately, being connected to Google resources. In General it can provide a large increase in new users, who would like to communicate in English but not confident in their abilities or they do not have enough time. @natord
Follow Me
sources: Deep learning, Statistical machine translation, Google Translate hooked up to the neural network, Natural Language Processing, Word2vec, A Neural Network for Machine Translation
I guess practice is the key. After a few years, you may end up writing directly in English without needing any translation phase anymore!
Btw: excellent post!
You are right, that's why i keep on writing here day by day :)
Great post, and very impressive considering English is not your first language. I wish my vote was worth more!
Thank you! I'm very flattered!:)