구글시트 강좌5 IMPORTXML로 하는 더 파워풀한 웹크롤링
2018년에도 구글 시트 강좌와 함께하는 @youngbinlee 빈누입니다.
구글시트 강좌1 IMPORTHTML로 한방에 하는 웹페이지 크롤링
구글시트 강좌2 CONCATENATE 함수로 원하는 웹페이지 주소 만들기
구글시트 강좌3 VLOOKUP 함수와 드롭다운으로 선택메뉴 만들기
구글시트 강좌4 엑셀보다 편하게 함수로 데이터 나누기 SPLIT과 JOIN
과거 강좌를 차례대로 진행하시는 것이 좋습니다.
구글 시트란?
구글 시트는 구글에서 제공하는 스프레드시트 프로그램입니다. 마이크로 소프트 엑셀과 거의 동일하지만, 클라우드 상에 파일이 존재하여, 여러 기기에서 접근하거나, 여러 사람이 동시에 수정을 하는 등 엑셀보다 편리한 점이 많이 있습니다.
기존의 엑셀 함수는 대부분 사용이 가능하고, 구글 시트에서만 작동하는 유용한 함수들도 많이 있습니다. 구글 시트를 익혀서 여러분의 생산성을 올려보세요! :) 구글 드라이브 바로가기
오늘의 함수 IMPORTXML
오늘의 함수는 IMPORTHTML보다 더 파워풀한 웹 크롤링이 가능한 IMPORTXML 함수입니다. IMPORTHTML이 표나 목록 형식으로 되어있는 데이터만 가져올 수 있는데에 반해, IMPORTXML 함수는 웹페이지에 있는 다양한 형식의 데이터를 다 가져올 수 있다는 장점이 있습니다. 다만, IMPORTHTML에 비해서 설정값이 조금 더 복잡하기는 하지만요.
함수사용법
IMPORTXML(URL, xpath_검색어)
- URL - 검토할 페이지의 URL이며 프로토콜(예: http://)을 포함합니다.
- xpath_검색어 - 구조화된 데이터에서 실행되는 XPath 검색어입니다.
뭔가 어려워 보이는 용어의 등장입니다! XPath? 그게 뭘까요?
XPath란 XML Path Language를 의미합니다. XPath는 XML 문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어.
간단하게 이야기하자면 웹페이지 HTML문서를 포함한 각종 XML문서에서 어떤 요소(예를 들면 표나 링크, 이미지 등)의 '경로' 혹은 '위치'를 지정하는 언어입니다. 이 언어를 사용함으로써 내가 원하는 데이터가 있는 위치를 지정해서, 스프레드시트로 끌어올 수가 있는 것이죠.
글로만 읽어서는 이해가 쉽지 않기도 합니다. 실제 활용예를 한번 보실까요?
활용예
스팀 가격 페이지를 열어봅니다. 오! 하루 사이에 스팀 가격이 천정부지로 솟았네요;;;
이 웹페이지에서 스팀 가격에 해당하는 요소를 가져오기 위해서 다음과 같은 스텝이 필요합니다. (크롬 브라우저를 사용해주세요!)
가격 정보 위에서 마우스 우클릭을 한 뒤 '검사(Ctrl+Shift+I)'를 클릭합니다.
이렇게 웹페이지의 코드 중에서 해당 위치에 해당하는 코드 부분이 하이라이트 되어 나타납니다. 해당 부분에서 마우스 우클릭 후 Copy >> Copy XPath를 선택합니다.
이제 복사된 XPath를 이용해 IMPORTXML 함수와 함께 사용해주면 됩니다.
xPath 경로에 쌍따옴표가 있으면 스프레드시트에서는 사용이 불가능하므로 쌍따옴표만 그냥 따옴표로 바꿔주시면 됩니다.
xPath를 알아보자
웹페이지에서 특정 요소를 몇개만 가져오면 되는 경우에는 Copy XPath로 가져온 경로로 충분할 수도 있지만, 다양한 데이터를 내가 원하는 만큼 가져오기 위해서는 xPath 자체를 조금 알아두면 도움이 많이 됩니다.
- / 최상위 루트 노드 : 그냥 가장 상위 계층을 뜻하는 것이라고 보면 됩니다.
- ∗ : 모든 노드값 (여기서 노드란 보통 html에서 〈img〉, 〈a〉 등 화살 괄호 안에 쓰이는 것들을 의미합니다.)
- /a/b/c : 루트노드부터 그 자식 노드 a의 자식 노드 b의 자식노드 c를 찾는 경로. 웹페이지나 XML문서에서 아래와 같은 위치를 탐색하게 됩니다.
〈a〉
〈b〉
〈c〉나를 찾으라!〈/c〉
〈/b〉
〈/a〉
- //a : 모든 노드 중 a 노드 모두. 실제로 웹페이지에서 데이터 크롤링을 할때 많이 쓰일 수 있습니다.
a는 HTML 문서에서는 '링크'를 거는 역할을 하므로, xPath에 "//a"를 사용하면 '링크가 걸려있는 텍스트는 몽땅'이라는 의미가 되어, 링크가 걸린 텍스트는 이렇게 다 긁어오게 됩니다.
- a/@b : a노드에 b라는 속성을 찾는다. 〈a b='1234'〉 라고 생긴 노드라면 '1234'라는 값을 반환하게 됨. 웹페이지에서 가장 빈번하게 사용되는 요소는 **a/@href ** 웹페이지에서 링크를 걸때 다음과 같은 형식의 명령어가 사용되므로, 실제 링크 주소를 찾아올때는 a/@href 를 사용하게 됩니다.
〈a href="http://naver.com"〉 네이버 바로가기 〈/a〉
//a만 사용했을때는 링크가 걸린 텍스트를 불러온 것과 달리, //a/@href를 사용했을때는 그 텍스트에 걸린 링크 주소를 불러옵니다.
- a[@b='c'] : a노드에 b라는 속성에 c라는 값이 설정되어있는 위치를 찾음.
〈a b='a'〉나는 속성값이 a다!〈/a〉
〈a b='b'〉나는 속성값이 b다!〈/a〉
〈a b='c'〉나를 찾으라!〈/a〉
이것이 자주 사용될때는 웹페이지에서 특정 class나 id로 지정되어있는 요소를 찾을때입니다.
예를 들어 위 웹페이지에서 좌측에 여러가지 웹사이트나 메세지 보드의 링크가 있는 부분이 div 태그로 감싸져 있는 것을 볼 수 있는데요. 여기에 class이름이 "col-sm-4 col-sm-pull-8"라고 지정되어있죠? 이것만 따로 떼어내서 이 부분의 링크만 불러올 수가 있을까요?
요렇게 앞에 붙여주면 전체 웹페이지에서 링크를 끌어오는 것이 아니라, 앞서 지정한 위치에 포함되는 링크만(!) 불러오게 됩니다. 브라보! ^ㅁ^/
숙제
IMPORTXML 함수는 사실 사용하기가 간단한 함수는 아닙니다. 아마 부딪혀 보시면서 익히시는게 가장 빠른 길이 아닐까 생각합니다. 오늘은 간단한 숙제 1개와 조금은 덜 간단한(;) 함수 1개 이렇게 2개를 내보겠습니다.
간단한 숙제
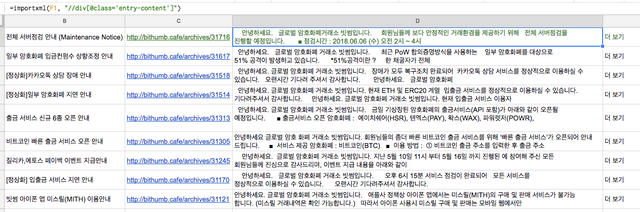
빗썸 공지사항 페이지에서 공지사항 제목을 불러와봅시다. (힌트 : 제목은 h3 태그로 되어있음)
덜 간단한 숙제
빗썸 공지사항 페이지에서 제목, 글 링크, 글 요약 내용 등을 불러와보세요!
으허엉.. 아무리 해도 안 돼요.. ㅠㅠ
우선 제목만 가져오는 것 xPath를 "//h3" 요렇게 써보세요! :)
비스무리 하게 하긴 했는데 내용은 "회원가입", "로그인" 이것도 딸려오네요. ㅠㅠ 팁 주셔서 감사합니다! : )
숙제5
처음보는거라 어려워보이긴한데.. 익히면 엄청 유용하겠네요
자세한 설명 감사합니다.
와.. 엄청 어렵긴 한데.. 일반적인 html 웹크롤링보단 훨씬 유용하겠네요.
참고할게요~ 좋은 글 감사합니다!!
어려울거 같은데 자세한 설명 감사합니다~~~^^ 참고 하겠습니다
조만간 도전해봐야겠습니다 감사해요!
이리저리 테스트 해보다 성공했어요 ^^ 좋은 강좌 진행 감사해요 ~