6-8 RNN Batch Data Training
RNN 코딩에서 hidden_size, sequence_length 및 batch_size 파라메터를 사용하여 복수 개의 데이터로 이루어진 알파벳 데이타를 입력해 보도록 하자. 이와 같이 간단한 문자 sequence로 부터 해 볼 수 있는 RNN은 위와 같이 많은 응용 분야를 가지고 있다.
hidden_size = 5에서 뉴럴 네트워크의 출력 수 설정은 사용자가 정하는 것이다. 만약 이 예제에서 cell의 출력을 단어장(vocabulary, voc)의 one hot code 로 처리하기로 가정하자. sequence_length = 6 은 6개의 cell 들이 펼쳐진 상태에서 연결이 되어 있으면 각 셀별로 one hot coding 된 문자를 하나씩 cell 에 입력 시키도록 한다. 아울러 입력해야 할 데이터가 1세트라고 가정하면 batch_size = 1 로 설정하도록 하자.
물론 RNN 입력 작업을 위해서는 문자 단어장(vocabulary, voc)이 준비되어 있어야 하며 각 문자별로 숫자를 class로 부여해 두면 편리하다. 즉 class를 나타내는 숫자를 사용하여 one hot code 처리하면 거의 준비가 되는 셈이다.
여기서는 유튜브 인기 인강인 sung kim의 “ML lab12-2: RNN - Hi Hello Training” 편의 7글자 “hihello“ 입력 예제를 이용해 보자. RNN은 해보면 알겠지만 cell을 구성하는 뉴럴 네트워크 알고리듬을 직접 건드릴 필요는 전혀 없으며 우리가 이해하고 있는 뉴럴 레이어가 cell 속에 들어 있다는 점을 잘 이해하고 입출력 데이터 처리 과정을 잘 준비하면 쉽게 결과를 얻을 수 있다.

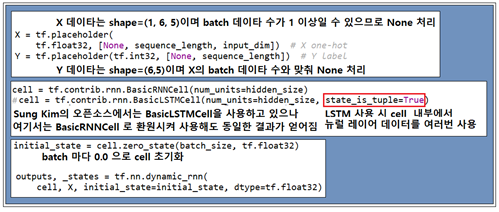
위 그림에서는 shape=( 1, 6, 5 ) 인 입력 데이터 내용을 정리하였다.
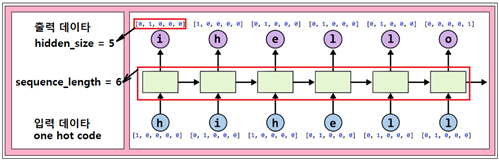
이 데이터를 적용하기 위한 펼친 다음의 RNN 레이아웃을 보기로 한다. 각 cell 에 대한 입력 데이터가 ‘hihell’ 인 반면에 다음 cell 에의 입력 데이터인 ‘ihello’가 출력으로 설정되고 있다.
이와 같이 다음 cell 의 입력 데이터를 하나씩 당겨 출력으로 설정하는 이유는 무엇일까? 바로 이 부분이 RNN 의 핵심인 듯하다. 그 의미를 이해하기 위해서는 Yahoo 사이트에서 일단 한번 ‘hihello’ 로 학습을 시켜 보자. 학습을 시킨다는 의미는 검색 창에 ‘hihello’를 입력 후 엔터키를 누르는 과정까지 이다. 학습을 시킨 후 한 글자씩 입력하면서 Yahoo 검색창의 예측 능력을 시험해 보자. 5글자 입력 상태에서 조금 전에 학습시켰던 효과로 인해 ‘hi hello’를 볼 수 있다.

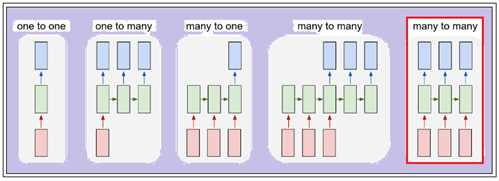
RNN의 응용 분야를 보면 many to many 예측 모델에 해당하는 것을 알 수 있다. 글을 많이 작성하는 작가라면 검색어의 빈도수가 검색 창 학습에 중요한 역할을 한다는 점을 알 수 있을 것이다.
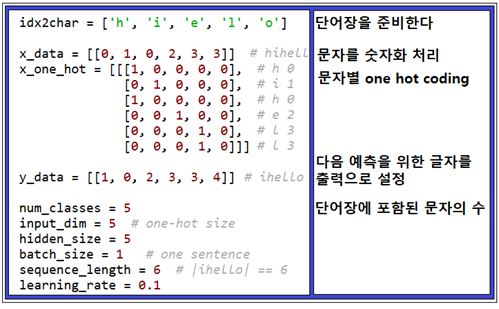
Sung Kim의 오픈소스 lab-12-1-hello-rnn.py code의 구조를 살펴보자. 아나콘다에서 실행이 잘되는 코드이긴하나 2회 연속 실행하면 에러가 발생하는데 그 원인은 Computational Graph()를 완전히 클린해 줄 필요가 있으므로 헤더 영역에 반드시 tf.reset_default_graph()를 넣어 두도록 한다.
아래는 코드 초반부에 설정해야 할 파라메터 값들이 정리 되어 있다.
파라메터 설정에 이어서 Session에서 사용할 학습용 데이터 X 와 Y 를 placeholder 로 준비한다. 첨부된 예제 코드에서는 실제로 batch_size = 1 이지만 차후에 batch_size 수가 커질 경우에 대비해서 None 으로 처리해 둔다.
cell 은 Sung Kim 의 오픈소스에서는 BasicLSTMCell 처리가 되어 있었으나 아직 LSTM을 제대로 이해하지 못한 상태이므로 가장 간단한 BasicRNNCell 로 환원시켰으며 실행결과는 동일하게 얻어졌다. 만약 LSTM을 사용할 경우에는 state_is_tuple=True 처리를 해야 하는데 LSTM cell 하나의 구조만 들여다 보아도 무려 4개의 처리 루틴 과정들이 연결되어 있어 cell 데이터 공유 여부 및 이전 여부에 영향을 미치는 것으로 보인다. 별도로 차후에 LSTM 에 관한 검토를 해 볼 계획이니 참조하도록 하자. 아울러 cell 초기화를 위해 initial_state를 준비해 둔다.
dynamic_rnn에서 얻어지는 outputs는 hidden_size 수에 맞춰 sequence_length 값만큼 리스트 형 데이터로 얻어지는데 fully_connected 루틴에 입력하기 위해서는 [sequence_length, hidden_size] 형태의 2차원 리스트 데이터 즉 [-1, hidden_size]를 줄(row) 단위로 뜯어내어 한 줄로 만들어 주는reshaping 작업이 필요하다. CNN에서도 이와 유사한 작업이 필요한데 최종적으로 Softmax 처리를 위해서는 반드시 2차원적 데이터 구조에서 1차원적 데이터 구조로 바꾸어 주어야 한다. 아울러 Softmax 명령을 직접 사용하지 않는 이유는 주어진 입력 데이터가 2차원이므로 fully_connected 라는 명령어로 데이터 변환 및 Softmax 명령 사용을 한방에 처리하기 때문이다.
vocabulary를 참조하면 5개의 문자가 들어 있으므로 num_classes = 5 가 된다. 따라서 num_outputs도 5가되어야 할 것이다. activation_fn 의 default 는 ReLU 함수이지만 None 으로 설정하면 ReLU를 배제하고 linear activation으로 설정된다.
현재 뉴럴 레이어 1개를 사용하고 있으므로 Width = 5, Depth = 1 이다. 학습 속도를 올리려면 적어도 2∼3개의 뉴럴 레이어 Depth를 부여해야 할 것인데 별도의 명령어가 있다는 점에 유의하자. 아울러 뉴럴 레이어 별로 ReLU 처리가 기본이지만 마지막에서는 ReLU 처리가 없으며 Softmax 명령 바로 앞 단계에서 계산된 결과를 그대로 입력하게 된다.
weights 변수의 shape은 [batch_size, sequence_length] 인데 그 값을 각각 1.0으로 두자. weights 값들은 sequence_loss 함수를 계산함에 파라메터로서 사용된다.
이어지는 cost 함수 설정하는 부분의 코드를 살펴보니 CNN(Convolutionary Neural Network)의 난이도 이상으로 보이는 듯하며 쉽게 이해할 수 없지만 그대로 두기로 한다. seq2seq 루틴에 logits를 사용하는 점으로 미루어 보아 Softmax를 사용함에 틀림없다.

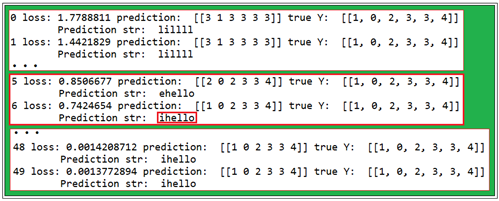
이어서 Session 코드들이 있는데 이 부분에서 출력 결과를 살펴보아야 할 듯하다. 간단한 뉴럴 네트워크 실행 시에도 학습에 따라 cost 함수의 값이 감소하듯이 RNN에서도 sequence_length 길이에 해당하는 class 숫자들의 거동을 살펴보도록 하자. 6번째 학습 단계에서 아직 cost 값이 크긴 하지만 이미 글자 상으로는 충분이 예측이 이루어지고 있음을 알 수 있다.
이 오픈소스 RNN 코드를 체크해 본 바 코드의 복잡성과 난이도가 상당함을 알 수 있었다. 앞으로 LSTM(Long Shor Term Memory) 기법을 검토하면서 RNN 에 대한 이해를 넓혀 갈 계획이다.
첨부된 코드를 다운받아 indentation 이 훼손된지 확인 후 실행해 보자. 이 코드는 유튜브에서 sung kim 으로 검색하여 들어가면 sung kim이 제공하는 모두를 위한 딥러닝 강좌 시즌I에서 안내하는 github 주소에서 다운받을 수 있습니다.
#lab-12-1-hello-rnn.py
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
tf.set_random_seed(777) # reproducibility
idx2char = ['h', 'i', 'e', 'l', 'o']
#Teach hello: hihell -> ihello
x_data = [[0, 1, 0, 2, 3, 3]] # hihell
x_one_hot = [[[1, 0, 0, 0, 0], # h 0
[0, 1, 0, 0, 0], #i 1
[1, 0, 0, 0, 0], #h 0
[0, 0, 1, 0, 0], #e 2
[0, 0, 0, 1, 0], #l 3
[0, 0, 0, 1, 0]]] #l 3
y_data = [[1, 0, 2, 3, 3, 4]] # ihello
num_classes = 5
input_dim = 5 # one-hot size
hidden_size = 5 # output from the LSTM. 5 to directly predict one-hot
batch_size = 1 # one sentence
sequence_length = 6 # |ihello| == 6
learning_rate = 0.1
X = tf.placeholder(
tf.float32, [None, sequence_length, input_dim]) # X one-hot
Y = tf.placeholder(tf.int32, [None, sequence_length]) # Y label
cell = tf.contrib.rnn.BasicRNNCell(num_units=hidden_size)
#cell = tf.contrib.rnn.BasicLSTMCell(num_units=hidden_size, state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32)
outputs, _states = tf.nn.dynamic_rnn(
cell, X, initial_state=initial_state, dtype=tf.float32)
#FC layer
X_for_fc = tf.reshape(outputs, [-1, hidden_size])
outputs = tf.contrib.layers.fully_connected(
inputs=X_for_fc, num_outputs=num_classes, activation_fn=None)
#reshape out for sequence_loss
outputs = tf.reshape(outputs, [batch_size, sequence_length, num_classes])
weights = tf.ones([batch_size, sequence_length])
sequence_loss = tf.contrib.seq2seq.sequence_loss(
logits=outputs, targets=Y, weights=weights)
loss = tf.reduce_mean(sequence_loss)
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
prediction = tf.argmax(outputs, axis=2)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(50):
l, _ = sess.run([loss, train], feed_dict={X: x_one_hot, Y: y_data})
result = sess.run(prediction, feed_dict={X: x_one_hot})
print(i, "loss:", l, "prediction: ", result, "true Y: ", y_data)
# print char using dic
result_str = [idx2char[c] for c in np.squeeze(result)]
print("\tPrediction str: ", ''.join(result_str))
'''
0 loss: 1.71584 prediction: [[2 2 2 3 3 2]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: eeelle
1 loss: 1.56447 prediction: [[3 3 3 3 3 3]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: llllll
2 loss: 1.46284 prediction: [[3 3 3 3 3 3]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: llllll
3 loss: 1.38073 prediction: [[3 3 3 3 3 3]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: llllll
4 loss: 1.30603 prediction: [[3 3 3 3 3 3]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: llllll
5 loss: 1.21498 prediction: [[3 3 3 3 3 3]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: llllll
6 loss: 1.1029 prediction: [[3 0 3 3 3 4]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: lhlllo
7 loss: 0.982386 prediction: [[1 0 3 3 3 4]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: ihlllo
8 loss: 0.871259 prediction: [[1 0 3 3 3 4]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: ihlllo
9 loss: 0.774338 prediction: [[1 0 2 3 3 4]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: ihello
10 loss: 0.676005 prediction: [[1 0 2 3 3 4]] true Y: [[1, 0, 2, 3, 3, 4]]
Prediction str: ihello
...
'''

짱짱맨 호출에 응답하였습니다.