4-7 NN(뉴럴 네트워크)의 Wide Deep Learning
XOR 로직을 처리하기 위해 구성되는 다음의 가장 기본 적인 형태의 NN 에 대해 WIde Deep Learning을 적용해 보자. XOR 로직을 제외한 AND, OR 로직이라든지 또는 선형회귀법을 비롯한 많은 문제들은 쉽게 처리가 되지만 XOR 로직에 한해서는 NN 에 의해서만 처리되기 때문에 항상 XOR 로직이 거론된다.
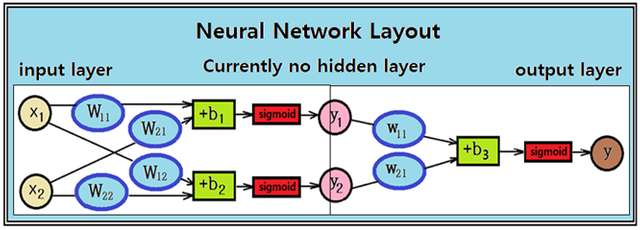
이 예제 문제는 현재 입력 레이어와 출력 레이어로 구성된 가장 기본적인최소 규모의 뉴럴 네트워크 형태를 취하고 있다.
2개의 입력에 대해 4개의 웨이트와 2개의 바이아스를 사용하여 나오는 2개의 출력을 sigmoid 처리하는 기본 적인 NN 구조에 있어서 이 웨이트 와 바이아스 의 수는 최소에 해당한다. 즉 Regression 과정에서 웨이트와 바이아스의 수를 더 이상 줄이는 것은 곤란하지만 반대로 늘이는 것은 제한이 없다. 어차피 학습 시작 초기에 정확한 웨이트 와 바이아스 값을 모르므로 그 수가 늘어난다 해도 문제가 될 것이 없는게 늘어난 규모에 맞춰 적정한 값들을 찾아 주면 될 일이다.
이 NN 문제를 Wide Deep 형태로 바꾸기 위해서는 위 그림의 input layer 와 output layer 사이에 사용자가 임의로 은닉층(hidden layer)을 설정해서 넣어야 한다. 이 NN을 Wide화 한다는 Wide 의 의미는 input layer 로부터 출력 수를 현재 2개에서 필요로 하는 만큼 개수를 늘리는 것이다. 최소 2 이상이면 되며 그 수의 제한이 없으므로 사용자가 편하게 설정하면 되므로 이 예제에서는 은닉층을 2개층 추가하고 각각 입력 데이터를 10개씩 취하기로 하자.
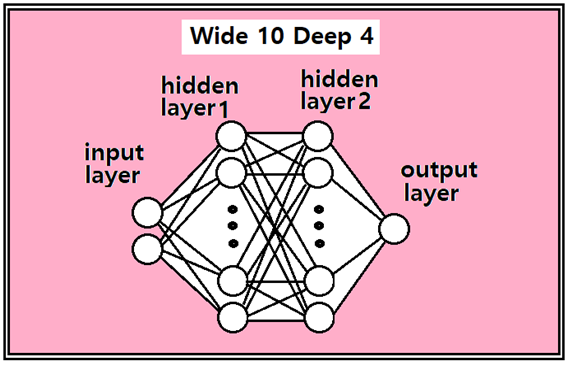
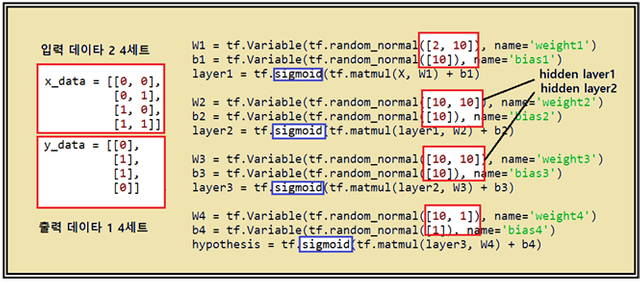
다음의 코드를 참조하면서 즉 2개의 입력 상태에서 input layer의 출력을 10개로 잡게 되면 필요한 웨이트 수는 20개가 되며 바이아스는 10개가 필요하게 된다.
hiden layer1 과 hidden layer2 에서는 각각 10개의 입력을 받아서 10개를 출력하므로 웨이트 10개에 바이아스 10개면 된다.
마지막 ,output layer에서는 10개의 입력에 1개의 출력이므로 10개의 웨이트와 1개의 바이아스면 충분하다.
각 layer 별로 처리할 때에는 반드시 sigmoid layer를 넣어 실제 뉴론에서 처럼 firing 조건을 적용하도록 한다.
learning rate = 0.1, 학습횟수는 10,000회 로 두어 첨부된 파이선 코드를 실행해 보자. XOR 로직 문제 이므로 그 결과는 0.0, 1.0, 1.0, 0.0 이다. 다만 10,000회 이하로 학습횟수가 충분히 못할 경우 실패한 결과를 줄 수도 있으므로 유의하자.
첨부된 파이선 코드를 다운로딩 후 명령이 끝나는 부분에 콜론 “:” 다음에 그 다음 줄을 당겨 붙인 후 다시 엔터 작업을 하면 정확한 indentation 위치를 파악할 수 있다. indentation을 정확히 복구하여 실행해 보도록 하자.
#wide deep for XOR
import tensorflow as tf
import numpy as np
tf.set_random_seed(777) #for reproducibility
learning_rate = 0.1
x_data = [[0, 0],
[0, 1],
[1, 0],
[1, 1]]
y_data = [[0],
[1],
[1],
[0]]
x_data = np.array(x_data, dtype=np.float32)
y_data = np.array(y_data, dtype=np.float32)
X = tf.placeholder(tf.float32, [None, 2])
Y = tf.placeholder(tf.float32, [None, 1])
W1 = tf.Variable(tf.random_normal([2, 10]), name='weight1')
b1 = tf.Variable(tf.random_normal([10]), name='bias1')
layer1 = tf.sigmoid(tf.matmul(X, W1) + b1)
W2 = tf.Variable(tf.random_normal([10, 10]), name='weight2')
b2 = tf.Variable(tf.random_normal([10]), name='bias2')
layer2 = tf.sigmoid(tf.matmul(layer1, W2) + b2)
W3 = tf.Variable(tf.random_normal([10, 10]), name='weight3')
b3 = tf.Variable(tf.random_normal([10]), name='bias3')
layer3 = tf.sigmoid(tf.matmul(layer2, W3) + b3)
W4 = tf.Variable(tf.random_normal([10, 1]), name='weight4')
b4 = tf.Variable(tf.random_normal([1]), name='bias4')
hypothesis = tf.sigmoid(tf.matmul(layer3, W4) + b4)
#cost/loss function
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) *
tf.log(1 - hypothesis))
train = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cost)
#Accuracy computation
#True if hypothesis>0.5 else False
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
#Launch graph
with tf.Session() as sess:
#Initialize TensorFlow variables
sess.run(tf.global_variables_initializer())
for step in range(10001):
sess.run(train, feed_dict={X: x_data, Y: y_data})
if step % 100 == 0:
print(step, sess.run(cost, feed_dict={
X: x_data, Y: y_data}), sess.run([W1, W2]))
#Accuracy report
h, c, a = sess.run([hypothesis, predicted, accuracy],
feed_dict={X: x_data, Y: y_data})
print("\nHypothesis: ", h, "\nCorrect: ", c, "\nAccuracy: ", a)