4-5 Natural language Processing의 소개-II: Term Frequency-Inverse Document Frequency 단어 관련성 분성

텍스트 데이터 분석 시에 class 값이 긍정적이거나 부정적으로 분류가 가능한 여러 문서에서 걸쳐서 빈번하게 나타나는 단어들 중에 이들이 쓸만한 정보 내지는 무언가 뚜렷한 정보를 포함하지 않는 경우들이 왕왕 있을 수 있다. 따라서 특징 벡터에 포함되어 나타나는 이러한 경향을 찾아내어 필터링할 수 있는 중요한 기법으로서 문서 빈도수(Document Frequency) 대비 단어 출현 빈도수(Term Frequency)를 알아보자.

nd는 전체 문서의 수이며 df(t,d)는 단어 t를 포함하고 있는 문서의 수이다. “1+”의 1은 df(t,d) 의 값이 0 일 때 분모의 값이 0 이 되는 것을 방지하기 위한 옵션이다. log 값을 취하는 이유는 단어 t를 포함하고 있는 문서의 수 df(t,d)가 작은 값일 때 분수 값 계산 결과가 너무 커질 수 있으므로 값을 조절하기 위한 수단이다.
scikit-learn 라이브러리 모듈이 제공하는 idf(t,d)에 해당하는 class 명령 TdidfTransformer를 실행해 보자.
3번째 문서에서 ‘is’ 는 가장 큰 단어 빈도수 값을 가짐을 알 수 있다. 하지만 특징 벡터를 tfidf로 변환 후 ‘is’ 란 단어가 3번째 문서에서 상대적으로 작은 tfidf 값 0.45임을 알 수 있다. 그 이유는 첫 번째 와 두 번째 문서에서도 ‘is’가 포함되어 있는 것으로 보아 뭔가 쓸모가 있으면서도 튀는 정보를 제공하지는 않는 것으로 보이기 때문이다.
이미 표준형 idf(t,d)를 정의하였으나 scikit-learm 에서 사용하는 공식은 약간의 차이가 있으며 다음과 같이 보정한다.

3번째 문장에 나타나는 단어들에 대해서 모조리 tfidf를 계산하면 다음과 같이 주어진다.
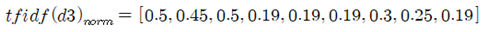
이 데이타에서 두 번째 항이 0.45임을 알 수 있다.
#bag_of_words.py
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
count = CountVectorizer()
docs = np.array([
'The sun is shining',
'The weather is sweet',
'The sun is shining and the weather is sweet, one and one is two'])
bag = count.fit_transform(docs)
print(count.vocabulary_)
print(bag.toarray())
tfidf = TfidfTransformer(use_idf=True, norm='l2', smooth_idf=True)
np.set_printoptions(precision=2)
print(tfidf.fit_transform(count.fit_transform(docs)).toarray())

짱짱맨 호출에 응답하였습니다.