3-2 OR 로직 Softmax 머신 러닝 Classification
입력 벡터를 구성하기 위한 조도센서(Photocell)의 수가 1 과 2인 경우에 대하여 Rosenblatt의 퍼셉트론을 분석해 보았다. Rosenblatt이 제시했던 웨이트 업데이트 방식 알고리듬을 확인해 보았으며 아울러 Softmax를 사용하여 체크를 해보았다.
선형 hypothesis와 최소제곱법에 의한 OR 로직 머신 러닝 Classification 문제에서도 마찬가지로 Softmax를 사용하여 체크해 보기로 하자.
OR 로직 문제는 2개의 입력 센서를 가지는 Rosenblatt의 퍼셉트론에서 2개의 라벨을 “+1”과 “-1”이 아닌 “1”과 “0” 으로 학습하는 경우로 보면 될 것이다. OR 로직 문제는 단순한 수학 문제가 아니라 자동차 도난 경보 장치에서 실제로 사용이 되는 로직이다.

그림에서처럼 이러한 논리(LOGIC) 출력을 바탕으로 하는 OR 논리(LOGIC)를 고려해 보자.
OR 논리에서는 “0” 과 “1”을 사용하여 나타낼 수 있는 입력 값 x1,x2 2개 중의 1개가 “1”이라면 출력 y가 “1” 이 되며 좌표 평면으로 나타낼 수도 있다. 그림의 직각 좌표 평면에서 4개의 입력 값이 표현되어 있다. 이 그림에서 출력 값이 “0”이 되는 1개의 점과 출력 값이 “1”인 3개의 점은 가로지르는 직선에 의해서 명확하게 분류 (classification)될 수 있음을 알 수 있다.
따라서 이 선형 Classifier 왼쪽의 영역은 논리 또는 라벨 값이 “0” 인 영역이며 그 오른 쪽은 “1”인 영역이 된다. 이러한 Classifier를 학습에 의해 찾아낼 수 있도록 다음과 같이 입력벡터 X와 웨이트 백터 W를 정의하자.
X 와 W를 사용하여 다음과 같이 선형의 hypothesis를 설정하자.
hypothesis = X*W + b = x1*w1 + x2*w2 + b
2개의 라벨 영역 “0” 과 “1” 을 구별할 수 있는 Classifier를 찾아내기 위해 학습을 위한 TensorFlow 코드 데이터를 아래와 같이 준비하자. x_data는 OR 테이블 데아타를 그대로 옮기면 되며 y_data의 라벨 값은 “0”인 경우는 [ 1, 0 ], “1”인 경우는 [ 0, 1 ] 로 둔다. learning_rate 값은 0.1 로 설정하고 steps 는 10 만회로 둔다.
x_data = [ [ 0, 0 ], [ 1, 0 ], [ 0, 1 ], [ 1, 1 ] ]
y_data = [ [1, 0], [0, 1], [0, 1],[0, 1] ]
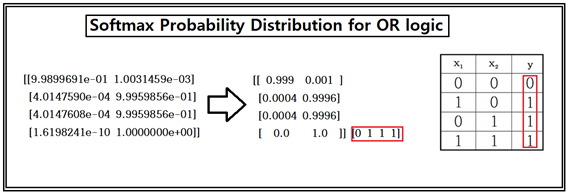
계산 결과 후 학습 데이터를 사용하여 라벨 별로 확률 값을 계산하여 점검해 보자. [0,0]일 경우 0.1% 오차이며 나머지 경우는 거의 0.04%의 오차 범위로 대단히 정확한 계산 결과를 보여준다.
첨부된 파이선 코드를 실행해 보자. 단 session = tf.Session() 이하 영역에서 indentation 이 무너진 부분을 반드시 복구하여 실행하기 바란다.
#softmax_classifier_2data_Rosenblatt_01.py
from matplotlib import pyplot as plt
import numpy as np
import tensorflow as tf
tf.set_random_seed(777) # for reproducibility
def gen_image(arr):
t_d = np.reshape(arr, (3, 3))
two_d = (np.reshape(arr, (3, 3)) * 255).astype(np.uint8)
print(two_d)
plt.imshow(two_d, interpolation='nearest')
plt.savefig('batch.png')
return plt
x_data = [[ 0, 0 ], [ 1, 0], [ 0, 1], [ 1, 1] ]
y_data = [ [1, 0], [0, 1], [0, 1],[0, 1] ]
X = tf.placeholder("float", [None, 2])
Y = tf.placeholder("float", [None, 2])
nb_classes = 2
W = tf.Variable(tf.random_normal([2, nb_classes]), name='weight')
b = tf.Variable(tf.random_normal([nb_classes]), name='bias')
#tf.nn.softmax computes softmax activations
#softmax = exp(logits) / reduce_sum(exp(logits), dim)
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
#Cross entropy cost/loss
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
#Launch graph
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(100001):
sess.run(optimizer, feed_dict={X: x_data, Y: y_data})
if step % 200 == 0:
print(step, sess.run(cost, feed_dict={X: x_data, Y: y_data}))
print('--------------')
#Testing & One-hot encoding
a = sess.run(hypothesis, feed_dict={X: [[ 0.0, 0.0 ]]})
print(a, sess.run(tf.argmax(a, 1)))
print('--------------')
all = sess.run(hypothesis, feed_dict={
X: [[ 0.0, 0.0 ],[ 1.0, 0.0], [ 0.0, 1.0 ], [ 1.0, 1.0 ]]})
print(all, sess.run(tf.argmax(all, 1)))
That's engaging and delightful m8
These are fresh and elegant =)
아직 Payout 되지 않은 관련 글
모든 기간 관련 글
인터레스팀(@interesteem)은 AI기반 관심있는 연관글을 자동으로 추천해 주는 서비스입니다.
#interesteem 태그를 달고 글을 써주세요!
이오스 계정이 없다면 마나마인에서 만든 계정생성툴을 사용해보는건 어떨까요?
https://steemit.com/kr/@virus707/2uepul