3-10 복소수 평면에서의 로지스틱 함수의 Hypothesis 추출
로지스틱 함수에 복소수 z를 적용할 때에 binary classification을 위한 학습이 가능한지 알아보자. 수학적인 함수의 모양은 로지스틱 함수 그대로지만 복소수 z = x+iy를 대입하게 되면 함수 전체가 복소수 함수가 된다.

분모를 실수 화 하도록 하자. 아래 공식에서 y = 0 라면 정확하게 Sigmoid 함수가 됨을 알 수 있다.
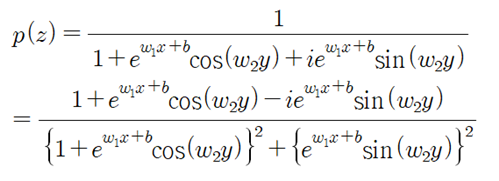
실수부를 관찰해 보면 y에 관한 우함수인 반면에 허수부는 기함수이다. 한편 실수부와 허수부를 선형 결합하여 일반적인 함수 형태로 볼 수 있는 Hypothesis를 구성하도록 하자.
실수부와 허수부로 이루어진 p(z)를 사용하여 아래와 같이 Hypothesis를 선택하여 시험해 보기로 한다.
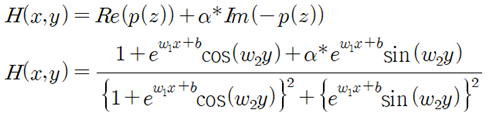
α=0 일 때 즉 실수부만 Hypothesis로 두어 AND 논리 문제를 풀어보기로 한다.
learning rate = 0.1 로 두고 학습횟수는 5000회 로 두자.
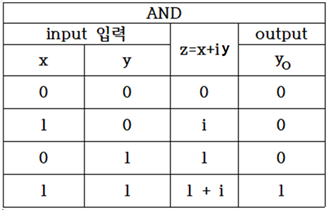
Logistic Regression 의 cost 함수는 Sigmoid 함수를 사용하지만 현재 복소수 기법 적용에서는 TensorFlow에서 제공하는 함수가 없기 때문에 아래와 같이 직접 코딩하도록 하자.

Hypothesis 계산 결과 값이 어느 정도 수렴하는 편이지만 (1, 0)에 해당하는 두 번째 항이 0.0에 수렴해야 하나 상대적으로 느리게 수렴하는데 class를 판별하는데 문제는 없다.
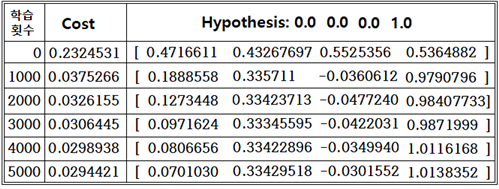
alpha 값을 입력하여 계산해 본 결과 alpha 값이 클 때에 학습 결과가 좋게 나타났다. 따라서 아예 허수부에 해당하는 부분만 Hypothesis 로 택하여 계산해 보기로 하자.

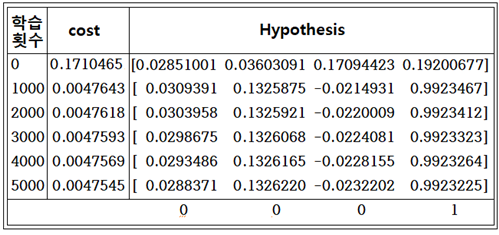
같은 학습 횟수 조건 하에서 실수부를 사용했을 때 보다 훨씬 근접한 결과를 주고 있다.
파이선 코드 다운 로드 시에 Session 부분의 indentation 훼손 여부를 반드시 확인 후 수정하여 실행해 보기 바란다.
#complex_variable_logistic_reg_And_01.py
import tensorflow as tf
tf.set_random_seed(777) # for reproducibility
x1_data = [0., 1., 0., 1.]
x2_data = [0., 0., 1., 1.]
y_data = [0., 0., 0., 1.]
#placeholders for a tensor that will be always fed.
x1 = tf.placeholder(tf.float32)
x2 = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
w1 = tf.Variable(tf.random_normal([1]), name='weight1')
w2 = tf.Variable(tf.random_normal([1]), name='weight2')
b1 = tf.Variable(tf.random_normal([1]), name='bias1')
#hypothesis = x1 * w1 - x2 * w2 + b1
s = tf.sin(w2x2, name=None)
c = tf.cos(w2x2, name=None)
ew = tf.exp(w1*x1+b1)
alpha = 1.0
#hypothesis = (1 + ew * (c + alpha * s))/(tf.square(1+(ew * c)) + tf.square(1 + (ew * s)))
#hypothesis = (1 + ew * c)/(tf.square(1+(ew * c)) + tf.square(1 + (ew * s)))
hypothesis = (1 + ew * s)/(tf.square(1+(ew * c)) + tf.square(1 + (ew * s)))
#cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y) )
#Minimize. Need a very small learning rate for this data set
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
train = optimizer.minimize(cost)
#Launch the graph in a session.
sess = tf.Session()
#Initializes global variables in the graph.
sess.run(tf.global_variables_initializer())
for step in range(5001):
cost_val, hy_val,w1_val, w2_val, b1_val, _ = sess.run([cost, hypothesis, w1, w2, b1, train],
feed_dict={x1: x1_data, x2: x2_data, Y: y_data})
if step % 1000 == 0:
print(step, cost_val, hy_val, w1_val, w2_val, b1_val)