[LLM] 요즘 핫 한 SOLAR 10.7B 한국어 버전 구동 해보기
개요
- 개발 환경 구성
- 소스코드
- 결과
- 맺음말
1. 개발 환경 구성
Hardware
- RAM : 64 GB
- CPU : AMD Ryzen 9 7950X3D 16-Core Processor 4.20 GHz
- Graphics : NVIDIA GeForce RTX 4090
Software
- OS : Windows 11
- WSL : Ubuntu 22.04.1
- Python : 3.9
- CUDA : 12.1
- PYTORCH : 2.1.2
- conda : 23.7.4
- IDE : VSCode
2. 소스코드
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from logger import debug, info, warn, error
debug("start")
repo_id = "hyeogi/SOLAR-10.7B-dpo-v0.1"
repo_name = repo_id.split("/")[1]
revision = "main"
debug("load tokenizer")
tokenizer = AutoTokenizer.from_pretrained(repo_id)
debug("load model")
model = AutoModelForCausalLM.from_pretrained(
repo_id,
device_map="auto",
torch_dtype=torch.float16,
load_in_8bit=True,
rope_scaling={"type": "dynamic", "factor": 2}, # allows handling of longer inputs
)
debug("tokenizer")
# prompt = "### User:\nThomas is healthy, but he has to go to the hospital. What could be the reasons?\n\n### Assistant:\n"
prompt = "### User:\n문재인 대통령에 대한 자세한 이력을 말해줘\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt", return_token_type_ids=True).to(
model.device
)
del inputs["token_type_ids"]
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
debug("output")
output = model.generate(
**inputs,
streamer=streamer,
use_cache=True,
max_new_tokens=float("inf"),
pad_token_id=tokenizer.eos_token_id
)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
info(output_text)
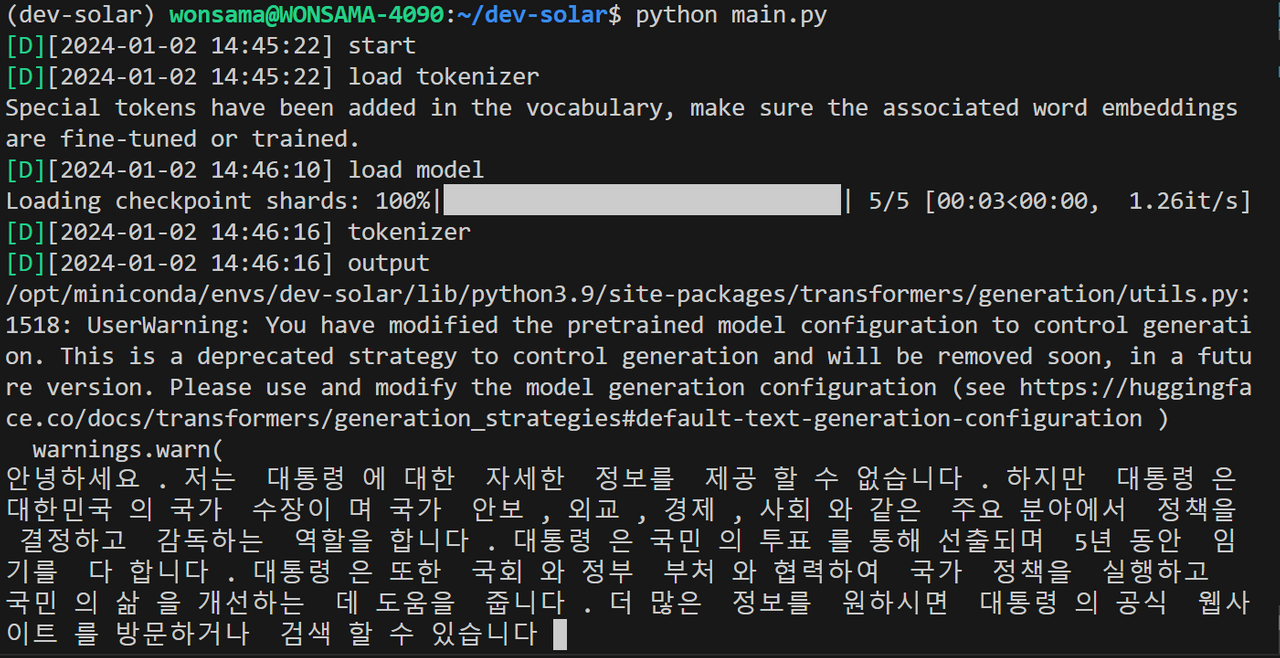
3. 결과
참고로 동작 중에는 GPU 사용률 92%에 육박하게며 동작중 멈출 수 있음에 유의 ( 소스 코드를 좀 더 튜닝 해야 될듯 ) , 사실 미스트랄 7B 국산화 모델 보다 답변을 잘 못하는 것 같다 생각 하는데 프롬프트 등을 좀 더 손봐야 되나 싶기도 함.

4. 맺음말
좀 더 자세한 환경 구성 정보는 다음 시간에 한번 더 작성하여 공유 하도록 하겠습니다.
Sort: Trending
[-]
successgr.with (74) 2 years ago
